







文章地址:R-FCN: Object Detection via Region-based Fully Convolutional Networks
读RFCN 前,必须先搞明白Faster-RCNN
解决的问题:
解决Faster RCNN 速度过慢的问题。因为faster-rcnn经过ROI pooling 之后的网络结构对roi proposal 不再是共享的。例如有300个proposal, 那么就要300次ROI后的全连接网络,耗时巨大。因此想把ROI后的网络结构往前移动,以此提升速度。
单纯的移动在网路加深后会引入平移可变性的问题,什么是平移可变性?
物体目标检测包括物体种类检测和物体的位置检测。在对物体种类检测时,我们希望能保持位置不敏感(translation invariance),也就是不管物体在哪个位置都能正确分类。在进行位置确定的时候,我们希望保持位置敏感(translation variance),也
就是不论物体发生什么样的位置变换都能确定物体的位置。
例如对于图片上的一只猫,平移不变性:这只猫在图片上任意一个位置滑动,在不同的位置最后分类出来是相同的。平移可变性:不同位置对猫回归的roi位置不同。
对于一个分类回归任务的网络:
1、希望分类具有平移不变性(位置不敏感):
针对的是分类任务。也就是物体在图像中不论如何平移,随着网络的加深,最后都能将其正确分类,而且是网络越深,分类能力越强。
2、希望回归具有平移可变性(位置敏感):
针对的是回归任务。也就是说物体图像上移动,希望网路预测框能和它一起移动,准确检测位置。更改预测框位置需要计算对应的偏差,以及预测bbox和GT的重合率。而深度全卷积网络不具备这种特性。这是由于网络变深后最后一层卷积输出的feature map 变小,物体在输入上的微小偏移,在最后的feature map 上是感知不到。
举个例子,以ResNet-101为主干的Faster R-CNN 网络。如果在Faster R-CNN中没有ROI池化层把RPN生成的Proposal映射到原特征图中缩小预测范围,直接对整个feature map进行分类和位置的回归,由于ResNet的结构较深,平移可变性较差,检测出来的坐标会极度不准确。如果ROI插在主干网络的中间,导致分类任务变差。
ROI pooling 破坏网络分类平移不变性:
因为POI带有位置截取信息,经过ROI截取之后,ROI对物体的感受野被截断,相同的物体经过ROI Pooling 可能得到不同的roi范围,所以经过ROI pooling 后正样本有可能被分为背景样本。且ROI pooling 越靠前,分类平移不变性被破坏越厉害。导致分类越不准确。
ROI pooling 靠前:分类不准
ROI pooling 靠后:回归不准
RFCN 解决方案:
解决神经网络对物体位置不敏感的问题,神经网络擅长提取图像的局部特征,不太关心局部特征所在的位置(我认为是因为卷积权值共享导致)。为了让神经网络做到物体检测,需要增加位置敏感特性。于是增加了位置敏感得分图。用来保证全卷积网路对物体位置的敏感性。
R-FCN的整体结构:
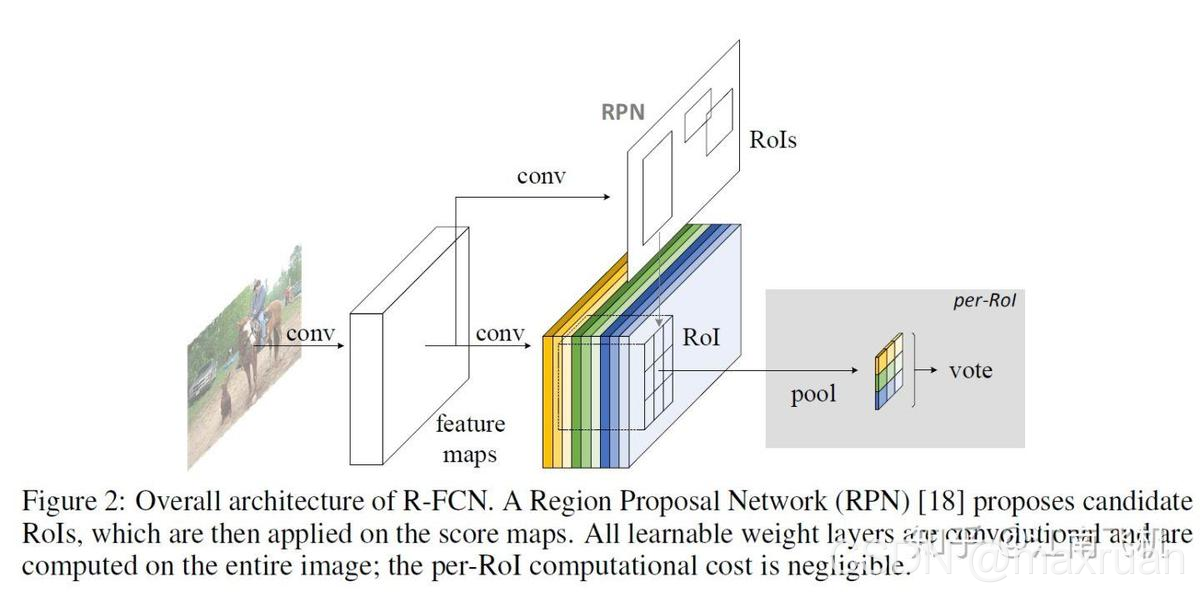
1、 backbone 特征提取网络提取特征featuremap1。
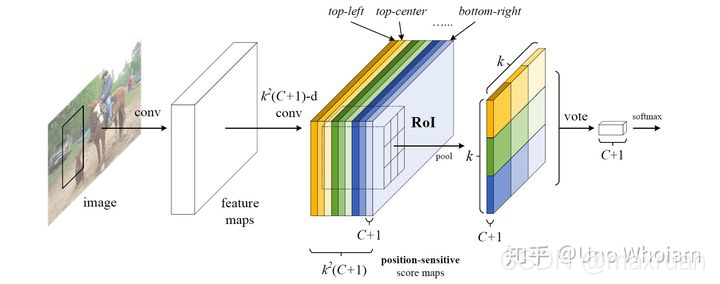
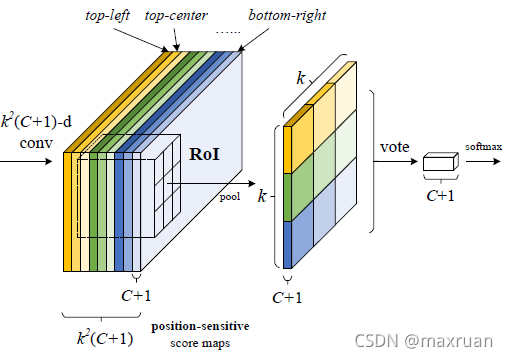
2、位置敏感卷积网络,从feature map 中得到 K* K * (C + 1)通道的同样大小的卷积网络。 K * K 为ROI的分块个数,例如 K = 3。 C为分类个数,+1 指向背景类。得到featuremap2
3、RPN
4、pooling,voting , softmax : 根据RPN产生的RoI(region proposal)在这些featuremap2上进行池化和打分分类操作,得到最终的检测结果
位置敏感分值图
假设每一类别的物体都是由相同数量的特征构成,这里选择特征数为 33 。例如人由(头,手,脚,身体…等33个部位),鸟由(头,腿,翅,尾…等3*3个部位),一张图的一个位置可以是人的头,也可能是鸟的翅膀,如果预测物体的类别为 C 类,加上背景,就是C+1类,那么这个位置就有 3x3x(C + 1)种可能性特征。
所以每一种可能性就建立一个特征分值图,专门预测这个特征在这个位置的响应。例如一张特征分值图专门预测这个位置是不是人的头部,如果这个位置真的是人的头部,那么这个位置的响应应该很高,如果,这个位置是鸟的翅膀,那么这个位置响应应该很低。
当我们要对一个ROI 进行类别预测时,就要收集每一个类别的概率,以往的网络都是直接预测。RFCN 则是通过各特征的响应pooling后得到类别响应概率。例如一个ROI,在求它属于人的响应时,需要先求它各个特征的响应,总共是3*3个特征。第i个特征响应应该在第 i 个特征分值图中。所以将ROI区域映射到第 i 个特征分值图中的位置,取出这个位置的特征响应值,如果响应值很高,那么表明ROI区域包含了人的第i个特征。
成功的位置敏感图如下图所示:
将feature map 分为3 * 3 个位置,每一个位置对应一个feature map,得到9层feature map, 每一层feature map 响应一个物体的感兴趣部位。 比如下图的上中(坐标(0,1))位置表示人体的头部响应。所有的位置响应经过一次池化后保存在右侧33(C+1)的对应位置(原来是中上位置池化后还是在中上位置),如此保存了位置敏感信息。

失败的位置敏感预测如下:由于红框中的pooling map 得分过低。

通道维度 = K * K*(c+1),加1表示有一类为背景类。
每一个类别对应到K*K维度,比如人对应0 ~ k * k维度,共K * K个scoremap,车对应到(K * k)~ 2 * (K * K) 维度。每个物体均对应K * K 个scoremap。
每个scoremap负责预测一个物体的一个部位。比如上图中,负责预测人的K * K个scoremap中的第一个scoremap 负责预测人的头部,第一张scoremap的响应值表示头部出现在该区域的得分。分值越大,表示头部出现在该位置的可能性越大。
ROI响应
得到每个类别每个部位的响应后如何进行ROI响应,以此判断该区域属于哪一个物体呢?
首先,由于一个sccore map 对应一个物体的一个部位,所以RoI的第 i 个子区域一定要到第 i 张score map上去找对应区域的响应值,因为RoI的第 i 个子区域需要的部位和第 i 张score map关注的部位是一样的。这样就找到了ROI 区域的 K * k 值。如果这些响应值都很高,说明这个ROI包含了该物体的各个部位,应该属于该物体。当然了,如果其他物体也很高,那就取响应最高的。如果各个物体的各个部位都响应低,那就是背景类了。
Position-sensitive RoI pooling
上面讲了池化过程,但是没有讲具体如何池化,也就是如何取 ROI K * K 区域的值。
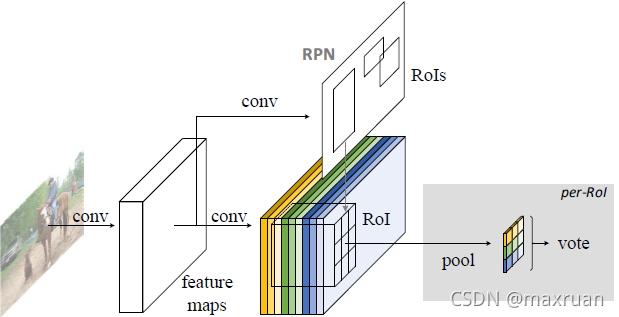
通过RPN提取出来的RoI区域,其是包含了“坐标、长宽”的4值属性的,也就是说不同的RoI区域能够对应到score map的不同位置上,而一个RoI会分成 k *k 个bins(也就是子区域。每个子区域bin的长宽分别是 h / k 和 w / k )
因为ROI 一个区域对应一个score map。所以池化应该在此score map上的子区域执行,且执行的是平均池化。第 i个bin应对在第 i 个score map上找响应值,那么也就是在第 i 个score map上的“该第 i 个bin对应的位置”上进行池化操作。
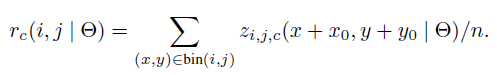
这里(x0, y0)为 ROI 区域的的左上角,(x,y) 在 bin(i, j) 的区间内,第(i, j)个区间 在特征分值图中 跨度为 ( i * w/k : (i+1) * w/k) , ( j * h/k : (j+1) * h/k) .
经过池化后,对 K*K 个位置敏感的分数在 RoI上投票。在本文中,我们简单地通过平均得分进行投票,为每个 RoI 生成(C+1) 维向量。然后我们跨类别计算 softmax 响应,交叉熵损失以及在推理期间对 RoI 进行排序。
网络训练结构图:
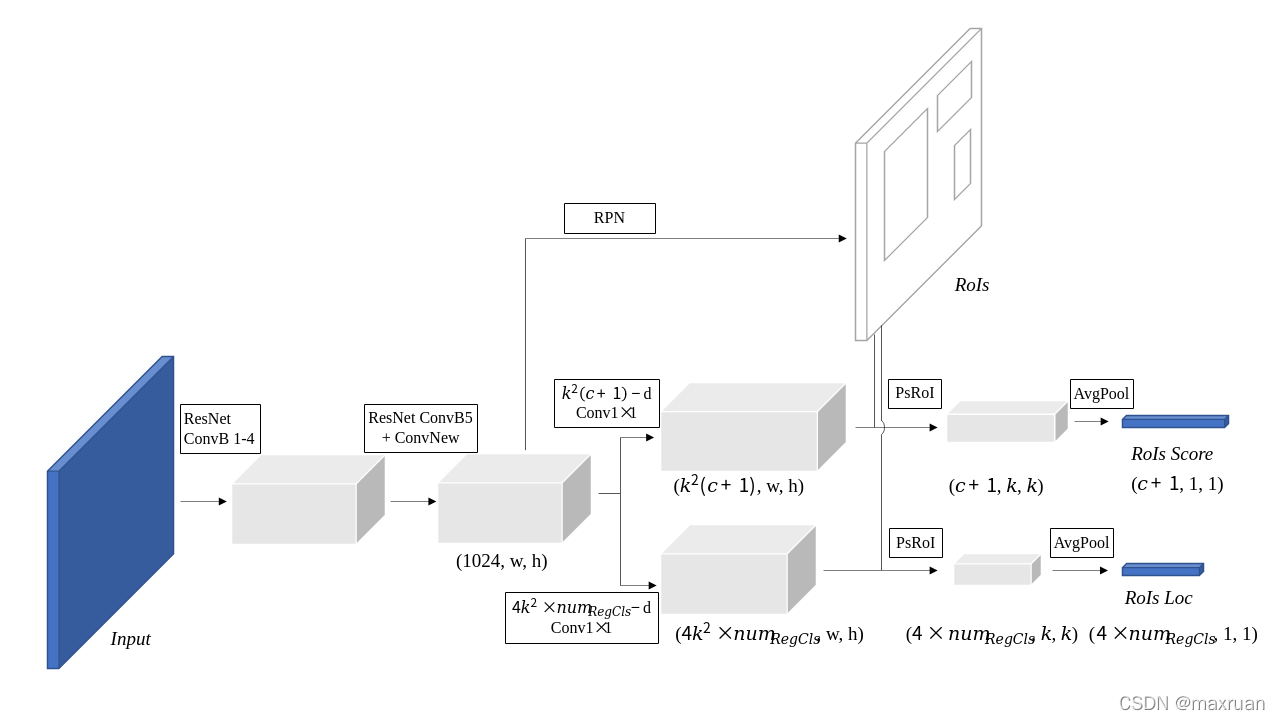
网络训练
为什么 position-sensitive score map 能够在某个物体的某个部位区域有高响应?
其实我理解这里的某个部位是虚拟出来的。比如将物体都分为3 * 3 = 9 个部位,这里每一个部位均代表了一种特征,而一个物体的识别就是由这些特征组合而成,而当在这个bbox中这些特征响应都很高时候,那么这个bbox表示这个物体的概率就会越大。
那么网络如何训练让这些表征物体特征的score具有高响应值呢?
首先假设一个ROI包含人,那么这个ROI经过positive-sensitive score map + position-sensitive ROI pooling 后得到C+ 1个值中属于人的分值在softmax 下必然变得很大,反推回去,就要要求 position-sensitive score map 中属于人的score map 的“该ROI对应的区域的平均值”尽可能大,从而要求score map 上该区域的响应值尽可能大。因为只有该区域的响应值大了,才能使得预测为人的概率大,才会降低softmax的loss。
训练和预测过程
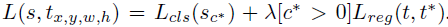
使用如上的损失函数,对于任意一个RoI,计算它的softmax损失,和“当其不属于背景时的回归损失”。这很简单,因为每个RoI都被指定属于某一个GT box或者属于背景,即先让GT box选择与其IoU最大的那个RoI,然后再对剩余RoI选择与GT box的IoU>0.5的进行匹配,而剩下的RoI全部为背景类别。那么RoI有了label后,loss自然很容易计算出来。
而唯一不同的就是,为了减少计算量,作者将所有RoIs的loss值都计算出来后,对其进行排序,并只对“最大的128个损失值对应的RoIs”执行反向传播操作,其它的则忽略。并且训练策略也是采用的Faster R-CNN中的4-step alternating training进行训练。
在测试的时候,为了减少RoIs的数量,作者在RPN提取阶段就将RPN提取的大约2W个proposals进行过滤:
1、去除超过图像边界的proposals
2、使用基于类别概率且阈值IoU=0.7的NMS过滤
3、按照类别概率选择top-N个proposals
所以在测试的时候,一般只剩下300个RoIs,当然这个数量是一个超参数。并且在R-FCN的输出300个预测框之后,仍然要对其使用NMS去除冗余的预测框。
以上与faster rcnn 基本相似。
ROI pooling 置后提速:
ROI pooling 放置后方,增加了不同ROI之间的的共享计算,减少每一个ROI单独计算的计算量,从而提高整体计算效率。














 970
970











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









