







上一步中开发的信用风险评分卡模型,得到的是不同风险等级客户对应的分数,我们还需要将分数与违约概率和评级符号联系起来,以便差异化管理证券公司各面临信用风险敞口的客户,这就需要对证券公司各面临信用风险敞口业务中的个人客户开发一个一致的主标尺。最容易理解、最容易操作的方式就是根据违约概率从低到高分为不同的区间,这就相当于把违约概率这把尺子标上刻度,用这把尺子可以把证券公司需承担信用风险敞口的不同业务中的个人客户划分到不同的信用等级,这样各项业务中个人客户的信用等级分布差异、信用风险分布高低,就可以一目了然地展现出来了。这种违约概率和信用等级之间的映射关系就称为主尺标。
由逻辑回归方程原理的分析可知,客户的违约概率p=Odds/(1+Odds),由式
Score=A-Blog(Odds)中得分与违约概率和Odds之间的对应关系,我们可计算出客户得分对应的违约概率。
由信用风险标准评分卡可知,该评分卡的最高分是89分,最低分是-41分。因此,我们可以计算出该评分卡所有得分范围对应的违约概率:

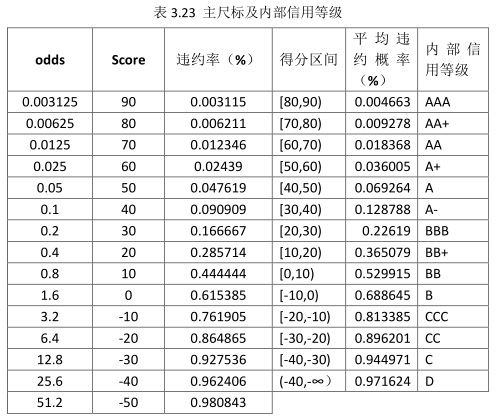
根据表3.22的结果可见,我们可简单地将每10分对应一个信用等级,并用每相邻得分对应的违约概率(这种方法计算得出的违约概率只能用作风险排序,而不是客户的真实违约概率)的算术平均值作为该信用风险等级对应的平均违约概率,得到最终的主尺标及其内部信用等级对照表3.23:
在主标尺和内部信用等级确定后,接下来我们需要进行模型的区分能力、预测准确度和稳定性等模型的验证工作了。回顾模型开发的过程,在模型开发时我们采用随机抽样的方法将数据分为样本集和测试集,并用样本集开发模型,用测试集做模型验证。因此,做模型验证时,我们应当首先用开发好的模型对测试集中的每一个样本评级一遍,并根据评级结果来计算模型的区分能力和预测准确度。
用已开发好的模型对测试集中所有样本重新评级一遍的代码如下:
tmp1<-test_kfolddata[,-21]
credit_risk1<-ifelse(test_kfolddata[,"credit_risk"]=="good",0,1)
data_tmp<-as.matrix(cbind(tmp1,credit_risk1))
##降维purpose(对测试集中的样本做同样的降维处理)##
for(i in 1:nrow(data_tmp))
{
#合并car(new)、car(used)
if(as.character(data_tmp[i,"purpose"])=="car (new)")
{
data_tmp[i,"purpose"]<-as.character("car(new/used)")
}
if(as.character(data_tmp[i,"purpose"])=="car (used)")
{
data_tmp[i,"purpose"]<-as.character("car(new/used)")
}
#合并radio/television、furniture/equipment
if(as.character(data_tmp[i,"purpose"])=="radio/television")
{
data_tmp[i,"purpose"]<-as.character("radio/television/furniture/equipment")
}
if(as.character(data_tmp[i,"purpose"])=="furniture/equipment")
{
data_tm 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 428
428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









