 马尔可夫相关模型与概念详解
马尔可夫相关模型与概念详解





 本文从马尔可夫概念入手,介绍了马尔可夫模型的基本概念,包括马尔可夫性和马尔可夫过程。详细讲解了马尔可夫链、隐马尔可夫模型、马尔可夫决策过程和马尔可夫随机场的定义、特点和应用,并通过具体例子进行说明,如餐厅供应、网格世界机器人等。
本文从马尔可夫概念入手,介绍了马尔可夫模型的基本概念,包括马尔可夫性和马尔可夫过程。详细讲解了马尔可夫链、隐马尔可夫模型、马尔可夫决策过程和马尔可夫随机场的定义、特点和应用,并通过具体例子进行说明,如餐厅供应、网格世界机器人等。
文章目录
前言
前文提到了强化学习源自马尔可夫决策过程,本文从马尔可夫概念入手,讲解和马尔可夫有关的模型和概念。
一、基本概念
马尔科夫模型是一个很大的概念,从模型的定义和性质来看,具有马尔科夫性质、并以随机过程为基础模型的随机过程/随机模型被统称为马尔科夫模型,其中就包含我们悉知的马尔科夫链、马尔科夫决策过程、隐马尔科夫链(HMM)和马尔科夫随机场等随机过程/随机模型。
一个随机过程中,在已知它所处的状态的条件下,它未来的演变不依赖于它以往的演变。这种已知“现在”的条件下,“将来”与“过去”独立的特性称为马尔可夫性(Markov Property),具有这种性质的随机过程叫做马尔可夫过程(Markov Process)。
举例来说,青蛙在荷花池里跳跃的过程中,青蛙依照它瞬间的念头从一片荷叶上跳到另一片荷叶上,因为青蛙是没有记忆的,当所处的位置已知时,它下一步跳往何处和它以往走过的路径无关。因此,后续的演变不依赖于以往的演变,则该过程即为马尔可夫过程。该过程仅依赖当前时刻状态,又称为1阶马尔科夫过程,很容易将定义拓展的多阶的情况。
n阶马尔科夫过程是状态间的转移仅依赖于前n个状态的随机过程。这个过程被称之为n阶马尔科夫模型,其中n是影响下一个状态选择的(前)n个状态,气象预报就可以是一个n阶马尔科夫过程。
二、马尔科夫链(Markov Chain)
马尔可夫链 是具有马尔可夫性质的随机变量的一个数列,即描述了一种状态序列,其每个状态值取决于前面有限个状态。下面讲述马尔可夫链的相关概念:
- 马尔可夫性质(Markov Property):马尔可夫链的关键特征是马尔可夫性质,即系统在任意时间 n+1 的状态仅依赖于时间 n 的状态,而与之前的状态历史无关。这可以用以下数学表示: P ( X n + 1 = x ∣ X 0 , X 1 … , X n ) = P ( X t + 1 = X ∣ X n ) P(X_{n+1}=x∣X_0,X_1…,X_n)=P(X_{t+1}=X∣X_n) P(Xn+1=x∣X0,X1…,Xn)=P(Xt+1=X∣Xn)。
- 状态空间(State Space):状态空间是马尔可夫链可能的状态集合,通常用 S S S 表示。状态可以是离散的(如有限状态空间)或连续的(如状态可以取任意实数值)。
- 状态转移矩阵(Transition Matrix):状态转移矩阵用于描述状态之间的转移概率。对于有限状态空间的马尔可夫链,状态转移矩阵是一个方阵,其元素 P(i, j) 表示从状态 i 转移到状态 j 的概率。
- 平稳分布(Stationary Distribution):在某些情况下,马尔可夫链可能具有平稳分布,这是一个稳定的状态分布,不会随时间变化。平稳分布可以用来描述系统在长期运行后的状态分布。
- 初始概率分布:包含每个状态的初始概率。
以随机餐厅举例
假设有那么一个餐厅,其食品供应符合马尔科夫性质,每天只供应3个菜其中的一种,明天供应什么取决于今天供应了什么(一阶马尔可夫过程)
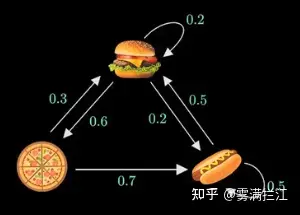
上图就是一个链的标记,其中的方向概率(准确说是频率)是来自大量数据记录统计
求解过程:披萨->汉堡->披萨->?,可以很容易得出
P(X4=热狗|X1=披萨,X2=汉堡,X3=披萨) = P(X4=热狗|X3=披萨) = 0.7
P(X4=汉堡|X1=披萨,X2=汉堡,X3=披萨) = P(X4=汉堡|X3=披萨) = 0.3
状态转移矩阵如下:

假设第一轮选择比萨,则初始概率分布为 π 0 = [ 0 1 0 ] \pi_0 = [0 \, 1 \, 0] π0=[010],迭代计算如下:


…
求解如下方程,即可得到平稳分布(可以理解为收敛)

上述矩阵乘法可转化为求下列方程的解:
{ 0.2 a + 0.3 b + 0.5 c = a 0.6 a = b 0.2 a + 0.7 b + 0.5 c = c a + b + c = 1 \begin{cases} 0.2a + 0.3b + 0.5c = a \\ 0.6a=b \\ 0.2a+0.7b+0.5c=c \\ a + b + c = 1 \end{cases} ⎩
⎨
⎧0.2a+0.3b+0.5c=a0.6a=b0.2a+0.7b+0.5c=ca+b+c=1
解为 [ 0.35211 0.21127 0.43662 ] [0.35211 \,\,\,\,\,\, 0.21127 \,\,\,\,\,\, 0.43662] [0.352110.211270.43662],即为初始状态为披萨的平稳分布。
三、隐马尔可夫模型(Hidden Markov Model,HMM)
在正常的马尔可夫模型中,状态对于观察者来说是直接可见的。这样状态的转换概率便是全部的参数。而在隐马尔可夫模型中,状态并不是直接可见的,但受状态影响的某些变量则是可见的。每一个状态在可能输出的符号上都有一概率分布,因此输出符号的序列能够透露出状态序列的一些信息。
HMM是一种用参数表示的用于描述随机过程统计特性的概率模型,它是一个双重随机过程。HMM 由两部分组成:马尔可夫链和一般随机过程。其中马尔可夫链用来描述状态的转移,用转移概率描述;一般随机过程用来描述状态与观察序列间的关系,用观察值概率描述。
还是以随机餐厅举例,但这次加入食物对宠物心情(观察序列)的影响
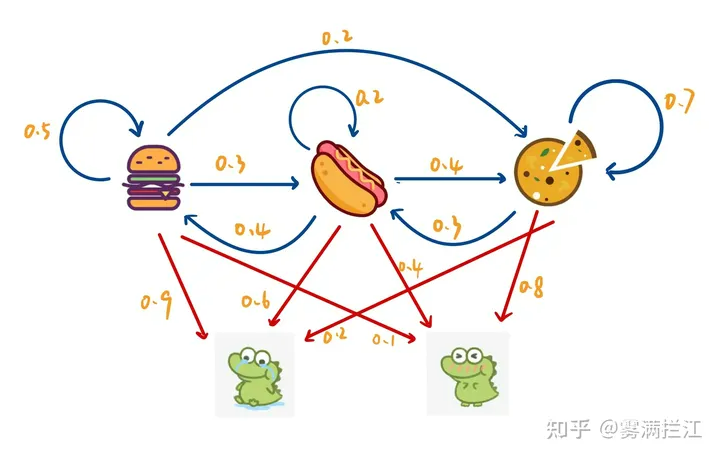
因此,虽然每日食物是随机的,但我们可以通过宠物心情(观察序列)来推断每日的食物(马尔科夫状态)是什么
现在假定观测序列为:开心->开心->难过,易知有3×3×3种概率序列
隐马尔科夫就是找最大限度的联合概率
a r g M A X X = x 1 , x 2 , ⋯ , x n P ( X = X 1 , X 2 , ⋯ , X n ∣ Y = Y 1 , Y 2 , ⋯ , Y n ) argMAX_ {X=x_ {1},x_ {2},\cdots ,x_ {n}} P(X= X_ {1} , X_ {2}, \cdots, X_ {n} |Y= Y_ {1}, Y_ {2}, \cdots, Y_ {n}) argMAXX=x1,x2,⋯,xnP(X=X1,X2,⋯,Xn∣Y=Y1,Y2,⋯,Yn)
其中,Y为观测变量,即宠物心情;X为状态,即随机食物
这是基底理论, 利用贝叶斯定律得
a r g M A X X = x 1 , x 2 , ⋯ , x n P ( Y ∣ X ) P ( X ) P ( Y ) argMAX_ {X=x_ {1},x_ {2},\cdots ,x_ {n}} \frac {P(Y|X)P(X)} {P(Y)} argMAXX=x1,x2,⋯,xn</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 4428
4428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











