







一、lambda
1.lambda函数特点
- lambda表达式是一种匿名函数,即没有函数名的函数;
- 取而代之的多了一对方括号[];
- lambda函数还采用了追踪返回值类型的方式声明其返回值;
- 匿名函数是由数学中的λ演算而来。
- 在C++11中,lambda函数是inline(内联函数)。
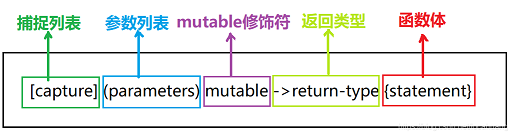
2.lambda语法定义
[capture] (parameters) mutable ->return-type {statement}
其中:
[capture] :捕捉列表。捕捉列表总是作为lambda的开始处,它是lambda的引出符(即开始标志)。编译器可以根据该“标志”来作出判断该函数是否为lambda函数。同时“捕捉列表”能够捕捉上下文中的变量以作为lambda函数使用。
(parameters):参数列表。和C/C++的普通函数的参数意义一样。该部分是可选的。意味着如果我们不需要进行参数传递时,可以连同括号“()”一起省略。
mutable:该关键字作为一个修饰符。在默认情况下,lambda函数总是返回一个const,而当我们在参数列表后面注明了“mutable”关键字之后,则可以取消其常量性质。若在lambda中使用了mutable修饰符,则“参数列表”是不可省略掉的(即使是参数为空)
return-type:函数的返回值类型。和C/C++中的普通函数返回值类型的性质一样。主要目的是用来追踪lambda函数(有返回值情况下)的返回类型。若lambda函数不需要返回值,则可以直接将这部分省略掉。
{statement}:函数体。在该函数体中,除了可以使用参数列表中的变量外,还可以使用所有捕获到的变量(即[capture] 中的变量)。
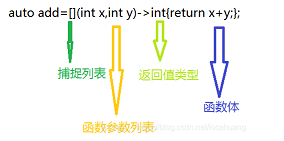
最简单的lambda表达式可以这样写:auto lam=[]{}; 这个表达式什么事也做不了,参数列表和返回值类型可以省略。
3.lambda使用实例
3.1 捕捉列表
该列表总是出现在lambda函数的开始位置,编译器根据[ ]来判断接下来的代码是否为lambda函数,捕捉列表能够捕捉上下文的变量供lambda函数使用。
语法上 捕捉列表可以由0个或多个“捕捉项”组成,并以逗号“,”分隔。
比如:
[=, &a, &b]:以引用传递的方式捕捉变量a和b,值传递方式捕捉其他所有变量
[&,a, this]:值传递方式捕捉变量a和this,引用方式捕捉其他变量
注意:捕捉列表不运行变量重复传递,否则就会导致编译错误。
[=, a]:=已经以值传递方式捕捉了所有变量,捕捉a重复
捕捉列表有以下几种情形:
1)[var] 表示值传递方式捕捉变量var
#include <iostream>
#include <string>
#include <stdio.h>
using namespace std;
int main()
{
int a=1, b=2, c=3;
auto reval = [=,&a,&b](){
printf("inner c[%d]\n", c);
a=10;
b=20;
return a+b;
};
printf("sum[%d]\n",reval ());
printf("a[%d] b[%d] c[%d]\n",a,b,c);
return 0;
}
输出结果:
inner c[3]
sum[30]
a[10] b[20] c[3]
代码讲解:
上面的代码中,“捕捉列表”由3项组成。以引用传递的方式捕捉变量a、b,以值传递的方式捕捉变量c。因此在lambda表达式的函数体中修改了变量a和b之后,父作用域中的a、b值也改变。而即使是在lambda函数内部修改了变量c的值,父作用域中的c仍然不会受到影响,因为是值传递的方式。(需在参数列表后面加上 mutable 关键字(修饰符))。
#include <iostream>
#include <string>
#include <stdio.h>
using namespace std;
int main()
{
int a = 1,b =2, c =3;
auto retVal = [=,&a,&b]() mutable->int //比上面例子增加 ‘mutable->int’,使得c可以在函数体内赋值
{
printf("inner c[%d]\n",c);
a = 10;
b = 20;
c = 30; //c=30
printf("inner c2[%d]\n",c);
return a+b;
};
printf("sum[%d]\n",retVal());
printf("a[%d] b[%d] c[%d]\n",a,b,c);
return 0;
}
输出结果:
inner c[3]
inner c2[30]
sum[30]
a[10] b[20] c[3]
2)[=] 表示值传递方式捕捉所有父作用域的变量(包括this)
3)[&var] 表示引用传递捕捉变量var
4)[&] 表示引用传递捕捉所有父作用域的变量(包括this)
#include <iostream>
#include <string>
#include <stdio.h>
using namespace std;
int main()
{
int a = 1,b =2, c =3;
auto retVal = [&]() mutable->int
{
printf("inner a[%d] b[%d] c[%d]\n",a,b,c);
a = 10;
b = 20;
c = 30;
return a+b;
};
printf("sum[%d]\n",retVal());
printf("a[%d] b[%d] c[%d]\n",a,b,c);
return 0;
}
输出结果:
inner a[1] b[2] c[3]
sum[30]
a[10] b[20] c[30]
5)[this]表示值传递方式捕捉当前的this指针
注意:这里的父作用域指包含lambda函数的语句块。
3.2 lambda函数使用
lambda函数的使用场景比较特殊:比如打印一些内容状态,或者进行一些内部操作,这些功能不能与其他的代码共享,却要在一个函数中多次重用。
在lambda没有引入前,我们只能封装函数来实现,出于函数作用域及运行效率考虑,此函数通常还需加上static和inline关键字。
但lambda的引入,其捕捉列表的功能,使我们不用考虑参数个数以及传递方式,而且主调函数结束函数,lambda函数也结束,不会影响命名空间中的其他东西,使代码的实现更加简答,可读性更高。
double rate = 1.2;
//最简单的lambda表达式
auto lam = []{};
auto add3 = [](int x, int y, double rate)->double{return (x + y)*rate; };
cout << add3(1, 2, rate) << endl; //3.6
//auto add4 = [=](int x, int y)->double{return (x + y)*rate; };
//auto add4 = [&](int x, int y)->double{return (x + y)*rate; };
auto add4 = [rate](int x, int y)->double{return (x + y)*rate; };
//auto add4 = [&rate](int x, int y)->double{return (x + y)*rate; };
cout << add4(1, 2) << endl; //3.6
int a = 10, b = 20;
auto swap1 = [](int& x1, int& x2) {int x = x1; x1 = x2; x2 = x; };
swap1(a, b);
cout << a << " " << b << endl; //20 10
auto swapab = [&a, &b]() {int x = a; a = b; b = x; };
swapab();
cout << a << " " << b << endl; //10 20
auto swap3 = [&]() {int x = a; a = b; b = x; };
swap3();
cout << a << " " << b << endl; //20 10
3.3 lambda几种使用形式的比较


二、nullptr
1.传统C++ NULL存在的问题
在某种意义上来说,传统 C++ 会把NULL、0视为同一种东西,这取决于编译器如何定义NULL,有些编译器会将NULL定义为 ((void*)0),有些则会直接将其定义为0。
C++ 不允许直接将 void* 隐式转换到其他类型,但如果NULL被定义为 ((void*)0),那么当编译下面语句时:
char *ch = NULL
NULL 只好被定义为0。而这依然会产生问题,将导致C++中重载特性会发生混乱。
比如,对于下面两个函数来说:
void foo(char *);
void foo(int);
如果 NULL又被定义为了0 那么foo(NULL); 这个语句将会去调用foo(int),从而导致代码违反直观。
2.nullptr出现的目的
为了解决NULL存在的问题,C++11 引入了 nullptr 关键字,专门用来区分空指针、0。
nullptr 的类型为nullptr_t,能够隐式的转换为任何指针或成员指针的类型,也能和他们进行相等或者不等的比较。
#include <iostream>
void foo(char *ch)
{
std::cout << "call foo(char*)" << std::endl;
}
void foo(int i)
{
std::cout << "call foo(int)" << std::endl;
}
int main()
{
if(NULL == (void *)0)
std::cout << "NULL == 0" << std::endl;
else
std::cout << "NULL != 0" << std::endl;
foo(0);
// foo(NULL); // 编译无法通过
foo(nullptr);
return 0;
}
输出结果:
NULL == 0
call foo(int)
call foo(char*)
三、constexpr
1.C++98之前常数的使用问题
C++ 本身已经具备了常数表达式的概念,比如 1+2, 3*4 这种表达式总是会产生相同的结果并且没有任何副作用。
如果编译器能够在编译时就把这些表达式直接优化并植入到程序运行时,将能增加程序的性能。
一个非常显著的例子就是在数组的定义阶段:
#include <iostream>
#include <string>
#include <stdio.h>
using namespace std;
#define LEN 10
int len_foo()
{
return 5;
}
int main()
{
char arr_1[10];
char arr_2[LEN];
int len = 5;
char arr_3[len + 5]; // 非法
const int len_2 = 10;
char arr_4[len_2 + 5]; // 合法
char arr_5[len_foo() + 5]; // 非法
return 0;
}
- 在 C++11 之前,可以在常量表达式中使用的变量必须被声明为const,在上面代码中,len_2被定义成了常量,因此 len_2+5是一个常量表达式,所以能够合法的分配一个数组arr_4;
- 而对于arr_5 来说,C++98之前的编译器无法得知len_foo() 在运行期实际上是返回一个常数,这也就导致了非法的产生。
2. constexpr
2.1 constexpr的意义
C++11 提供了 constexpr 让用户显式的声明函数或对象构造函数在编译器会成为常数,这个关键字明确的告诉编译器应该去验证len_foo 在编译时就应该是一个常数。
将变量声明为constexpr类型以便由编译器来验证变量是否是一个常量表达式(不会改变,在编译过程中就能得到计算结果的表达式)。是一种比const更强的约束,这样可以得到更好的效率和安全性。
2.2 constexpr用法
1)修饰函数
constexpr修饰的函数,不能依赖任何运行期的信息,不要定义任何变量,并且尽量简单,要不就会编译不过或告警。
//1.如果size在编译时能确定,那么返回值就可以是constexpr,编译通过
constexpr int getSizeA(int size)
{
return 4*size;
}
//2.编译通过,有告警:在constexpr中定义变量
constexpr int getSizeB(int size)
{
int index = 0;
return 4;
}
//3.编译通过,有告警:在constexpr中定义变量(这个有点迷糊)
constexpr int getSizeC(int size)
{
constexpr int index = 0;
return 4;
}
//4.编译通过,有告警:使用了if语句(使用switch也会告警)
constexpr int getSizeD(int size)
{
if(0)
{}
return 4;
}
//5.定义变量并且没有初始化,编译不过
constexpr int getSizeE(int size)
{
int index;
return 4;
}
//6.rand()为运行期函数,不能在编译期确定,编译不过
constexpr int getSizeF(int size)
{
return 4*rand();
}
//使用了for,编译不过
constexpr int getSizeG(int size)
{
for(;0;)
{}
return 4*rand();
}
2)修饰类型
constexpr修饰的常量必须在编译期确定值,上面的例子也体现出了和const之间的差别。
const既可以在编译期确定如ctempA,也可以在运行期确定如ctempB,使用范围更广。
还有一点constexpr只能修饰字面值类型如算数类型、引用类型、指针以及后面介绍的字面值常量类。
int tempA;
cin>>tempA;
const int ctempA = 4;
const int ctempB = tempA;
//1.可以再编译器确定,编译通过
constexpr int conexprA = 4;
constexpr int conexprB = conexprA + 1;
constexpr int conexprC = getSizeA(conexprA);
constexpr int conexprD = ctempA;
//2.不能在编译期决定,编译不过
constexpr int conexprE = tempA;
constexpr int conexprF = ctempB;
3)修饰指针
constexpr指针不能用局部变量赋值,const指针可以;
constexpr指针里是顶层const,即指针是常量,而不是所指向的类型是常量,如果要指向的类型也为常量,要用constexpr const来修饰。
#include <iostream>
#include <string>
#include <stdio.h>
using namespace std;
int g_tempA = 4;
const int g_conTempA = 4;
constexpr int g_conexprTempA = 4;
int main(void)
{
int tempA = 4;
const int conTempA = 4;
constexpr int conexprTempA = 4;
//1.正常运行,编译通过
const int *conptrA = &tempA;
const int *conptrB = &conTempA;
const int *conptrC = &conexprTempA;
//2.局部变量的地址要运行时才能确认,故不能在编译期决定,编译不过
constexpr int *conexprPtrA = &tempA;
constexpr int *conexprPtrB = &conTempA;
constexpr int *conexprPtrC = &conexprTempA;
//3.第一个通过,后面两个不过,因为constexpr int *所限定的是指针是常量,故不能将常量的地址赋给顶层const
constexpr int *conexprPtrD = &g_tempA;
constexpr int *conexprPtrE = &g_conTempA;
constexpr int *conexprPtrF = &g_conexprTempA;
//4.局部变量的地址要运行时才能确认,故不能在编译期决定,编译不过
constexpr const int *conexprConPtrA = &tempA;
constexpr const int *conexprConPtrB = &conTempA;
constexpr const int *conexprConPtrC = &conexprTempA;
//5.正常运行,编译通过
constexpr const int *conexprConPtrD = &g_tempA;
constexpr const int *conexprConPtrE = &g_conTempA;
constexpr const int *conexprConPtrF = &g_conexprTempA;
return 0;
}
4)修饰引用
简单的说constexpr所引用的对象必须在编译期就决定地址。
constexpr修饰的引用不是常量(可以通过上例conexprPtrD来修改g_tempA的值),如果要确保其实常量引用需要constexpr const来修饰。
int g_tempA = 4;
const int g_conTempA = 4;
constexpr int g_conexprTempA = 4;
int main(void)
{
int tempA = 4;
const int conTempA = 4;
constexpr int conexprTempA = 4;
//1.正常运行,编译通过
const int &conptrA = tempA;
const int &conptrB = conTempA;
const int &conptrC = conexprTempA;
//2.有两个问题:一是引用到局部变量,不能再编译器确定;二是conexprPtrB和conexprPtrC应该为constexpr const类型,编译不过
constexpr int &conexprPtrA = tempA;
constexpr int &conexprPtrB = conTempA;
constexpr int &conexprPtrC = conexprTempA;
//3.第一个编译通过,后两个不通过,原因是因为conexprPtrE和conexprPtrF应该为constexpr const类型
constexpr int &conexprPtrD = g_tempA;
constexpr int &conexprPtrE = g_conTempA;
constexpr int &conexprPtrF = g_conexprTempA;
//4.正常运行,编译通过
constexpr const int &conexprConPtrD = g_tempA;
constexpr const int &conexprConPtrE = g_conTempA;
constexpr const int &conexprConPtrF = g_conexprTempA;
return 0;
}
四、noexcept
1.关键字noexcept
从C++11开始,我们能看到很多代码当中都有关键字noexcept。比如下面就是std::initializer_list的默认构造函数,其中使用了noexcept。
constexpr initializer_list() noexcept
: _M_array(0), _M_len(0) { }
该关键字告诉编译器,函数中不会发生异常,这有利于编译器对程序做更多的优化。
如果在运行时,noexecpt函数向外抛出了异常(如果函数内部捕捉了异常并完成处理,这种情况不算抛出异常),程序会直接终止,调用std::terminate()函数,该函数内部会调用std::abort()终止程序。
2.C++的异常处理
C++中的异常处理是在运行时而不是编译时检测的。为了实现运行时检测,编译器创建额外的代码,然而这会妨碍程序优化。
在实践中,一般常用的两种异常抛出方式是:
- 一个操作或者函数可能会抛出一个异常;
- 一个操作或者函数不可能抛出任何异常。
后面这一种方式中在以往的C++版本中常用throw()表示,在C++ 11中已经被noexcept代替。
void swap(Type& x, Type& y) throw() //C++11之前
{
x.swap(y);
}
void swap(Type& x, Type& y) noexcept //C++11
{
x.swap(y);
}
3.有条件的noexcept
在第2节中单独使用noexcept,表示其所限定的swap函数绝对不发生异常。
然而,使用方式可以更加灵活,表明在一定条件下不发生异常。
实例1:如果操作x.swap(y)不发生异常,那么函数swap(Type& x, Type& y)一定不发生异常。
void swap(Type& x, Type& y) noexcept(noexcept(x.swap(y))) //C++11
{
x.swap(y);
}
实例2:std::pair中的移动分配函数(move assignment),它表明,如果类型T1和T2的移动分配(move assign)过程中不发生异常,那么该移动构造函数就不会发生异常。
pair& operator=(pair&& __p)
noexcept(__and_<is_nothrow_move_assignable<_T1>,
is_nothrow_move_assignable<_T2>>::value)
{
first = std::forward<first_type>(__p.first);
second = std::forward<second_type>(__p.second);
return *this;
}
4.什么时候使用noexcept?
使用noexcept表明函数或操作不会发生异常,会给编译器更大的优化空间。然而,并不是加上noexcept就能提高效率。
以下情形鼓励使用noexcept:
- 移动构造函数(move constructor)
- 移动分配函数(move assignment)
- 析构函数(destructor)–(在新版本的编译器中,析构函数是默认加上关键字noexcept的)
- 叶子函数(Leaf Function)–(叶子函数是指在函数内部不分配栈空间,也不调用其它函数,也不存储非易失性寄存器,也不处理异常。)
需要说明的是:在不是以上情况或者没把握的情况下,不要轻易使用noexception。















 260
260











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









