








在进行实际编码之前,我们先介绍下深度学习的三个要素:
李航博士曾在《统计机器学习》中提到:
统计学习方法三要素:模型、策略和算法.
我认为深度学习也有这三要素:
1.模型也就是假设空间
在深度学习领域,模型包括网络结构和网络中的参数(权重和偏置等)。通常所说的CNN,RNN其实就是模型,但只是深度学习的一个要素而已,只有模型是没办法学习的。在CNN被提出之时,并没有提出相应的学习策略和优化算法因而并没有取得很好的效果。
2.策略就是损失函数
策略就是从数学角度上衡量模型的好坏,把一个模型的优劣进行量化。对应的就是模型的损失函数,对于不同的问题要用不同的损失函数,分类问题一般用对数似然损失函数,而回归问题一般用平方损失函数。
3.算法就是梯度下降优化的方法
算法是指学习模型参数的具体计算方法,也就是最优参数的过程。很多人在问机器学习到底是怎么学习的,参数寻优就是通常所说的学习过程。
模型和策略共同定义了一个目标函数,算法的任务就是找到在训练样本上使目标函数最小的参数,所以这已经是最优化的内容。
深度学习最常用的算法就是梯度下降法,目前也有了很多改进的基于梯度下降的算法,比如Momentum、RMSprop、Adam等。(PS:后面有机会可能会对这几种算法做一些介绍)
接下来先介绍此分类任务所使用到的MNIST 数据集。
MNIST 数据集
MNIST 数据集是一个手写数字数据集,在机器学习入门学习中极具代表性。可以手动从官网 http://yann.lecun.com/exdb/mnist/ 下载该数据集,然后在本地进行读取,但事实上 TensorFlow 中提供了一个类来处理 MNIST 数据 ,这个类会自动下载数据集并将数据从原始的数据包中解析成训练和测试神经网络时使用的格式 。
MNIST 数据集包含了四个部分:

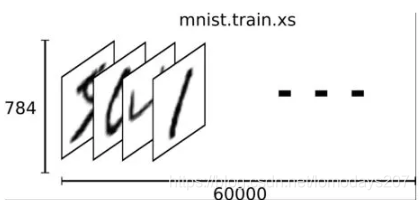
MNIST 数据集被分为训练数据集(60000张手写数字图片)和测试数据集(10000张手写数字图片)。
train-images-idx3-ubyte.gz 训练集图片 - 55000 张训练图片, 5000张验证图片
train-labels-idx1-ubyte.gz 训练集图片对应的数字标签
t10k-images-idx3-ubyte.gz 测试集图片 - 10000 张图片
t10k-labels-idx1-ubyte.gz 测试集图片对应的数字标签
MNIST 数据集来自美国国家标准与技术研究所,National Institute of Standards and Technology (NIST)。训练集 (training set) 由来自 250 个不同人手写的数字构成,其中 50% 是高中学生,50% 来自人口普查局 (the Census Bureau) 的工作人员。测试集(test set) 也是同样比例的手写数字数据。每一张图片包含 2828 个像素,图片里的某个像素的强度值介于0-1之间。例如 ,数字 1 对应一个 2828 像素图片,其像素强度如下:
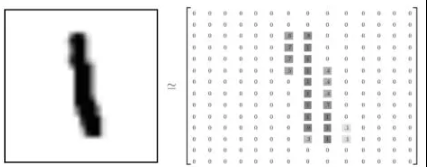

我们把这一个数组展开成一个向量 ,长度是 28*28=784 。因此在MNIST训练数据集中 mnist.train.images 是一个形状为 [60000, 784] 的张量,第一个维度数字代码样本的个数,用来索引图片,第二个维度数字代表真实的样本,也就是每张图片中的像素点。
实战搭建RNN网络模型
如何使用RNN进行mnist的分类呢?其实对应到RNN里面就是个Sequence Classification问题。先看下CS231n中关于RNN部分的一张图:

其实图像的分类对应上图就是个many to one的问题,对于mnist来说其图像的size是28*28,RNN需要序列数据,我们将每个图像的row视为一个像素序列,如果将其看成28个step,每个step的size是28的话,是不是刚好符合上图?当我们得到最终的输出的时候将其做一次线性变换就可以加softmax来分类了,其实还是比较清楚明了的。
1.获取数据集
利用 TF 框架自带类进行下载读取 。
import tensorflow as tf
# Import MNIST data
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot=True)
2.定义变量以及超参数
# 训练超参数
learning_rate = 0.001
training_steps = 10000
batch_size = 128
display_step = 200
# RNN模型结构 Parameters
num_input = 28 # MNIST data input (img shape: 28*28)
timesteps = 28 # timesteps
num_hidden = 128 # 隐藏层的大小
num_classes = 10 # MNIST total classes (0-9 digits)
# tf Graph input
#X和Y表示输入的image和label
X = tf.placeholder("float", [None, timesteps, num_input])
Y = tf.placeholder("float", [None, num_classes])
# 定义初始化权重
weights = {
'out': tf.Variable(tf.random_normal([num_hidden, num_classes]))
}
biases = {
'out': tf.Variable(tf.random_normal([num_classes]))
}
3.定义RNN网络
def RNN(x, weights, biases):
# 处理数据的shape,满足TF框架中rnn的输入参数要求
# 当前的输入数据格式为: (batch_size, timesteps, n_input)
# 需要的格式: 'timesteps' tensors list of shape (batch_size, n_input)
# Unstack to get a list of 'timesteps' tensors of shape (batch_size, n_input)
#tf.unstack()则是一个矩阵分解的函数 axis=1表示对列进行分解
x = tf.unstack(x, timesteps, axis=1)
#tf中RNN有很多的变体,最出名也是最常用的就是: LSTM和GRU
#定义一个 lstm cell
lstm_cell = rnn.BasicLSTMCell(num_hidden, forget_bias=1.0)
# 得到lstm cell的输出
outputs, states = rnn.static_rnn(lstm_cell, x, dtype=tf.float32)
# Linear activation, using rnn inner loop last output
return tf.matmul(outputs[-1], weights['out']) + biases['out']
4.训练和测试
logits = RNN(X, weights, biases)
prediction = tf.nn.softmax(logits)
# 定义损失函数和优化器
loss_op = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(
logits=logits, labels=Y))
optimizer=tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
train_op = optimizer.minimize(loss_op)
# 评估模型 (with test logits)
#tf.argmax 返回一维张量中最大值所在位置 ,若某一张图片数据的 label 和对该图片的预测最大值在同一个位置(例如数字 3 ,预测结果和 label 对应的 one-hot 向量都为[0,0,0,1,0,0,0,0,0,0]),此时 tf.equal 则返回值为 1 ,反之为 0 。即预测正确为 1 ,错误为 0 。
correct_pred = tf.equal(tf.argmax(prediction, 1), tf.argmax(Y, 1))
#对所有的correct_prediction 求平均值
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
# 初始化所有的变量
init = tf.global_variables_initializer()
然后在会话 Session 中执行 。代码如下 :
with tf.Session() as sess:
# Run the initializer
sess.run(init)
for step in range(1, training_steps+1):
batch_x, batch_y = mnist.train.next_batch(batch_size)
# Reshape data to get 28 seq of 28 elements
batch_x = batch_x.reshape((batch_size, timesteps, num_input))
# 执行优化器
sess.run(train_op, feed_dict={X: batch_x, Y: batch_y})
if step % display_step == 0 or step == 1:
# 计算损失和精确度
loss, acc = sess.run([loss_op, accuracy], feed_dict={X: batch_x,
Y: batch_y})
print("Step " + str(step) + ", Minibatch Loss= " + \
"{:.4f}".format(loss) + ", Training Accuracy= " + \
"{:.3f}".format(acc))
print("Optimization Finished!")
# 测试模型用128个mnist test images
test_len = 128
test_data = mnist.test.images[:test_len].reshape((-1, timesteps, num_input))
test_label = mnist.test.labels[:test_len]
print("Testing Accuracy:", \
sess.run(accuracy, feed_dict={X: test_data, Y: test_label}))
5.总结
机器学习的三要素(模型、策略、算法)再加上输入数据构成了一个完整的流水线,任何形式的机器学习任务都可以抽象出以上的几个部分。其实最好的方式是将进行模块化,比如损失函数、优化器等单独作为一个模块抽离出来,这样搭建深层网络就像搭积木一样,由于这次项目网络较浅,所以就没有实现,网络模块化结构会更清晰,代码的复用性也更强。
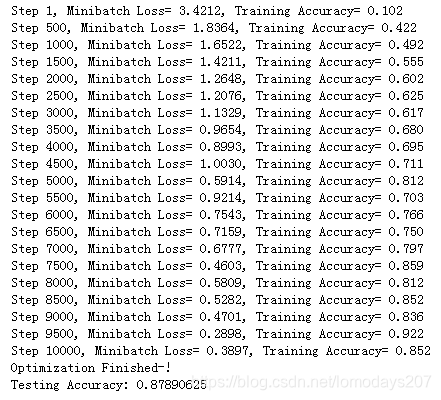
执行了10000个step之后的结果已经到88%左右,大家可以多训练一会看看最终效果。
如有任何疑问需要交流,或者需要完整代码,可以在公号后台留言或回复关键词【rnn】即可获取 。















 307
307











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









