







1、需求决定引擎选型
根据马斯洛需求层次理论,可以将流处理引擎的需求分为以下几种层次:
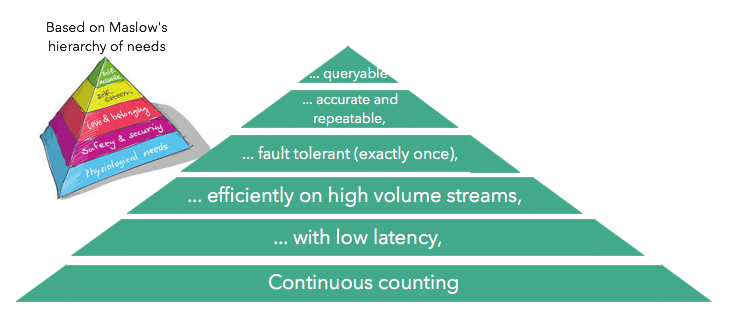
1、持续性的流处理
2、低延迟的计算结果,亚秒级别的延迟
3、高效可扩展性,每秒百万级的吞吐量
4、容错性,即失败时的可恢复性
5、精确的可重复性
6、可查询性
流处理就是在延迟、吞吐量和正确性之间做一个平衡。
2、当前的流处理引擎包含哪些

1、Spark Streaming
2、Storm
3、Flink
4、samza
。。。。
3、根据Maslow模型,在不同流处理系统之间做个简单的横向对比
1、连续不断的处理

都具有处理“流”的能力。
2、低延迟

Spark Streaming本质是个“micro-batch”,延迟达到秒级。
如果对“延迟性”要求很高,Spark Streaming不适合。
3、高吞吐高扩展
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1129
1129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









