






1. 前言
向量量化(Vector Quantization)或称为矢量量化最早在1984年由Gray提出,主要应用于数据压缩、检索领域,具体的阐述可以参考我写的另一篇关于VQ算法的文章。随着基于神经网络的离散表征学习模型的兴起,VQ技术也开始重新被重视。它在图像、音频等表征学习中体现出了优秀的性能,并且有希望成为多模态大语言模型的重要组件。
在AI领域,最为知名应该是VQ-VAE(Vector Quantized-Variational Autoencoder)了,它的思想是将图像 x x x映射为表征 z k × d z^{k \times d} zk×d,其中 z k × d z^{k \times d} zk×d由一组维度为 d d d的特征向量构成,VQ-VAE引入了一个codebook记为 C n × d C^{n \times d} Cn×d。 z k × d z^{k \times d} zk×d会和 C n × d C^{n \times d} Cn×d中的向量进行距离计算,可以是欧式距离也可以是余弦相似度,用 C n × d C^{n \times d} Cn×d中距离最近或者最相似的向量来表示 z k × d z^{k \times d} zk×d中的向量。这种量化操作往往不可微,因此VQ-VAE使用了一个非常简单的技巧straight through estimator (STE)来解决,具体的实现可以看代码。
VQ-VAE的损失函数主要由三个部分组成,以确保模型能够有效地学习到有用的离散表征,并同时保持输入数据的重建质量:
L
=
L
recon
+
α
L
quant
+
β
L
commit
L = L_{\text{recon}} + \alpha L_{\text{quant}} + \beta L_{\text{commit}}
L=Lrecon+αLquant+βLcommit
- 重建损失(Reconstruction
Loss):这部分的损失计算了模型重建的输出与原始输入之间的差异。目标是最小化这一差异,以确保重建的数据尽可能接近原数据。常见的重建损失包括均方误差(MSE)或交叉熵损失,具体取决于输入数据的类型。 - 量化损失(Quantization Loss)或 码本损失(Codebook Loss):在训练过程中,当输入数据通过编码器被编码到潜在空间后,每个潜在表示会被量化为最近的码本向量。量化损失计算潜在表示与其对应的最近码本向量之间的距离。通过最小化量化损失,模型优化码本向量的位置,使其更好地代表输入数据的潜在表示。这有助于模型更准确地量化潜在空间,并提高重建质量。
- 提交损失(Commitment Loss):提交损失主要用于稳定训练过程,它鼓励编码器生成的潜在表示靠近选中的码本向量。这样做可以防止码本向量在训练过程中出现较大的变动,从而确保模型的稳定性。提交损失通过计算编码器输出的潜在表示与选中的码本向量之间的距离来实现其目标。因此,提交损失主要影响编码器的参数更新,帮助编码器学习生成与码本向量更接近的潜在表示。
虽然VQ-VAE的效果比传统的VAE要好,但是它使用的codebook中的大部分向量并未被利用到,造成了存储和计算的大量浪费,此外,它额外引入的两项损失即codebook loss和commitment loss也带来些许复杂性。
FSQ(FINITE SCALAR QUANTIZATION: VQ-VAE MADE SIMPLE)这篇文章的目的就是优化以上两个问题。
2. 方法
作者发现,传统的编码器所得到的表征向量
z
z
z中的每一个元素(标量)的值并没有一个明确的边界,也就是说
z
z
z在特征空间中不受任何约束。那么,作者就想到了为
z
z
z中的每个标量都设定好取值的范围和能够取值的个数。
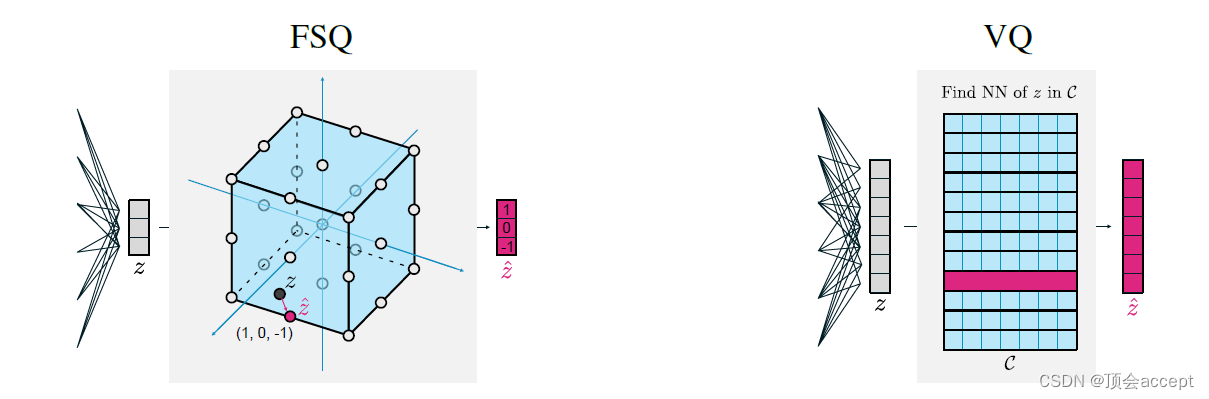
假设有一个d维特征向量
z
z
z,将每个标量
z
i
z_i
zi都限制只能取
L
L
L个值,将
z
i
→
⌊
L
/
2
⌋
t
a
n
h
(
z
i
)
z_i \rightarrow \left\lfloor L/2 \right\rfloor tanh(z_i)
zi→⌊L/2⌋tanh(zi)然后四舍五入为一个整数值。例如图中所示,取d=3,L=3,代表codebook
C
=
{
(
−
1
,
−
1
,
−
1
)
,
(
−
1
,
−
1
,
0
)
,
.
.
.
,
(
1
,
1
,
1
)
}
C=\left\{(-1, -1, -1), (-1, -1, 0), ..., (1, 1, 1)\right\}
C={(−1,−1,−1),(−1,−1,0),...,(1,1,1)},一共有27种组合,即一个3维向量的每个标量都有三种值的取法。值得一提的是,FSQ中的codebook不像VQ-VAE那样是显式存在的,而是隐式的,编码器直接输出量化后的特征向量
z
^
\hat{z}
z^。因此,FSQ也就没有了VQ-VAE损失的后两项了。

3. 代码实现
from typing import List, Tuple, Optional
import torch
import torch.nn as nn
from torch.nn import Module
from torch import Tensor, int32
from torch.cuda.amp import autocast
from einops import rearrange, pack, unpack
# helper functions
def exists(v):
return v is not None
def default(*args):
for arg in args:
if exists(arg):
return arg
return None
def pack_one(t, pattern):
return pack([t], pattern)
def unpack_one(t, ps, pattern):
return unpack(t, ps, pattern)[0]
# tensor helpers
def round_ste(z: Tensor) -> Tensor:
"""Round with straight through gradients."""
zhat = z.round() # round操作是将z中的元素四舍五入到最接近的整数
return z + (zhat - z).detach()
class FSQ(Module):
def __init__(
self,
levels: List[int],
dim: Optional[int] = None,
num_codebooks=1,
keep_num_codebooks_dim: Optional[bool] = None,
scale: Optional[float] = None,
allowed_dtypes: Tuple[torch.dtype, ...] = (torch.float32, torch.float64)
):
super().__init__()
_levels = torch.tensor(levels, dtype=int32)
self.register_buffer("_levels", _levels, persistent=False) #persistent=False表示不会被保存到checkpoint中
_basis = torch.cumprod(torch.tensor([1] + levels[:-1]), dim=0, dtype=int32)
self.register_buffer("_basis", _basis, persistent=False)
self.scale = scale
codebook_dim = len(levels) # codebook_dim表示每个codebook的维度
self.codebook_dim = codebook_dim
effective_codebook_dim = codebook_dim * num_codebooks # effective_codebook_dim表示所有codebook的维度的总和
self.num_codebooks = num_codebooks
self.effective_codebook_dim = effective_codebook_dim
keep_num_codebooks_dim = default(keep_num_codebooks_dim, num_codebooks > 1)
assert not (num_codebooks > 1 and not keep_num_codebooks_dim)
self.keep_num_codebooks_dim = keep_num_codebooks_dim
self.dim = default(dim, len(_levels) * num_codebooks)
has_projections = self.dim != effective_codebook_dim
self.project_in = nn.Linear(self.dim, effective_codebook_dim) if has_projections else nn.Identity()
self.project_out = nn.Linear(effective_codebook_dim, self.dim) if has_projections else nn.Identity()
self.has_projections = has_projections
self.codebook_size = self._levels.prod().item()
implicit_codebook = self.indices_to_codes(torch.arange(self.codebook_size), project_out=False)
self.register_buffer("implicit_codebook", implicit_codebook, persistent=False)
self.allowed_dtypes = allowed_dtypes
def bound(self, z: Tensor, eps: float = 1e-3) -> Tensor:
"""Bound `z`, an array of shape (..., d)."""
half_l = (self._levels - 1) * (1 + eps) / 2
offset = torch.where(self._levels % 2 == 0, 0.5, 0.0)
shift = (offset / half_l).atanh() # atanh是双曲正切函数的反函数,能够将值映射到[-1, 1]之间
return (z + shift).tanh() * half_l - offset
def quantize(self, z: Tensor) -> Tensor:
"""Quantizes z, returns quantized zhat, same shape as z."""
quantized = round_ste(self.bound(z))
half_width = self._levels // 2 # Renormalize to [-1, 1].
return quantized / half_width
def _scale_and_shift(self, zhat_normalized: Tensor) -> Tensor:
# 将zhat_normalized的值映射到[0, levels]之间
half_width = self._levels // 2
return (zhat_normalized * half_width) + half_width
def _scale_and_shift_inverse(self, zhat: Tensor) -> Tensor:
half_width = self._levels // 2
return (zhat - half_width) / half_width
def codes_to_indices(self, zhat: Tensor) -> Tensor:
"""Converts a `code` to an index in the codebook."""
assert zhat.shape[-1] == self.codebook_dim
zhat = self._scale_and_shift(zhat)
return (zhat * self._basis).sum(dim=-1).to(int32)
def indices_to_codes(
self,
indices: Tensor,
project_out=True
) -> Tensor:
"""Inverse of `codes_to_indices`."""
is_img_or_video = indices.ndim >= (3 + int(self.keep_num_codebooks_dim))
indices = rearrange(indices, '... -> ... 1')
codes_non_centered = (indices // self._basis) % self._levels
codes = self._scale_and_shift_inverse(codes_non_centered)
if self.keep_num_codebooks_dim:
codes = rearrange(codes, '... c d -> ... (c d)')
if project_out:
codes = self.project_out(codes)
if is_img_or_video:
codes = rearrange(codes, 'b ... d -> b d ...')
return codes
@autocast(enabled=False)
def forward(self, z: Tensor) -> Tensor:
"""
einstein notation
b - batch
n - sequence (or flattened spatial dimensions)
d - feature dimension
c - number of codebook dim
"""
orig_dtype = z.dtype
is_img_or_video = z.ndim >= 4
# make sure allowed dtype
if z.dtype not in self.allowed_dtypes:
z = z.float()
# standardize image or video into (batch, seq, dimension)
if is_img_or_video:
# 将图片和视频的空间、时间维度展平
z = rearrange(z, 'b d ... -> b ... d')
z, ps = pack_one(z, 'b * d')
assert z.shape[-1] == self.dim, f'expected dimension of {self.dim} but found dimension of {z.shape[-1]}'
z = self.project_in(z)
z = rearrange(z, 'b n (c d) -> b n c d', c=self.num_codebooks)
codes = self.quantize(z)
print(f"codes: {codes}")
indices = self.codes_to_indices(codes)
codes = rearrange(codes, 'b n c d -> b n (c d)')
out = self.project_out(codes)
# reconstitute image or video dimensions
if is_img_or_video:
out = unpack_one(out, ps, 'b * d')
out = rearrange(out, 'b ... d -> b d ...')
indices = unpack_one(indices, ps, 'b * c')
if not self.keep_num_codebooks_dim:
indices = rearrange(indices, '... 1 -> ...')
# cast back to original dtype
if out.dtype != orig_dtype:
out = out.type(orig_dtype)
# return quantized output and indices
return out, indices

















 2265
2265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









