







本文主要介绍常见的标准化方法,并通过代码自己去复现官方的API。常见的几种标准化的方法示意图如下图所示,但是这种比较抽象,初学者很难理解。其实文本和图像都可以使用这些标准化方法,如果把图像中的每个像素想象成文本中一个个字符,然后将图像展平拉伸为1维,那么图像就是文本了。如果实在没法理解,不用担心,本文会提供更加生动的图示。
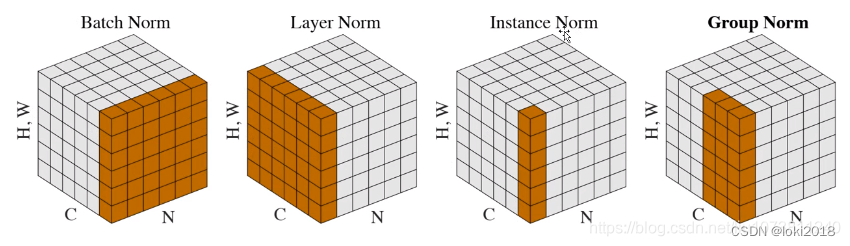
1. Batch Normalization
Ioffe S, Szegedy C. Batch normalization: Accelerating deep network training by reducing internal covariate shift[C]//International conference on machine learning. PMLR, 2015: 448-456.

具体做法如上图所示,计算除了通道维的均值和方差从而进行标准化,即batch中每个样本对应位置的特征做标准化(以均值为例,每个样本第n个通道的特征图计算均值,得到一个均值特征图,再对高和宽再算均值最终得到n个1x1的均值特征图)。其中
γ
\gamma
γ和
β
\beta
β是可学习的超参数。BN的提出是为了加快神经网络的训练并且解决Internal Covariate Shift的问题。使用了BN之后我们可以采用较大的学习率。
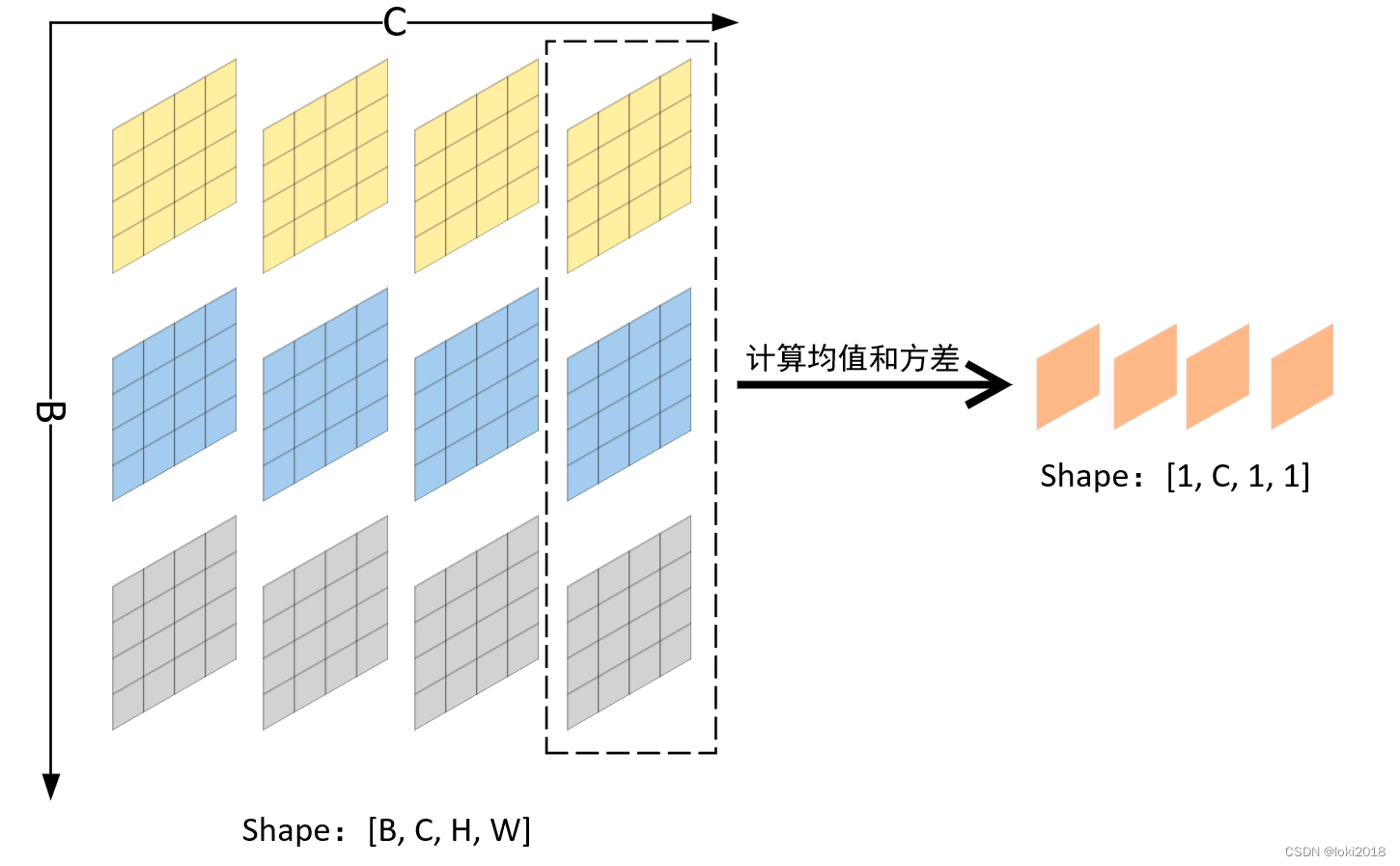
此外,BN也可以提供正则化的作用,从而减少Dropout的使用。
pytorch简洁代码实现:
import torch
import torch.nn as nn
class MyBatchNorm2D(nn.Module):
def __init__(self, num_features, eps=1e-5, momentum=0.1):
super(MyBatchNorm2D, self).__init__()
self.gamma = nn.Parameter(torch.ones(num_features))
self.beta = nn.Parameter(torch.zeros(num_features))
self.eps = eps
self.momentum = momentum
self.register_buffer('running_mean', torch.zeros(num_features)) # 保存均值
self.register_buffer('running_var', torch.ones(num_features)) # 保存方差
def forward(self, x):
# x: (N, C, H, W)
if self.training:
mean = x.mean(dim=(0, 2, 3), keepdim=True) # (1, C, 1, 1) 计算每个通道的均值
var = ((x - mean) ** 2).mean(dim=(0, 2, 3), keepdim=True) # (1, C, 1, 1) 计算每个通道的方差
self.running_mean = (1 - self.momentum) * self.running_mean + self.momentum * mean.squeeze() # [C]
self.running_var = (1 - self.momentum) * self.running_var + self.momentum * var.squeeze() # [C]
else:
mean = self.running_mean.unsqueeze(0).unsqueeze(2).unsqueeze(3) # (1, C, 1, 1)
var = self.running_var.unsqueeze(0).unsqueeze(2).unsqueeze(3) # (1, C, 1, 1)
x = (x - mean) / (var + self.eps).sqrt()
x = x * self.gamma.unsqueeze(0).unsqueeze(2).unsqueeze(3) + self.beta.unsqueeze(0).unsqueeze(2).unsqueeze(3)
return x
2. Layer Normalization
Ba J L, Kiros J R, Hinton G E. Layer normalization[J]. arXiv preprint arXiv:1607.06450, 2016.
在batch size过小的情况下,BN的效果往往不那么理想,并且很难应用于NLP的任务,因为NLP的句子末尾通常会有填充的空白token,因此batch中每个样本在末尾相对应的特征做BN完全没有意义。为了解决这一问题,LN被提出,原理很简单,就是每个样本自己做标准化即可。
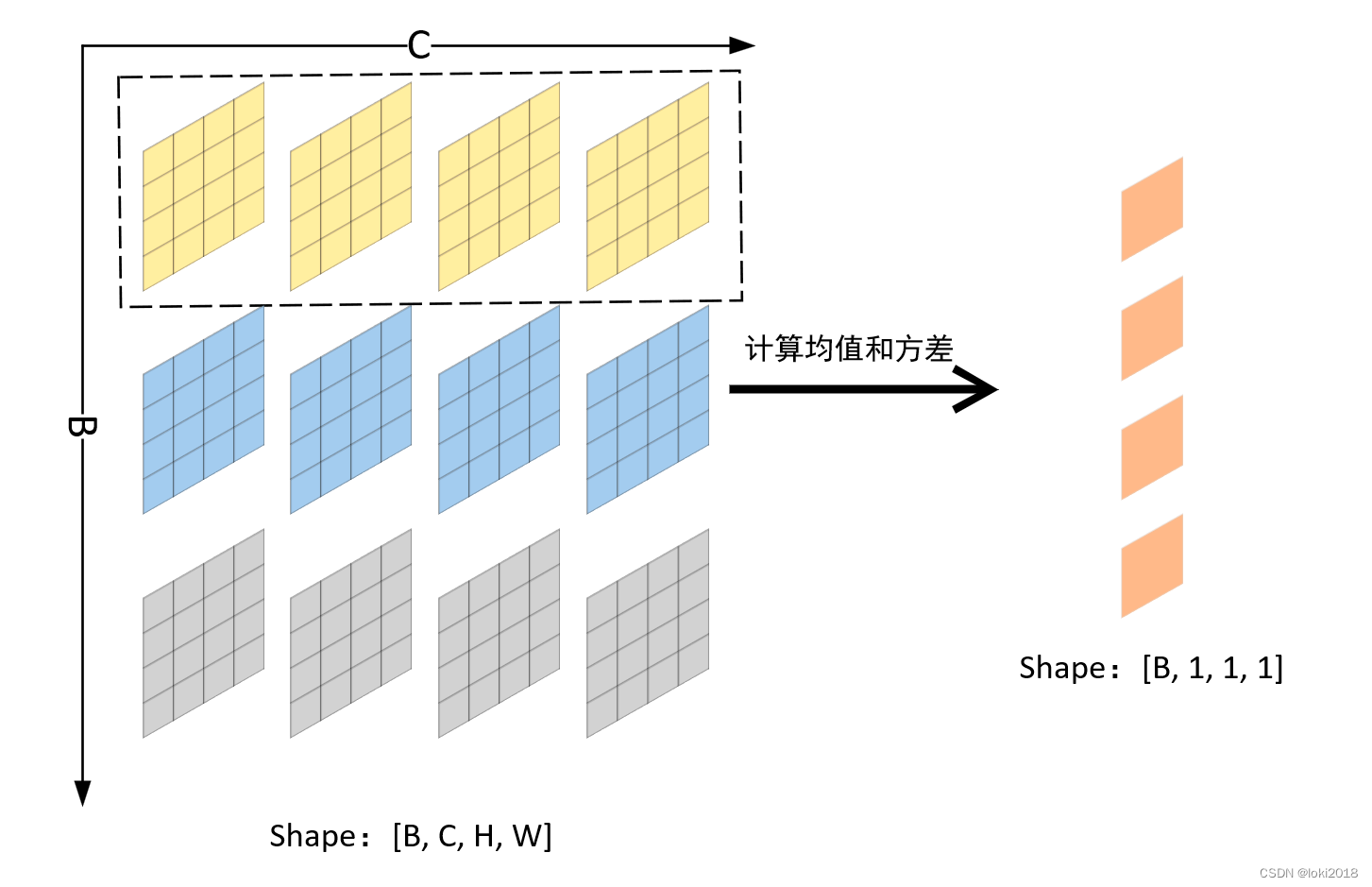

pytorch简洁代码实现:
class MyLN(nn.Module):
def __init__(self, normalized_shape):
super(MyLN, self).__init__()
self.normalized_shape = normalized_shape
self.scale = nn.Parameter(torch.ones(normalized_shape))
self.shift = nn.Parameter(torch.zeros(normalized_shape))
self.eps = 1e-5
def forward(self, x):
if isinstance(self.normalized_shape, list):
dim = [-(i+1) for i in range(len(self.normalized_shape))]
else:
dim = -1
mean = torch.mean(x, dim=dim, keepdim=True)
var = torch.mean(x**2, dim=dim, keepdim=True) - mean**2
x = (x - mean) / (torch.sqrt(var + self.eps))
x = x * self.scale + self.shift
return x
3. Instance Normalization
Instance Normalization主要用于图像风格迁移的任务中。它对每个Batch中的数据的每个通道进行单独的标准化。
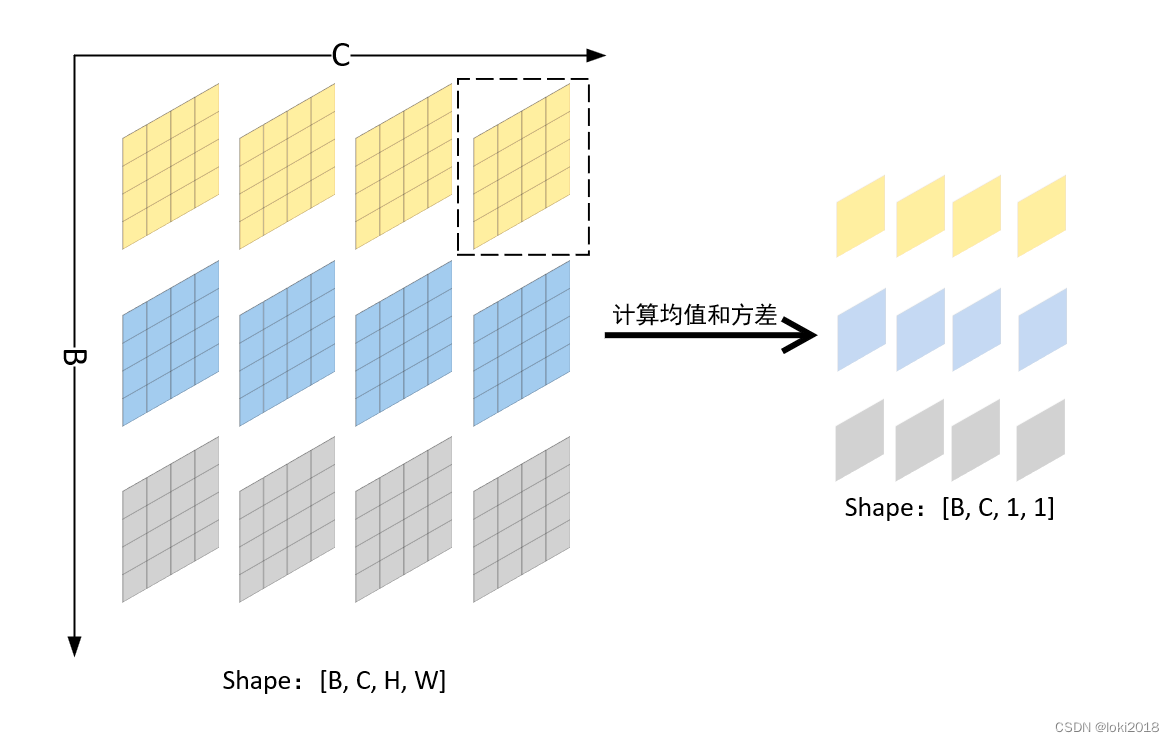
pytorch简洁代码实现:
import torch
import torch.nn as nn
class MyInstanceNorm(nn.Module):
def __init__(self, num_features, eps=1e-5, momentum=0.1):
super(MyInstanceNorm, self).__init__()
self.num_features = num_features
self.eps = eps
self.momentum = momentum
self.gamma = nn.Parameter(torch.Tensor(num_features))
self.beta = nn.Parameter(torch.Tensor(num_features))
self.register_buffer('running_mean', torch.zeros(num_features))
self.register_buffer('running_var', torch.ones(num_features))
self.reset_parameters()
def reset_parameters(self):
self.running_mean.zero_()
self.running_var.fill_(1)
self.gamma.data.fill_(1)
self.beta.data.zero_()
def forward(self, x):
# x: (N, C, H, W)
if self.training:
mean = x.mean(dim=2, keepdim=True).mean(dim=3, keepdim=True) # (N, C, 1, 1)
var = ((x - mean) ** 2).mean(dim=2, keepdim=True).mean(dim=3, keepdim=True) # (N, C, 1, 1)
x = (x - mean) / torch.sqrt(var + self.eps)
self.running_mean = (1 - self.momentum) * self.running_mean + self.momentum * mean.mean(dim=2, keepdim=True).mean(dim=3, keepdim=True)
self.running_var = (1 - self.momentum) * self.running_var + self.momentum * var.mean(dim=2, keepdim=True).mean(dim=3, keepdim=True)
else:
x = (x - self.running_mean) / torch.sqrt(self.running_var + self.eps)
x = x * self.gamma.view(1, -1, 1, 1) + self.beta.view(1, -1, 1, 1)
return x
4. Group Normalization
即对每个batch数据的通道进行分组归一化,当组数等于通道数时,即等价于Instance normalization,当组数为1时,即等价于Layer normalization。
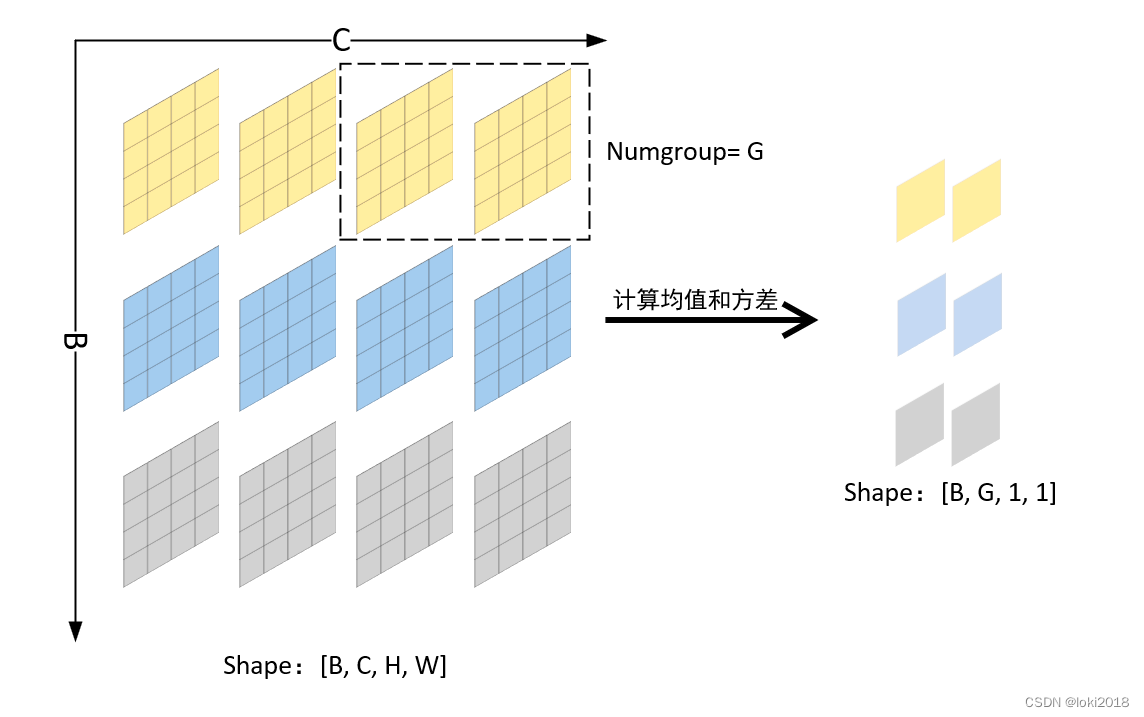
pytorch简洁代码实现:
import torch
import torch.nn as nn
class MyGroupNorm(nn.Module):
def __init__(self, num_groups, num_channels, eps=1e-5):
super(MyGroupNorm, self).__init__()
self.num_groups = num_groups
self.num_channels = num_channels
self.eps = eps
self.weight = nn.Parameter(torch.Tensor(num_channels))
self.bias = nn.Parameter(torch.Tensor(num_channels))
self.reset_parameters()
def reset_parameters(self):
self.weight.data.fill_(1)
self.bias.data.zero_()
def forward(self, x):
# x: (N, C, H, W)
N, C, H, W = x.size()
G = self.num_groups
assert C % G == 0
x = x.view(N, G, -1) # (N, G, C//G*H*W)
mean = x.mean(dim=-1, keepdim=True) # (N, G, 1)
var = x.var(dim=-1, keepdim=True) # (N, G, 1)
x = (x - mean) / torch.sqrt(var + self.eps)
x = x.view(N, C, H, W)
x = x * self.weight.view(1, C, 1, 1) + self.bias.view(1, C, 1, 1)
return x















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









