







01 资源
OpenCV自带的OCR端到端识别用例,opencv_contrib\modules\text\samples\end_to_end_recognition.cpp。end_to_end_recognition.cpp识别图片中的字符串。
模型文件(需要拷贝到Debug或Release目录中):
opencv_contrib/modules/text/samples/trained_classifierNM1.xml
opencv_contrib/modules/text/samples/trained_classifierNM2.xml测试图片:
opencv_contrib/modules/text/samples/scenetext_segmented_word01.jpg
opencv_contrib/modules/text/samples/scenetext_segmented_word01_mask.png
opencv_contrib/modules/text/samples/scenetext_segmented_word02.jpg
opencv_contrib/modules/text/samples/scenetext_segmented_word02_mask.png
opencv_contrib/modules/text/samples/scenetext_segmented_word03.jpg
opencv_contrib/modules/text/samples/scenetext_segmented_word03_mask.png
opencv_contrib/modules/text/samples/scenetext_segmented_word04.jpg
opencv_contrib/modules/text/samples/scenetext_segmented_word04_mask.png
opencv_contrib/modules/text/samples/scenetext_segmented_word05.jpg
opencv_contrib/modules/text/samples/scenetext_segmented_word05_mask.pngtesseract源码中的数据:tesseract\tessdata拷贝到目标目录。
把D:\git\DeepLearning\tesseract\tessdata拷贝到D:\git\opencv\build\v3.3.0\x64\bin\Debug\tessdata
还需要的tesseract数据eng.traineddata:
https://github.com/tesseract-ocr/tesseract/wiki/Data-Files
代码使用的3.05.01,这里下载3.05版本数据。
https://github.com/tesseract-ocr/tesseract/wiki/Data-Files#data-files-for-version-304305
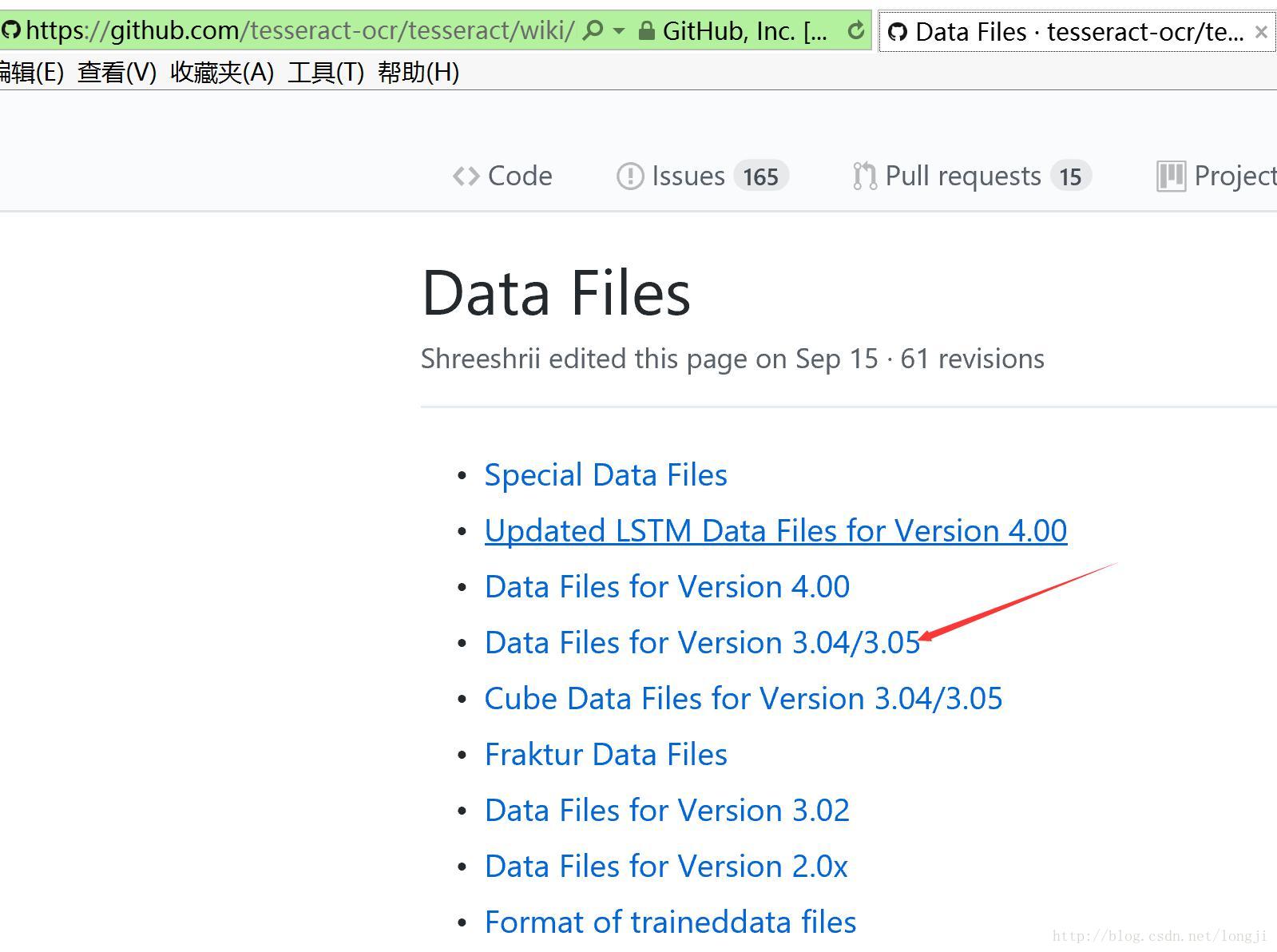
把eng.traineddata放到D:\git\opencv\build\v3.3.0\x64\bin\Debug\tessdata中。
02 编译配置tesseract
end_to_end_recognition使用tesseract做OCR端到端处理。
有blog说,只要安装tesseract开发版即可,没亲自测试。下载地址:https://digi.bib.uni-mannheim.de/tesseract/。
自己配置tesseract。自己编译的tesseract和leptonica,tesseract依赖leptonica。
下载leptonica、tesseract源码编译。
02.01 编译leptonica
下载代码
cd D:\git\DeepLearning
git clone https://github.com/DanBloomberg/leptonica.git
cd leptonica
git tag # 当前稳定版本1.74.4
# 切换到稳定版本
git checkout -b b1.74.4 1.74.4配置cmake
目标路径:D:/git/DeepLearning/leptonica/build/x64
BUILD_PROG=1
CMAKE_INSTALLPREFIX=D:/git/DeepLearning/leptonica/build/x64/install如果系统已经配置好了GIF/JPEG/ZLIB/PNG/TIFF等,勾选Advanced选项,把这几项相关的内容清空,这样会采用leptonica的默认配置。
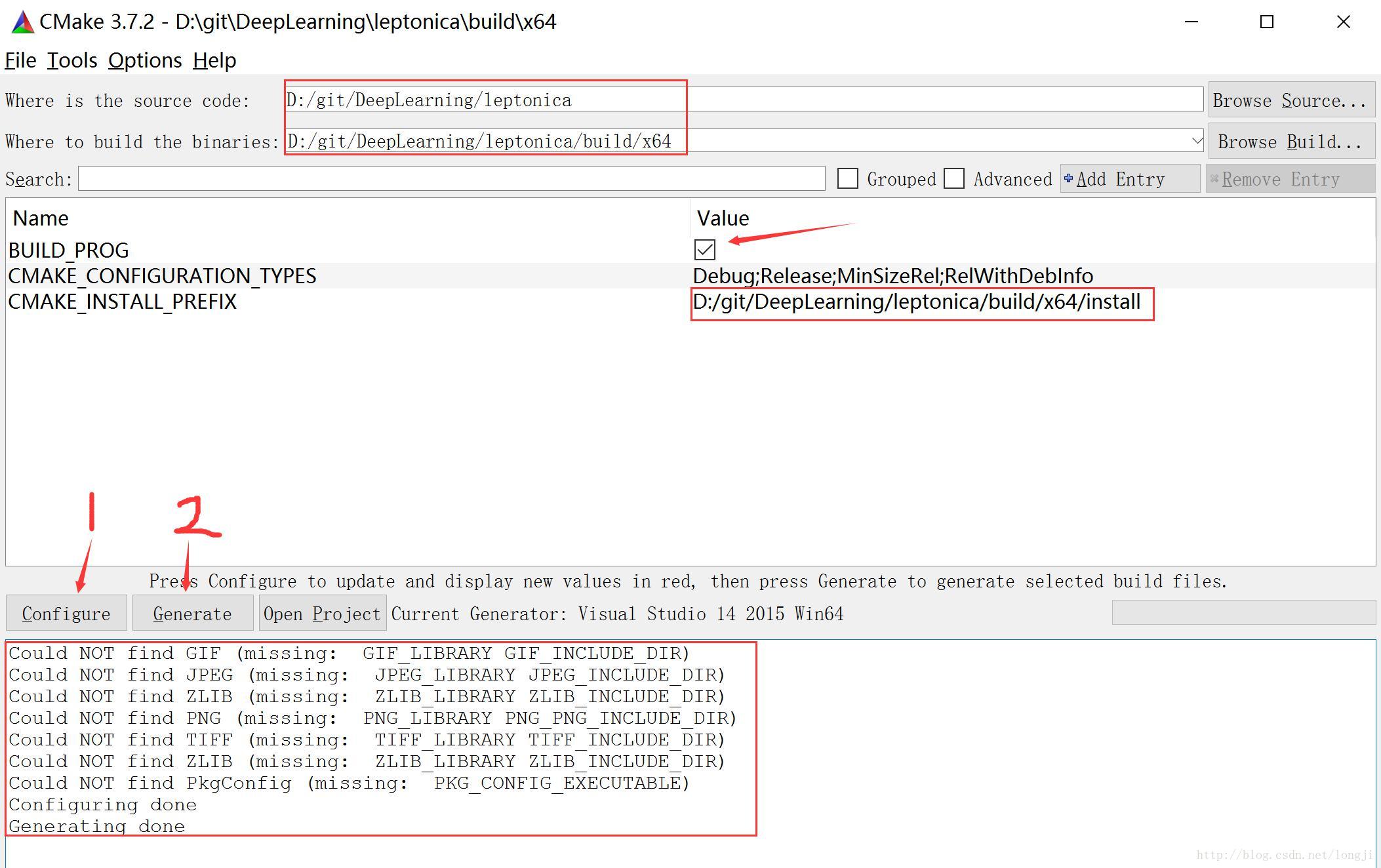
编译、安装
使用vs2015 update3 编译,并且运行INSTALL项目。把编译好的内容安装到D:/git/DeepLearning/leptonica/build/x64/install目录。
02.02 编译tesseract
下载代码
cd D:\git\DeepLearning
git clone https://github.com/tesseract-ocr/tesseract.git
cd tesseract
git tag # 当前稳定版本1.74.4
# 切换到稳定版本
git checkout -b b3.05.01 3.05.01配置cmake
目标路径:D:/git/DeepLearning/tesseract/build/x64
BUILD_TRAINING_TOOLS=1
CMAKE_INSTALL_PREFIX=D:/git/DeepLearning/tesseract/build/x64/install
Leptonica_DIR=D:/git/DeepLearning/leptonica/build/x64/install/cmake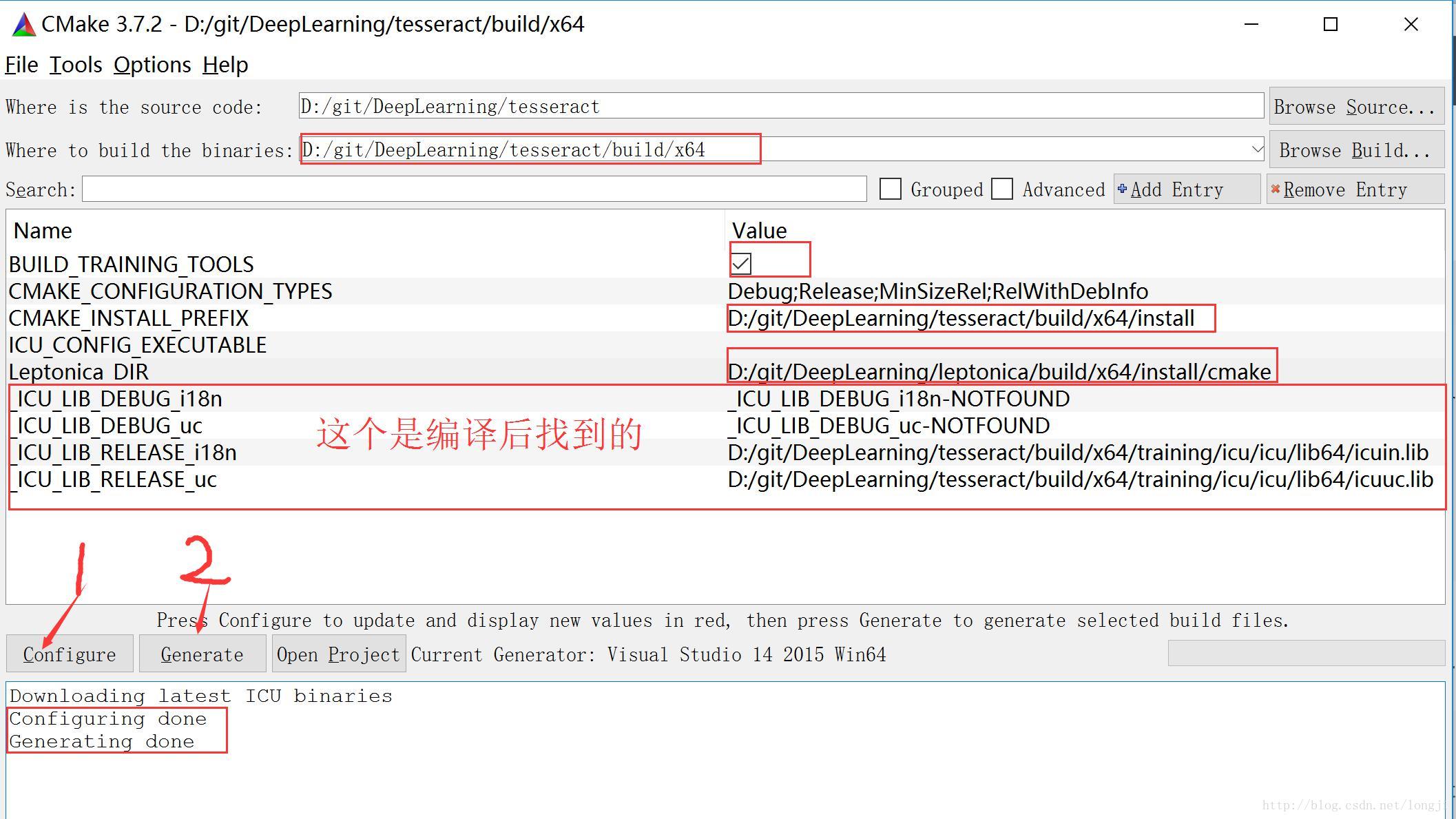
编译、安装
使用vs2015 update3 编译,并且运行INSTALL项目。把编译好的内容安装到D:/git/DeepLearning/tesseract/build/x64/install目录。
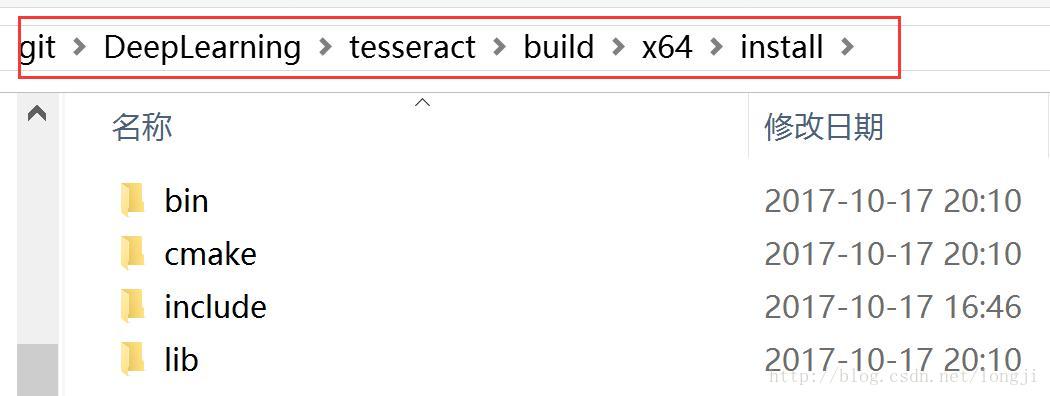
配置环境变量path
在系统path环境变量中追加
D:/git/DeepLearning/leptonica/build/x64/install
D:/git/DeepLearning/tesseract/build/x64/install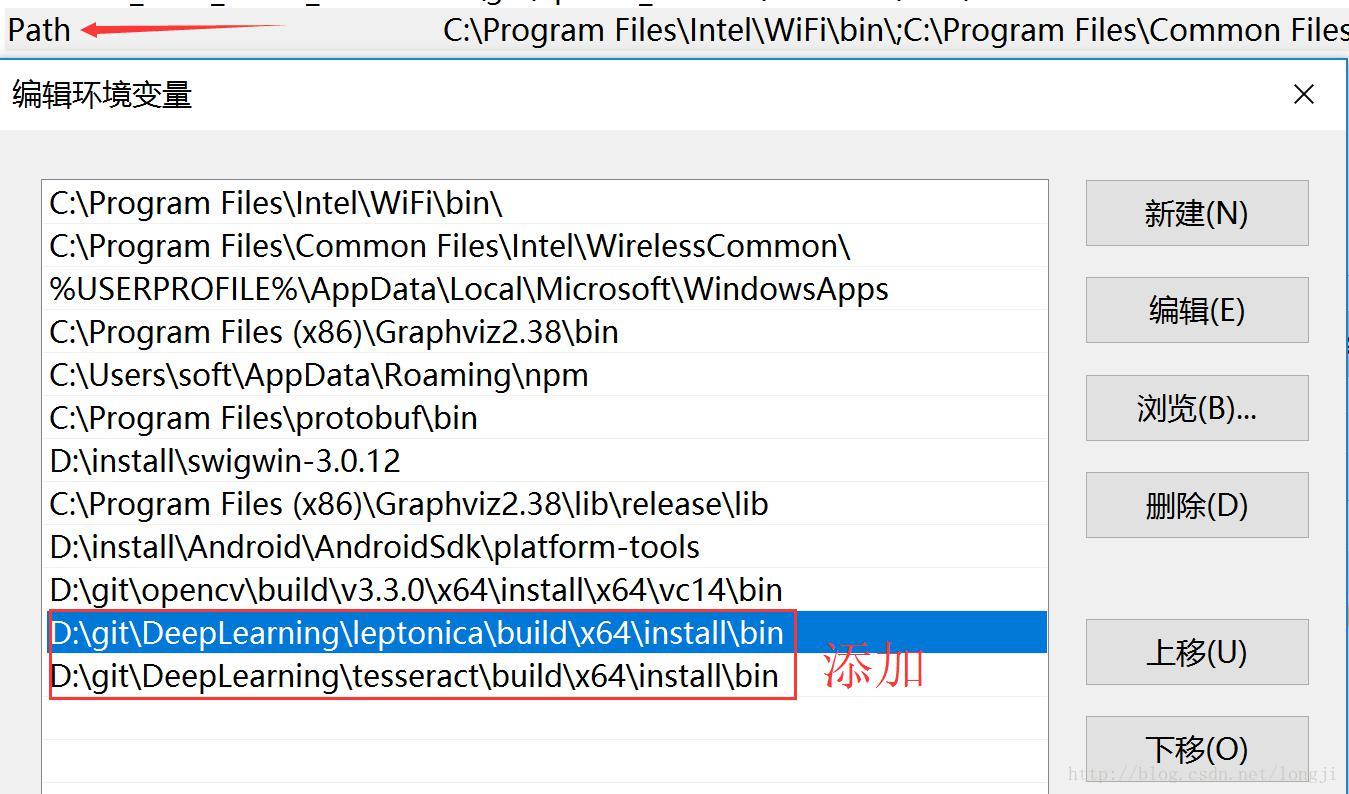
03 编译end_to_end_recognition
03.01配置opencv的cmake
opencv3.3.0的cmake配置,参考opencv01 相对完整的编译opencv3.3.0 win版本。这里并没有配置tesseract。
追加tesseract配置:
Lept_LIBRARY=D:/git/DeepLearning/leptonica/build/x64/install/lib/leptonica-1.74.4.lib
Tesseract_INCLUDE_DIR=D:/git/DeepLearning/tesseract/build/x64/install/include
Tesseract_LIBRARY=D:/git/DeepLearning/tesseract/build/x64/install/lib/tesseract305.lib
03.02 编译end_to_end_recognition
编译opencv3.3.0,生成文件:D:\git\opencv\build\v3.3.0\x64\bin\Debug\end_to_end_recognition.exe
03.03 配置end_to_end_recognition工程
设置end_to_end_recognition项目为启动项。
# 如果路径中有空格,需要使用双引号,参数路径根据自己实际情况调整
配置属性==>调试==>命令参数=../../../../../../opencv_contrib/modules/text/samples/scenetext_segmented_word01_mask.png
配置属性==>调试==>工作目录=$(OutDir)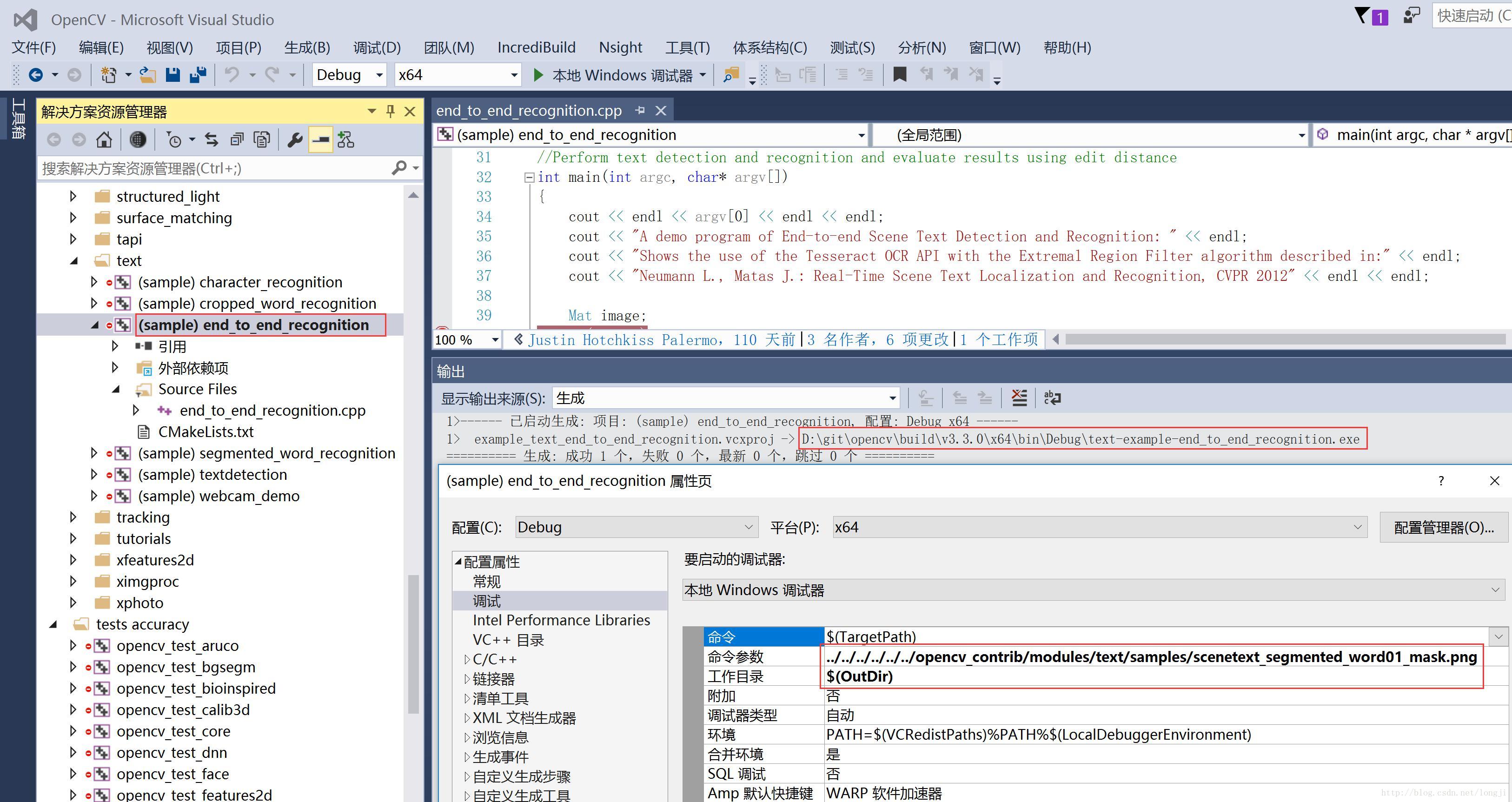
04 运行结果
04.01 scenetext_segmented_word01.jpg
scenetext_segmented_word01.jpg原图:
运行效果图:
A demo program of End-to-end Scene Text Detection and Recognition:
Shows the use of the Tesseract OCR API with the Extremal Region Filter algorithm described in:
Neumann L., Matas J.: Real-Time Scene Text Localization and Recognition, CVPR 2012
IMG_W=640
IMG_H=480
TIME_REGION_DETECTION = 14750.3
TIME_GROUPING = 4365.56
TIME_OCR_INITIALIZATION = 638.67
Empty page!!
Empty page!!
TIME_OCR = 907.957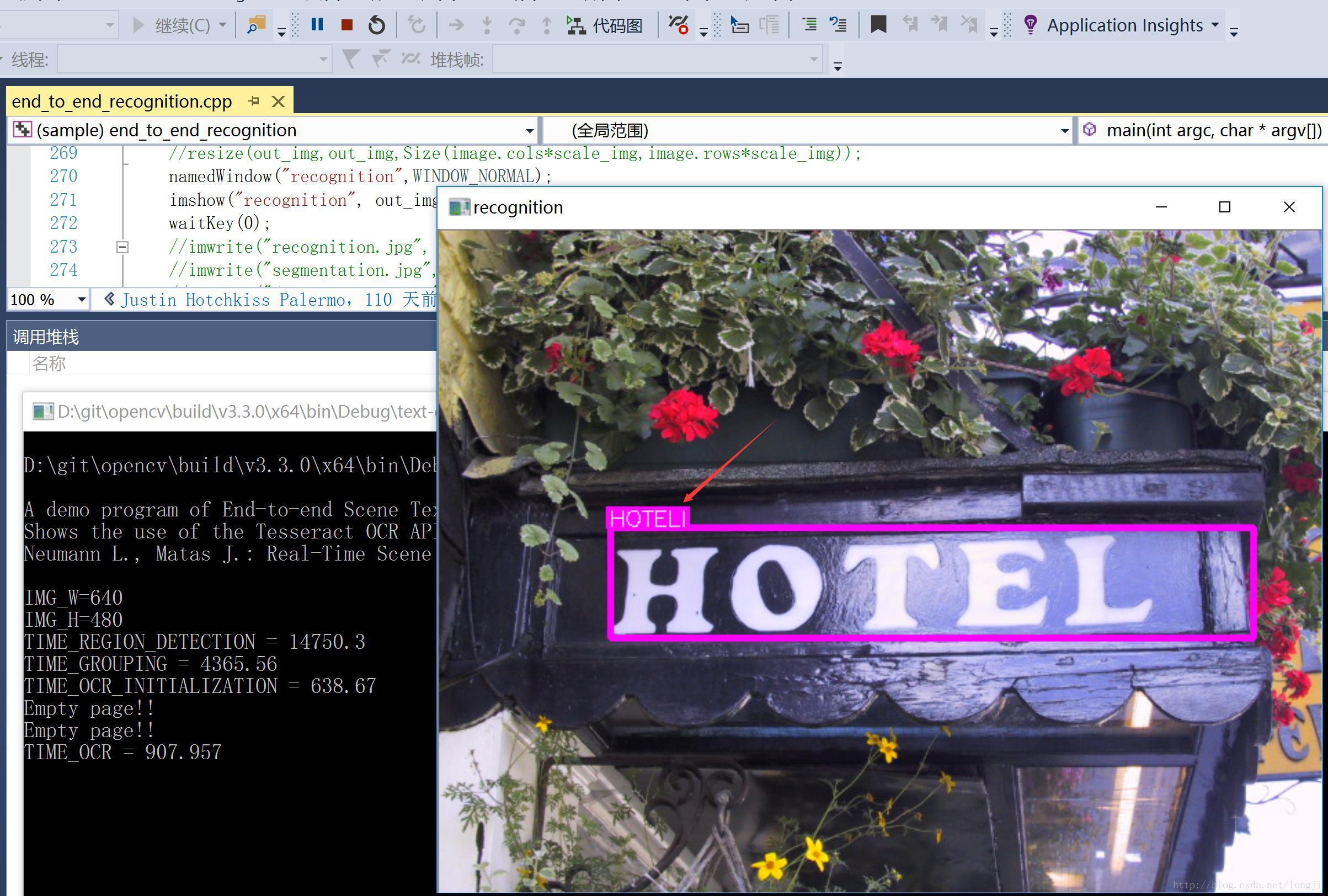
判断结果为”HOTELI”,多了一个字母”I”。
04.02 scenetext_segmented_word01_mask.png
scenetext_segmented_word01_mask.png原图:
运行效果图: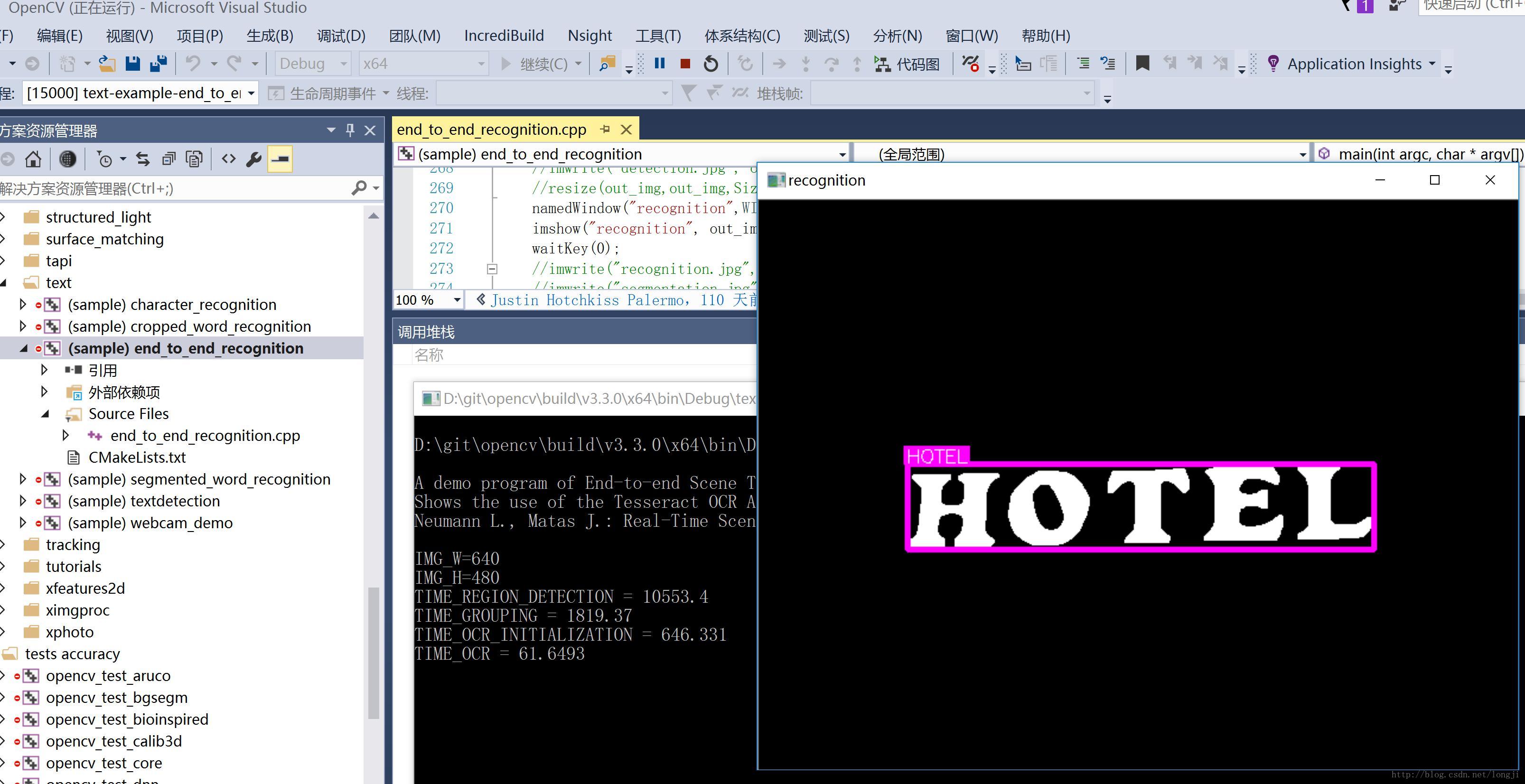
判断结果为”HOTEL”,准确。















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









