







前言
TensorFlow 是一个用于研究和生产的开放源代码机器学习库,提供了各种级别的 API,供大家自由选择。
高阶 API:
1.Keras (快速设计原型、模块化代码)
2.Eager Execution (命令式编程环境,可立即输入结果,无需构建图)
低阶 API:
1.张量
2.session会话
…
TensorFlow 官方网站推荐使用的高阶 API 进行构建机器学习模型,但是对于初学者来说,能够直接使用低阶 TensorFlow 操作,实验和调试都会更直接,并且在以后使用更高阶的 API 时,能够更好的理解其内部工作原理。
本篇文章将讲解 TensorFlow 中低阶 API 涉及到基本概念,包括张量tensor、数据流图data flow graph、session等。
整体结构
Tensorflow 首先要定义神经网络的结构,然后再把数据放入结构当中去运算和训练。
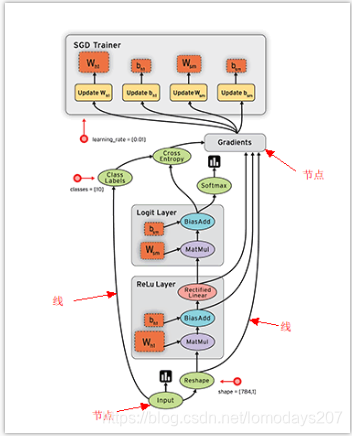
因为TensorFlow是采用数据流图来计算, 所以我们得创建一个数据流流图,然后再将我们的数据放在数据流图中计算,节点(Nodes)在图中表示数学操作(OP), 训练模型时数据tensor会不断的从数据流图中的一个节点flow到另一节点, 这就是TensorFlow名字的由来。
张量
张量有多种:零阶张量为纯量或标量 (scalar) 也就是一个数值,比如 [1]
一阶张量为 向量 (vector), 比如 一维的 [1, 2, 3]
二阶张量为 矩阵 (matrix), 比如 二维的 [ [1, 2, 3],[4, 5, 6],[7, 8, 9] ]
以此类推, 还有 三阶 三维的 …
TensorFlow 使用 numpy 阵列来表示张量值。
变量
TensorFlow 变量是表示程序处理的共享持久状态的最佳方法。
创建变量的最佳方式是调用 tf.get_variable 函数,要使用 tf.get_variable 创建变量,只需提供名称和形状即可。
my_variable = tf.get_variable("my_variable", [1, 2, 3])
这将创建一个名为“my_variable”的变量,该变量是形状为 [1, 2, 3] 的三维张量。默认情况下,此变量将具有 dtypetf.float32,其初始值将通过 tf.glorot_uniform_initializer 随机设置。
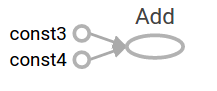
计算图
计算图是排列成一个图的一系列 TensorFlow 指令,图由两种类型的对象组成。
- 操作(简称“op”):图的节点。操作描述了消耗和生成张量的计算。
- 张量:图的边。它们代表将流经图的值,大多数 TensorFlow 函数会返回 tf.Tensors。
a = tf.constant(3.0, dtype=tf.float32)
b = tf.constant(4.0) # also tf.float32
total = a + b
print(a) #Tensor("Const:0", shape=(), dtype=float32)
print(b) #Tensor("Const_1:0", shape=(), dtype=float32)
print(total) #Tensor("add:0", shape=(), dtype=float32)
我们可以看出,打印张量并不是预期的那样输出值 3.0、4.0 和 7.0。上述语句只会构建计算图,这些 tf.Tensor 对象仅代表将要运行的操作的结果。
以上代码的计算图如下:
会话 (Session)
要计算张量,需要实例化一个 tf.Session 对象,会话会封装 TensorFlow 运行时的状态,并运行 TensorFlow 操作。
下面的代码会创建一个 tf.Session 对象,然后调用其 run 方法来计算我们在上文中创建的 total 张量:
sess = tf.Session()
print(sess.run(total)) # 7.0
print(sess.run({'ab':(a, b), 'total':total}))
#{'total': 7.0, 'ab': (3.0, 4.0)}
placeholder 占位符
Tensorflow 如果想要从外部传入data, 那就需要用到 tf.placeholder(), 它是 Tensorflow 中的占位符,暂时储存变量就像函数参数一样,然后以这种形式传输数据 sess.run(**, feed_dict={input: *}).
x = tf.placeholder(tf.float32)
y = tf.placeholder(tf.float32)
z = x + y
print(sess.run(z, feed_dict={x: 3, y: 4.5})) # 7.5
print(sess.run(z, feed_dict={x: [1, 3], y: [2, 4]}))
#[ 3. 7.]
一个例子平面拟合
通过本例可以使用TensorFlow基本API来进行一个线性模型的拟合机,也可以看出机器学习的一个通用过程:1.准备数据 -> 2.构造模型(设置求解目标函数) -> 3.求解模型
import tensorflow as tf
import numpy as np
# 1.准备数据:使用 NumPy 生成假数据(phony data), 总共 200 个点.
x_data = np.float32(np.random.rand(2, 200)) # 随机输入
y_data = np.dot([0.1, 0.2], x_data) + 0.3
# 2.构造一个线性模型
b = tf.Variable(tf.zeros([1]))
W = tf.Variable(tf.random_uniform([1, 2], -1.0, 1.0))
y = tf.matmul(W, x_data) + b
# 3.求解模型
# 设置损失函数:误差的均方差
loss = tf.reduce_mean(tf.square(y - y_data))
# 选择梯度下降的方法
optimizer = tf.train.GradientDescentOptimizer(0.5)
# 迭代的目标:最小化损失函数
train = optimizer.minimize(loss)
############################################################
# 以下是用 tf 来解决上面的任务
# 初始化变量:tf 的必备步骤,主要声明了变量,就必须初始化才能用
init = tf.global_variables_initializer()
# 3.迭代,反复执行上面的最小化损失函数这一操作(train op),拟合平面
# Launch the default graph.
with tf.Session() as sess:
sess.run(init)
for step in range(0, 201):
sess.run(train)
if step % 20 == 0:
print(step, sess.run(W), sess.run(b))
# 得到最佳拟合结果 W: [[0.100 0.200]], b: [0.300]















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









