






Python爬虫爬取51job岗位信息
首先在python项目中需要有以下文件夹及文件
chromedriver.exe —> chromedriver.exe 是 Google Chrome 浏览器的 WebDriver。WebDriver 是一种自动化工具,用于模拟用户在浏览器中的操作。chromedriver.exe 是专门为 Chrome 浏览器设计的,它允许开发人员编写代码来控制浏览器的行为,从而进行自动化测试或自动执行某些任务
下载地址: ChromeDriver - WebDriver for Chrome (google.com)
ECommerceJobScraper.py —> 用于爬取页面内容
JobInfoExtractor.py —> 用于分析爬取下来的页面内容并进行写入到csv文件中
html —> 用于存储爬取下来的网页文件
stealth.min.js —> 读取和注入JavaScript,用于防检测
来看代码
ECommerceJobScraper.py
from selenium import webdriver
from selenium.webdriver import ChromeOptions
from selenium.webdriver.chrome.service import Service
from time import sleep
import random
from selenium.webdriver.common.by import By
# 主要函数,用于抓取和处理页面数据
def main():
for p in range(10): # 遍历10个页面
p += 1 # 页码从1开始
print(f'爬取第{p}页') # 打印当前页码
sleep(5 * random.random()) # 随机延迟,模拟人类行为
# 滚动页面以加载所有内容
for i in range(140):
sleep(random.random() / 5) # 短暂延迟
driver.execute_script('window.scrollBy(0,50)') # 向下滚动页面
res = driver.page_source # 获取页面源代码
# 将页面源代码保存到本地文件
open(f'html/{p}.html', 'w', encoding='utf-8').write(res)
# 如果不是最后一页,转到下一页
if p != 10:
driver.find_element(By.ID, 'jump_page').clear() # 清除页码输入框
driver.find_element(By.ID, 'jump_page').send_keys(p + 1) # 输入新的页码
sleep(random.random()) # 随机延迟
# 点击跳转按钮
button2 = driver.find_element(By.CLASS_NAME, 'jumpPage')
driver.execute_script("arguments[0].click();", button2)
# 脚本入口
if __name__ == '__main__':
# 设置和初始化WebDriver
service = Service('D:\\pythonProject1\\chromedriver.exe')
options = ChromeOptions()
options.add_experimental_option('excludeSwitches', ['enable-automation'])
driver = webdriver.Chrome(service=service, options=options)
# 读取和注入JavaScript,用于防检测
js = open('stealth.min.js', encoding='utf-8').read()
driver.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {'source': js})
# 访问目标网站
driver.get('https://we.51job.com/pc/search?keyword=&searchType=2&sortType=0&metro=')
sleep(5) # 等待页面加载
# 输入搜索关键词并点击搜索
input = driver.find_element(By.ID, 'keywordInput')
input.send_keys('电商') # 输入“电商”
button1 = driver.find_element(By.ID, 'search_btn')
driver.execute_script("arguments[0].click();", button1)
sleep(5) # 等待搜索结果加载
main() # 调用主函数开始抓取
driver.quit() # 关闭浏览器
JobInfoExtractor.py
from lxml import etree
import pandas as pd
import html
import json
# 假设有 N 个 HTML 文件需要遍历
number_of_files = 10 # 根据实际文件数量修改
# 用于存储所有职位信息的列表
jobs_data = []
# 循环处理每个 HTML 文件
for i in range(1, number_of_files + 1):
file_name = f'html/{i}.html' # 文件名格式为 1.html, 2.html, ...
# 读取 HTML 文件
with open(file_name, 'r', encoding='utf-8') as file:
html_content = file.read()
# 解析 HTML 内容
tree = etree.HTML(html_content)
# 提取所有 class 为 'joblist' 的 div 元素中的每个 div 子元素
joblist_divs = tree.xpath("//div[@class='joblist']/div")
sensorsdata_str = tree.xpath("//div[@sensorsname='JobShortExposure']/@sensorsdata")[0]
# 遍历提取的元素
for div in joblist_divs:
# 提取各种信息,根据实际 HTML 结构调整 XPath
sensorsdata = json.loads(sensorsdata_str)
job_title = div.xpath(".//span[@class='jname text-cut']/text()")
company_name = div.xpath(".//a[@class='cname text-cut']/text()")
salary = div.xpath(".//span[@class='sal shrink-0']/text()")
location = tree.xpath("//div[@class='shrink-0']/text()")
job_degree = sensorsdata.get('jobDegree', '')
# 处理可能的空列表
job_title = job_title[0] if job_title else ''
company_name = company_name[0] if company_name else ''
salary = salary[0] if salary else ''
location = location[0] if location else ''
# 将提取的数据添加到列表中
jobs_data.append([job_title, company_name, salary, location, job_degree])
# 创建 DataFrame
df = pd.DataFrame(jobs_data, columns=['职位名称', '公司名称', '薪资', '工作地点', '学历'])
# 保存 DataFrame 到 CSV 文件
df.to_csv('job_data.csv', index=False, encoding='utf-8')
# 文件写入完成
print('数据已保存到 job_data.csv')
stealth.min.js
// stealth.min.js 示例
(() => {
// 伪装 WebDriver 属性
Object.defineProperty(navigator, 'webdriver', {
get: () => false,
});
// 伪装插件数量和名称
Object.defineProperty(navigator, 'plugins', {
get: () => [1, 2, 3, 4, 5],
});
// 伪装语言设置为中文
Object.defineProperty(navigator, 'languages', {
get: () => ['zh-CN', 'zh'],
});
// 随机调整浏览器窗口大小
window.outerWidth = window.innerWidth;
window.outerHeight = window.innerHeight;
// 更多的伪装代码可以根据需要添加
})();
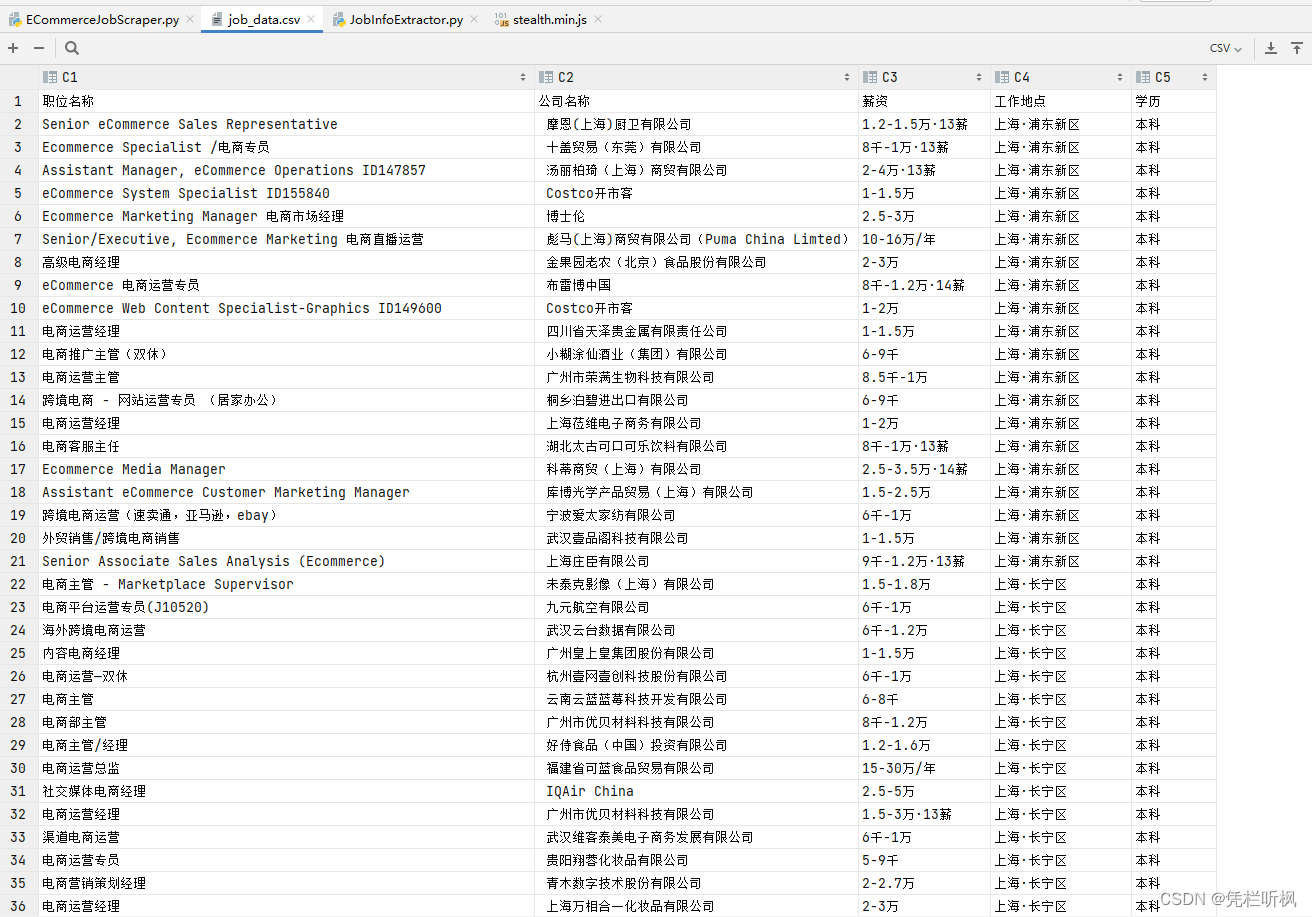
结果截图

















 7802
7802











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











