









 文章描述了一个Python脚本,该脚本用于处理Excel表格数据。它从两个表中获取信息——表A包含邮寄地址和单号,表B包含运单号和重量。脚本在表A中添加了重量和运费列,通过查询表B获取重量,并根据邮寄地址和重量计算运费。此外,还处理了空单号的情况,以及在价格表中找不到对应地区的错误。在处理过程中,脚本会在命令行中输出找不到重量信息的订单号和计算错误。最后,根据提示,用户需要手动折叠Excel中单号为空的行。
文章描述了一个Python脚本,该脚本用于处理Excel表格数据。它从两个表中获取信息——表A包含邮寄地址和单号,表B包含运单号和重量。脚本在表A中添加了重量和运费列,通过查询表B获取重量,并根据邮寄地址和重量计算运费。此外,还处理了空单号的情况,以及在价格表中找不到对应地区的错误。在处理过程中,脚本会在命令行中输出找不到重量信息的订单号和计算错误。最后,根据提示,用户需要手动折叠Excel中单号为空的行。
问题背景
有表A,其数据如下
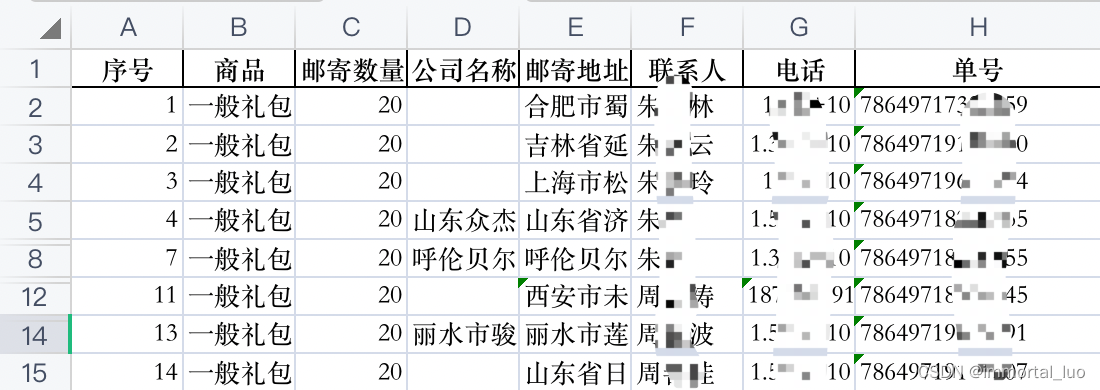
关键信息是邮寄地址和单号。
表B:
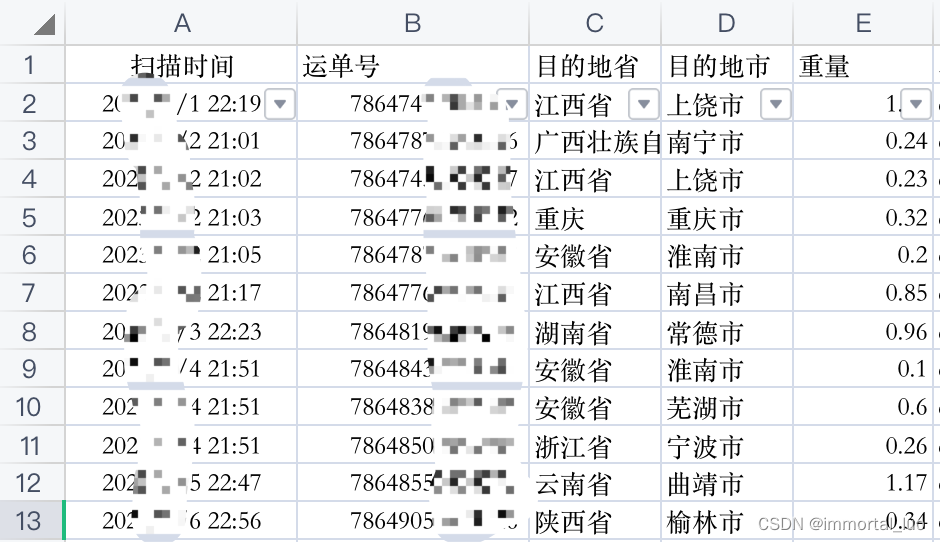
关键信息是运单号和重量
我们需要做的是,对于表A中的每一条数据,根据其单号,在表B中查找到对应的重量。
在表A中新增一列重量,将刚才查到的数据填在该列。
更近一步地,会再提供一张价格表:
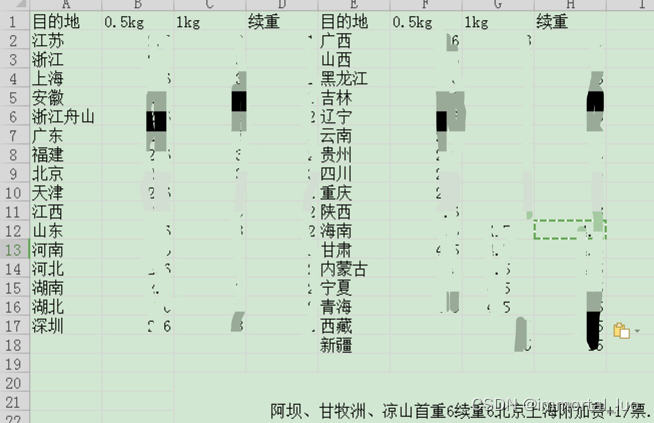
我们需要根据表A的邮寄地址和刚得到的重量计算该订单的运费。
同样在表A中新增一列运费,将计算得到的运费填写在该列。
准备工作
建立一个文件夹,在该文件夹下再建立三个文件夹,分别是origin、query和result,里面分别放表A(可以放多个表)、表B(也可以放多个表),result放的是最终的结果。
其它细节
1、可以发现有些单号为空的行被折叠了,为了保持原样,所以我们会添加一列collapse,如果订单号为空,就设置collapse为1,否则为空。之后再根据collapse这列折叠单号为空的行,后面会介绍。
2、会存在一些在表B中找不到重量信息的订单号,这些订单将被输出在命令行窗口。
3、也可以处理有多个sheet的表。
代码
import os
import re
import pandas as pd
import cpca
import math
# 将所有待处理的文件都保存在这个路径下
ROOT_DIR = '/Users/XXX/Desktop/OrderProcessing/'
# 所有结果将保存在这个路径下
SAVE_DIR = '/Users/XXX/Desktop/OrderProcessing/result/'
# 参照此格式,三个数字分别表示0.5kg,首重,续重。
# 注意省份名称一定要规范。不过不要求Excel表格中的邮寄地址必须要规范。
COST_TABLE_ORIGIN = {'江苏省': [1, 3, 1],
'浙江省': [1, 3, 1],
'上海市': [1, 3, 1],
'安徽省': [1, 3, 1],
'舟山市': [1, 3, 1]
}
def calc_cost(province, city, weight, cost_table):
"""
根据地区和重量计算运费
:param province: 省份
:param city: 城市
:param weight: 重量
:param cost_table: 价格表
:return: 价格
"""
costs = None
additional = 0
if str(province) in "北京市" or str(province) in "上海市":
additional = 1
for p, cost in cost_table.items():
if str(city) in p:
costs = cost
if costs is None:
for p, cost in cost_table.items():
if str(province) in p:
costs = cost
if costs is None:
print(" 计算费用时发生错误,可能是价格表中没有对应的地区")
return None
if weight <= 0.5:
return costs[0] + additional
elif weight <= 1:
return costs[1] + additional
else:
return costs[1] + math.ceil(weight - 1) * costs[2] + additional
def query_weight_by_order(file_name, order, order_str='运单号', weight_str='重量'):
"""
根据订单号查询重量
:param file_name: 去哪个文件里查找
:param order: 订单号
:param order_str: 订单的列名
:param weight_str: 重量的列名
:return: 该订单的重量
"""
df = pd.read_excel(io=file_name)
num_rows = len(df.index.values)
weight = None
for row in range(num_rows):
if str(df.iloc[row][order_str]) == order:
weight = df.iloc[row][weight_str]
break
return weight
def add_weight(read_file_name, write_file_name, sheet_name=None, collapse_flag=True):
"""
添加重量信息
:param read_file_name: 读取文件
:param write_file_name: 写入文件
:param sheet_name: 工作表名称
:param collapse_flag: 是否隐藏指定行,比如某项值为空,则隐藏该行
:return:
"""
if sheet_name is None:
df = pd.read_excel(io=read_file_name)
writer = pd.ExcelWriter(write_file_name)
else:
df = pd.read_excel(io=read_file_name, sheet_name=sheet_name)
# 这样写好像有点笨
if os.path.exists(write_file_name):
writer = pd.ExcelWriter(write_file_name, mode='a')
else:
writer = pd.ExcelWriter(write_file_name, mode='w')
num_rows = len(df.index.values)
if '单号' not in df.columns.values:
print(" 没有单号这一列,请确保单号那列的列名为'单号'")
writer.close()
return
for row in range(num_rows):
order = str(df.loc[row, '单号'])
'''
像order这一列,如果全是正常的单号,读进来会是浮点数,比如78649717XXX259.0
如果有几行是"停发",读进来的就都是不带小数点的了,比如78XXX17332259
空值就是显示nan
'''
if order == "nan" or order == "停发": # pd.isnull(order)
if order == "nan" and collapse_flag: # 若订单号为空,则标记隐藏该行
df.loc[row, 'collapse'] = 1
continue
# 到这里的,就是带小数点的订单号,或者正常的不带小数点的订单号
if order[-2] == '.': # 去除小数点
order = order[:-2]
# df.loc[row, '单号'] = order
# 有可能写了多个订单号,比如786497173XXX9;78649719X80XX0;786497X799ZXX4
# 这种情况下,就把多个订单的重量进行累加
orders = re.split(',|;|\n| |,|;', order)
weight = 0
for o in orders:
if len(o) <= 0:
continue
w = None
'''
这里就是根据订单的不同查询不同的表
比如Y开头的,查哪个表;数字开头的,查哪个表
此处需要自定义
'''
if o[0] == 'Y':
# 根据订单号查询重量
w = query_weight_by_order(ROOT_DIR + "query/A.xlsx", o, order_str='运单号码', weight_str='计费重量(kg)')
elif '0' <= o[0] <= '9':
w = query_weight_by_order(ROOT_DIR + "query/B.xlsx", o)
if w is not None and (isinstance(w, float) or isinstance(w, int)):
weight += w
else:
print(" 没有找到该订单的重量数据:" + o)
if weight > 0:
df.loc[row, '重量'] = weight
# 格式化地址信息
address = cpca.transform([df.loc[row, '邮寄地址']])
# 计算运费
cost = calc_cost(address.loc[0, '省'], address.loc[0, '市'], weight, COST_TABLE_ORIGIN)
if cost is None:
print(" 发生错误的订单号为:", order)
continue
else:
df.loc[row, '运费'] = cost
if sheet_name is None:
df.to_excel(writer, index=False)
else:
df.to_excel(writer, index=False, sheet_name=sheet_name)
writer.close()
"""
TODO:
1、修改ROOT_DIR和SAVE_DIR
2、将所有待处理的xlsx文件保存在ROOT_DIR/origin路径下,查询表保存在ROOT_DIR/query路径下
2、修改查询订单重量的代码,只需要简单地填写文件名,关键的列名等
3、修改价格表,并在调用calc_cost方法的地方指定价格表
"""
if __name__ == '__main__':
if not os.path.exists(ROOT_DIR):
print(ROOT_DIR + "不存在")
exit()
if not os.path.exists(SAVE_DIR):
print("创建目录:" + SAVE_DIR)
os.mkdir(SAVE_DIR)
else:
ans = input("是否删除%s下的所有文件?(Y/N):" % SAVE_DIR)
if ans == "Y":
# 删除该目录下的所有文件
for filename in os.listdir(SAVE_DIR):
os.remove(SAVE_DIR+filename)
print("已删除SAVE_DIR下的所有文件")
print("开始处理")
for filename in os.listdir(ROOT_DIR+"origin/"):
if filename[0] == '.' or filename[-4:] != "xlsx": # 去除隐藏文件和非xlsx文件
continue
print("正在处理:" + filename)
xlsx = pd.ExcelFile(ROOT_DIR + "origin/" + filename)
sheet_names = xlsx.sheet_names
xlsx.close() # 不知道是不是需要
for sheet_name in sheet_names:
print(" 正在处理:", sheet_name)
add_weight(ROOT_DIR + "origin/" + filename, SAVE_DIR + filename, sheet_name)
print("处理完毕")
处理结果
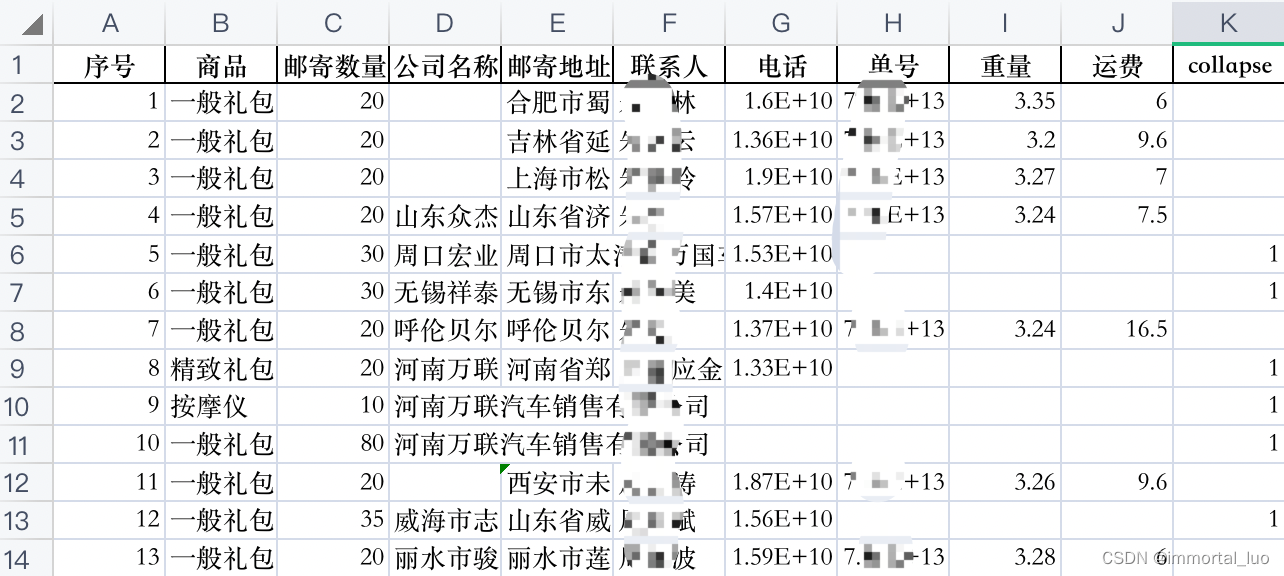
然后我们需要根据collapse列来折叠单号为空的行。
这个我还不知道怎么通过pandas实现,现在就只能先通过Excel自带的功能处理。
比如Mac版的WPS是这么处理的
1、选中collapse列

2、按command+G。按下图设置

3、点击定位
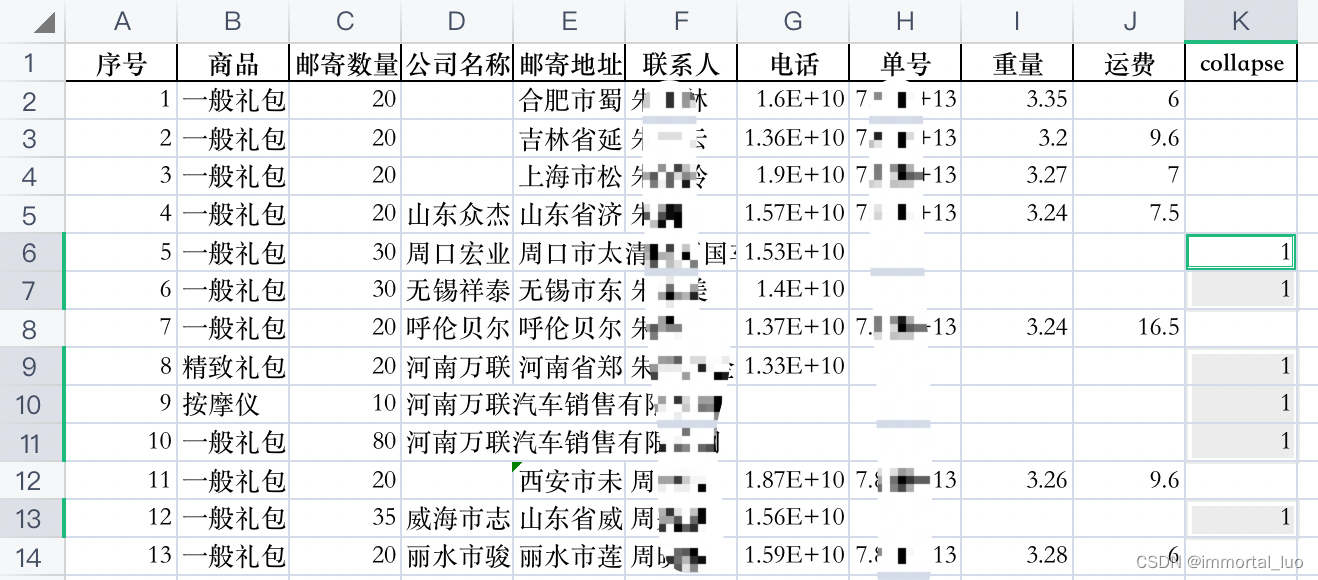
可以发现collapse为1的行被选中了
4、点击command+9。单号为空的行就被折叠了
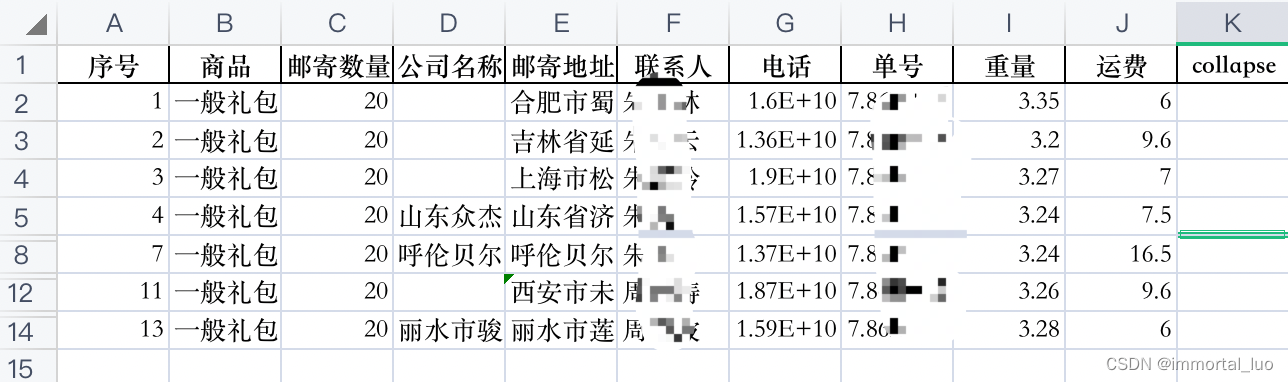
5、然后再删除collapse这列就行了
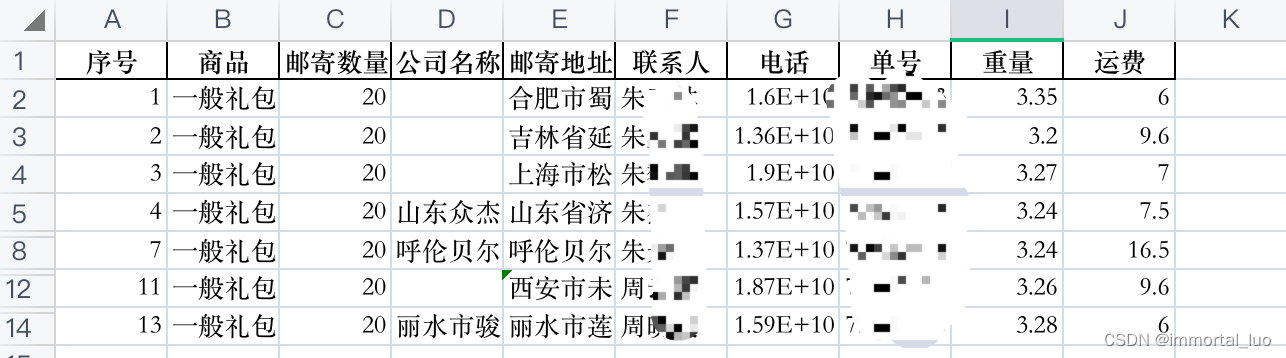
最终结果:
命令行窗口输出
是否删除/Users/XXX/Desktop/OrderProcessing/result/下的所有文件?(Y/N):Y
已删除SAVE_DIR下的所有文件
开始处理
正在处理:table1.xlsx
正在处理: Sheet1
正在处理: Sheet2
正在处理:A.xlsx
正在处理: AA
没有找到该订单的重量数据:中通:786XXXX23
没有找到该订单的重量数据:786X5780XX37
没有找到该订单的重量数据:合在一起打包
没有找到该订单的重量数据:786493XX3783158
正在处理: AB
计算费用时发生错误,可能是价格表中没有对应的地区
发生错误的订单号为: 78649XXX184656
计算费用时发生错误,可能是价格表中没有对应的地区
发生错误的订单号为: 786497XXX08769
没有找到该订单的重量数据:786X979XX8226
没有找到该订单的重量数据:5箱
没有找到该订单的重量数据:直发
正在处理: AC
正在处理: AD
没有找到该订单的重量数据:YT699X121XX068
没有找到该订单的重量数据:YT6993X9X987155
没有找到该订单的重量数据:786499616XXX08
没有找到该订单的重量数据:YT6XXX875919847
没有找到该订单的重量数据:786497XXX57489
正在处理: AE
没有单号这一列,请确保单号那列的列名为'单号'
处理完毕
Process finished with exit code 0

















 2207
2207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









