







文章目录
书接上篇Kaggle之泰坦尼克号(1),上面提到的解决方案一经过特征工程、模型直接预测(0.78229)、优化超参数(0.78468),精度提升了0.2个百分点,最终精度排名为1700/14296(11.89%),下面说明基于特征工程的解决方案二。
解决方案二:
score:0.79425
Leaderboard:1244/14296(8.7%)
一、特征工程
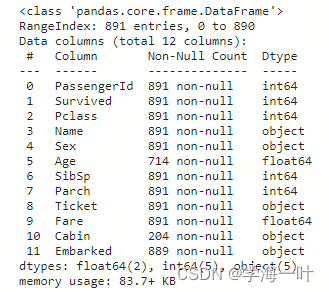
训练集一共提供11个特征包括6个数值型数据,5个文本型数据:
- 数值型:PassengerId(乘客ID)、Pclass(乘客等级)、Age(年龄)、SibSp(堂兄弟妹个数)、Parch(父母与小孩的个数)、Fare(票价)
- 文本型:Name(姓名)、Sex(性别)、Ticket(船票信息)、Cabin(船舱信息)、Embarked(登船港口)
缺失值处理
数据缺失情况
训练集
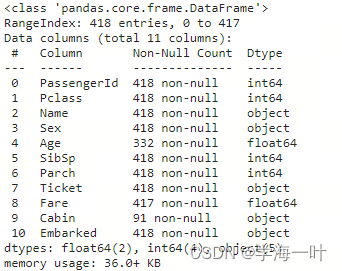
测试集
#对数据进行简单的预处理
#对fare缺失值使用均值替换
train_Fare_mean=train["Fare"].mean()
test.loc[test["Fare"].isnull()==True,"Fare"]=train_Fare_mean
#检验对test中fare空值是否替换完成
print("test对fare空值替换后为:\n",test.isnull().sum())
#对train中的embarked进行缺失值替换
train_embarked_mode=train["Embarked"].mode()
train.loc[train["Embarked"].isnull()==True,"Embarked"]=train_embarked_mode[0]
#检验成功对train的Embarked缺失值进行替换
print("train替换Embarked缺失值后为:\n",train.isnull().sum())
#对train\test中age数据采取mean替换
train.loc[train["Age"].isnull()==True,"Age"]=train["Age"].mean()
test.loc[test["Age"].isnull()==True,"Age"]=train["Age"].mean()
#验证train\test中Age缺失值补充完毕
print("补充train中Age后:\n",train.isnull().sum())
print("补充test中Age后:\n",test.isnull().sum())
#数据分割,模拟训练集和测试集的关系
label = train['Survived']
train.drop('Survived',axis=1,inplace=True)
X_train,X_test,Y_train,Y_test = train_test_split(train,label,test_size = 0.3,random_state = 1)
X_train['Survived'] = Y_train
X_test['Survived'] = Y_test
文本型数据处理-Sex
# 对sex进行编码 male==1,female==0
train['Sex'] = train['Sex'].apply(lambda x: 1 if x == 'male' else 0)
test['Sex'] = test['Sex'].apply(lambda x: 1 if x == 'male' else 0)
train = pd.get_dummies(data= train,columns=['Sex'])
test = pd.get_dummies(data= test,columns=['Sex'])
文本型数据处理-Name
- 名称类别对存活的影响(编码)
- 名称长度对存活的影响
# Name 名字开头的数量
def Name_Title_Code(x):
if x == 'Mr.':
return 1
if (x == 'Mrs.') or (x=='Ms.') or (x=='Lady.') or (x == 'Mlle.') or (x =='Mme'):
return 2
if x == 'Miss':
return 3
if x == 'Rev.':
return 4
return 5
X_train['Name_Title'] = X_train['Name'].apply(lambda x: x.split(',')[1]).apply(lambda x: x.split()[0])
X_test['Name_Title'] = X_test['Name'].apply(lambda x: x.split(',')[1]) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 691
691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











