







本次写一写清华大佬Takashi Isobe的三个超分作品,大佬一年内,而且好像还是在华为实习期间连续中了三篇顶会,代码都开源在他自己的github中。
相关的论文可以查看地址
经典视频超分论文总结1
经典视频超分论文总结2
经典视频超分论文总结3
经典视频超分论文总结4
经典超分论文总结5
1、REVISITING TEMPORAL MODELING FOR VIDEO SUPER-RESOLUTION(RRN,BMCV2020)
本文其实很像上篇提到的FRVSR,也是采用RNN做超分,不同之处在于引入了残差结构
1.1 摘要
1)作者认为做超分因为loss不同,所以直接比结果是无效的。(这点确实,l2 loss会明显提高psnr计算结果,但是不一定比l1 loss视觉效果好)
2)作者对比了三种方法:2D CNN早期融合;3D CNN缓慢融合;RNN
3)作者提出了RRN,认为残差结构能稳定训练,并增强超分效果。
1.2 RRN
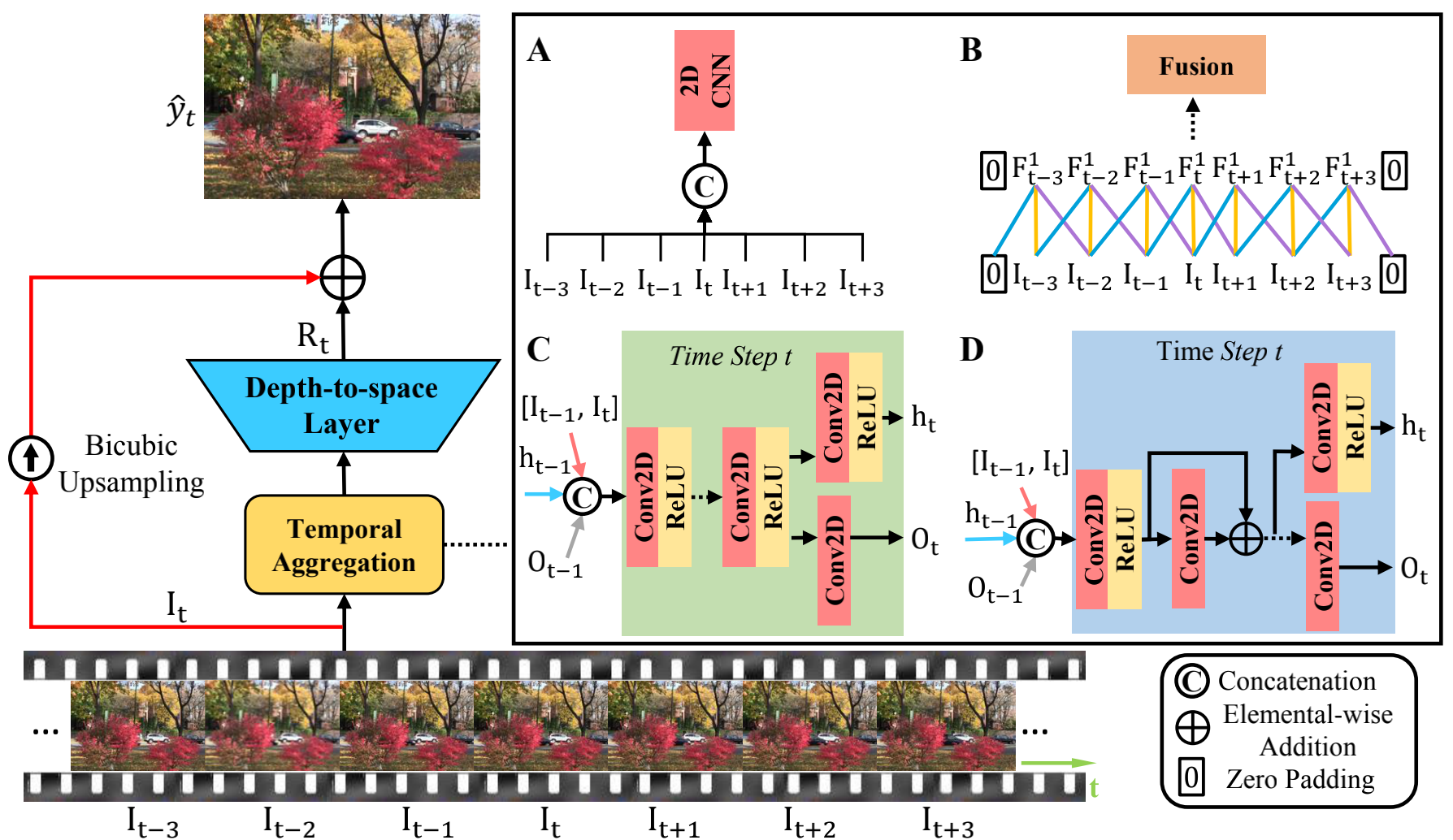
这个图相对来说很乱。但其实如果忽略作者对三种网络的对比,只讲RRN的话,只看左边整体结构和结构D就够了。
1.2.1 整体结构
整体结构如左边所示。输入连续帧,经过时序集成和D2S层后,学习到残差,然后将残差与中间帧双线性差值后的结果相加,得到最终输出。
1.2.2 时序集成
该部分就是作者对比的2D,3D,RNN的地方。但我们可以不用care,因为最终是引出RRN,也就是结构D的,所以只看D就好。
输入 : 在D中输入包含三部分,1)之前的输出
O
t
−
1
O_{t-1}
Ot−1; 2) 之前的隐藏层特征
H
t
−
1
H_{t-1}
Ht−1;3)两个相邻帧。
残差 :残差部分并非如D图所示只有一个卷积,而是两层卷积,代码实现的具体结构为
X
=
X
+
C
o
n
v
2
(
R
e
L
U
(
C
o
n
v
1
(
x
)
)
)
X = X + Conv2(ReLU(Conv1(x)))
X=X+Conv2(ReLU(Conv1(x)))
网络大小:网络大小由残差的数量决定,最大为10个res block。
1.2.3 输出
O
t
O_{t}
Ot 会经过 Depth2Space,也就是pixelShuffle后与上采的LR相加,然后得到输出。
同时
O
t
O_{t}
Ot 和
H
t
H_{t}
Ht会作为下一帧的输入。
2 Video Super-resolution with Temporal Group Attention(VSR_TGA,CVPR2020)
本文依旧是让网络学习残差,然后与上采样的原图相加,得到最后的输出。作者在代码实现中放飞自我,疯狂使用BN层。虽说代码很简单吧,但是其网络结构和代码的对应是一言难尽,基本看不懂代码的哪部分是网络的哪个部分。
2.1 摘要
最重要的一点在于,本文将距离参考帧相同时间距离的帧作为一组输入。比如1~7帧可分为三组[1,4,7],[2,4,6],[3,4,5]。作者认为这些组提供补充信息以恢复参考帧中缺失的细节,然后通过一个attention模块和一个deep intra-group fusion 模块进一步集成。此外,fast spatial alignment处理具有剧烈运动的视频。
2.2 网络结构
输入 : 作者在数据处理时,将数据提前处理为[B,C,T,H,W]格式,其中如果是连续7帧输入,那么处理后的T=9,帧数顺序为[1,4,7,3,4,5,2,4,6]。
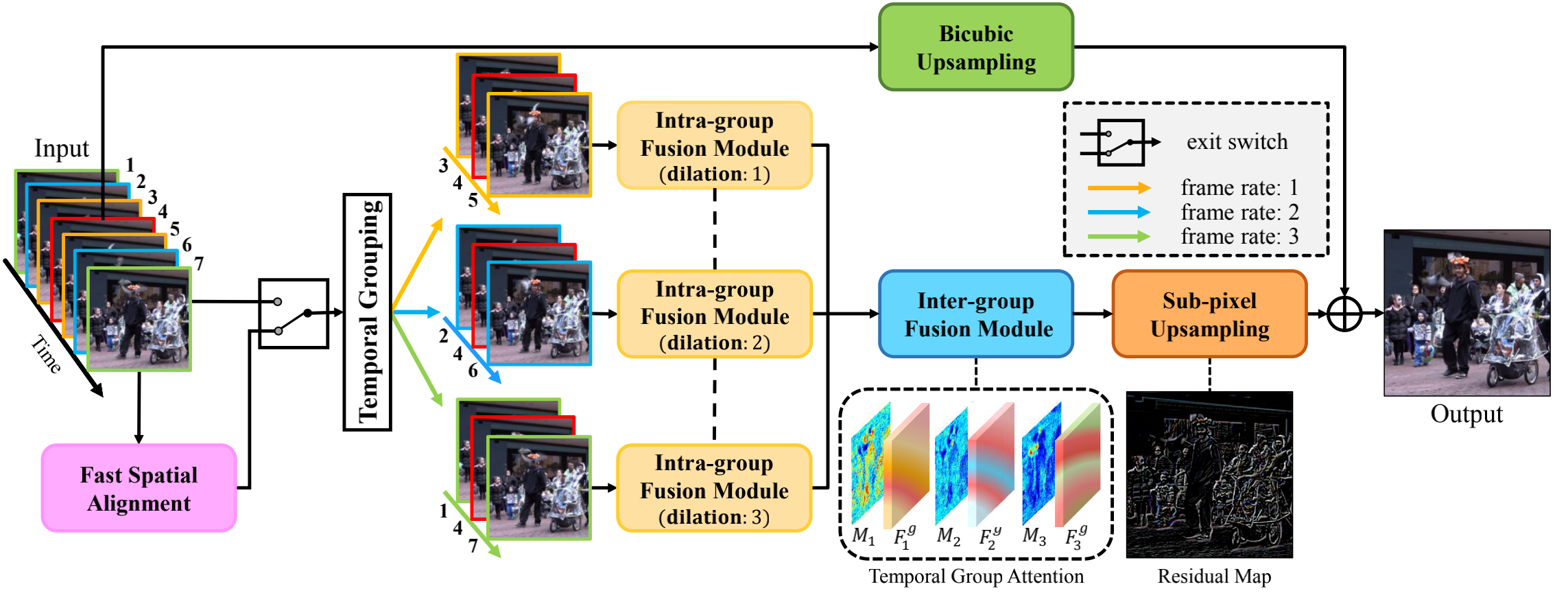
我本来想分析一下Fast Spatial Alignment,exit switch和Temporal Grouping。但是代码中直接没有该部分啊,上述处理后的图像直接丢进了Intra-group Fusion模块。此处求大佬赐教
2.2.1 Intra-group Fusion Module
此模块包含三部分组成
spatial features extractor:此部分包含3个ReLU(BN3d(Conv3d(x))),其中Conv3d的ks=(1,3,3),作者通过T通道设置为1融合不同空间的信息。
spatio-temporal feature fusion: 由一个3D卷积实现时空特征融合
self.conv3d_2_2 = nn.Conv3d(nf, nf, (3,3,3), stride=(3,1,1), padding=pad)
deeply integrate information within each group:
通过18个2D Dense Block组成。在代码中表示为self.head,4个self.middle 和一个self.last的前半部分组成。每个里面有3层2D Conv Block(bb一下,我其实不懂作者为啥不合到一起,明明结构一样)。2D Dense Block由
x
1
=
C
o
n
v
3
d
1
,
1
,
1
(
R
e
L
U
(
B
N
3
d
(
x
)
)
)
)
x1 = Conv3d_{1,1,1}(ReLU(BN3d(x))))
x1=Conv3d1,1,1(ReLU(BN3d(x))))
x
=
c
o
n
c
a
t
(
x
,
C
o
n
v
3
d
1
,
3
,
3
(
R
e
L
U
(
B
N
3
d
(
x
1
)
)
)
)
x = concat(x, Conv3d_{1,3,3}(ReLU(BN3d(x1))))
x=concat(x,Conv3d1,3,3(ReLU(BN3d(x1))))组成。
说明1: 我知道有人会问,为什么说的是2D Dense Block,但是用的是3D Conv。因为作者所有的2D Conv都是由3D Conv实现的,对T的卷积核设置为1
问题1: 作者说根据帧间距离不同设置了不同的空洞卷积率,这样可以有效融合不同时间步的信息,并相互补充。但是我并没有找到哪里设置了空洞卷积。步长也都是(1,1,1)啊?
2.2.2 Inter-group Fusion with Temporal Attention
Temporal Attention :先介绍该部分,因为网络先经过该部分,但是在论文中该部分的介绍在Inter-group Fusion之后。代码实现如下
x_att = x3[:,self.ng:self.ng+1,:,:,:] # x3是Intra-group的输出
x_att = F.softmax(x_att, dim=2)
对应图示如下
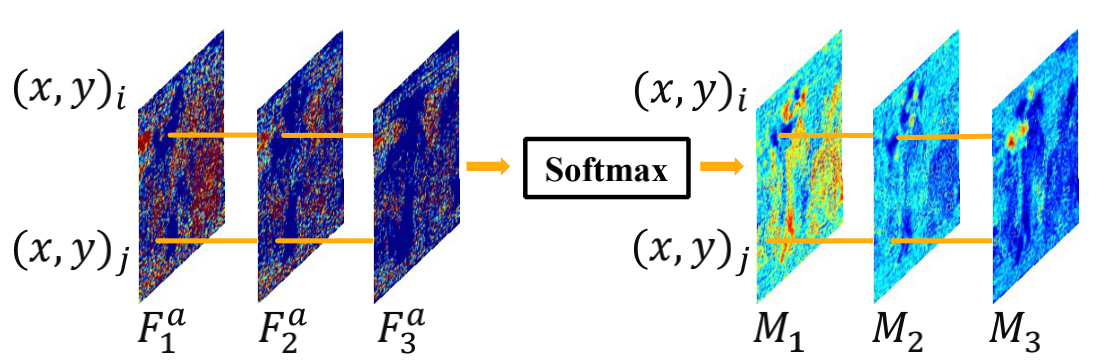
为什么图片由3个,但是代码只处理一个呢?因为T维对应的3组,所以代码处理C维就直接吧T维的3组同时处理了。
Inter-group Fusion
该部分又是卷卷卷,其中输入的部分代码实现如下
x_feat = x3[:,:self.ng,:,:,:]
x3 = torch.mul(x_att, x_feat)
x3 = torch.cat((x2,x3),1)
图片实现如下,图中的3D Dense Block和Intra基本一样,ks=(3,3,3),2D Dense Block同上。
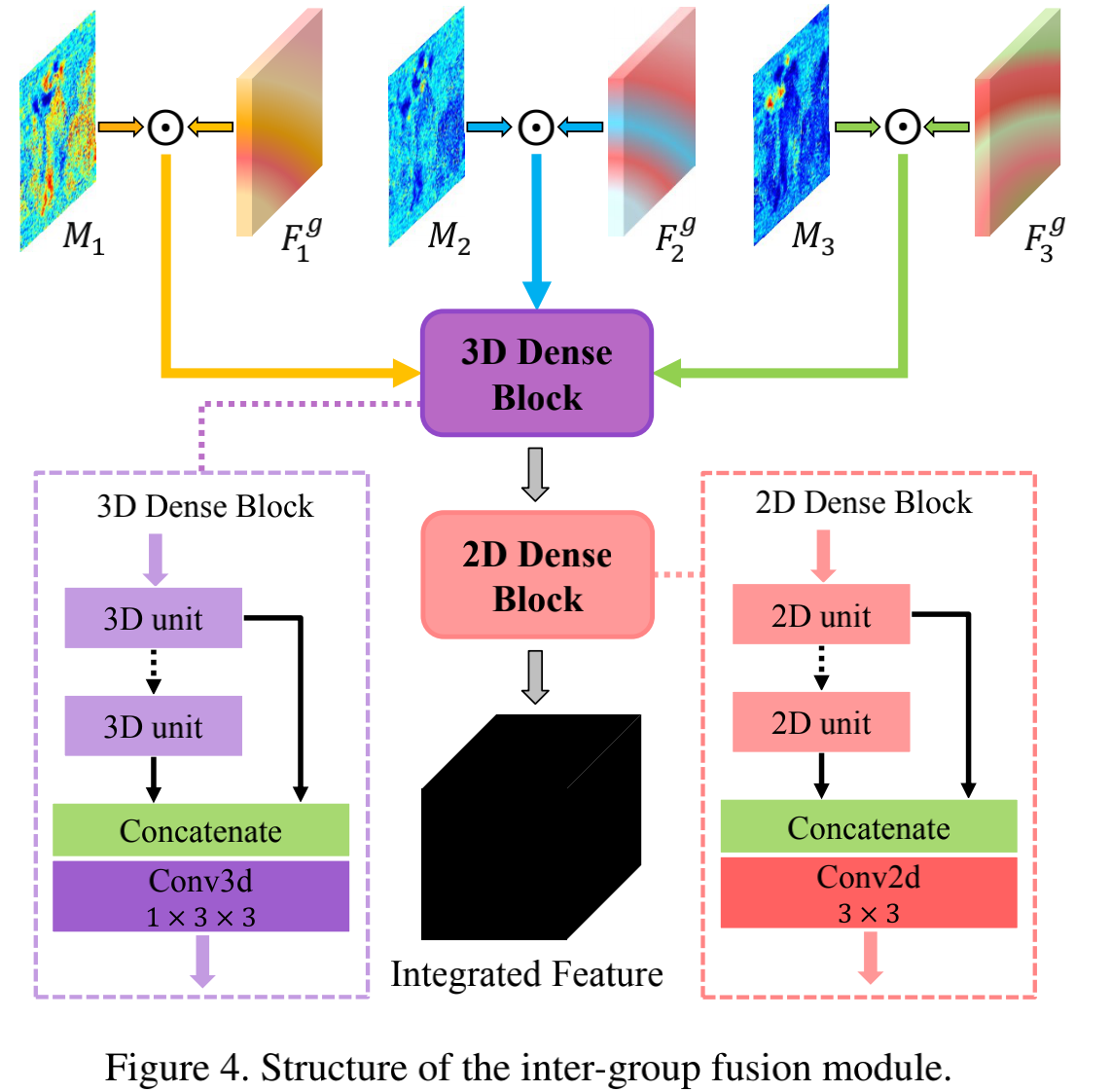
2.2.3输出
卷积后pixel Shuffle上采样,然后和双线性插值后的原图相加得到结果
2.3 Loss
L1 loss
ps:吐槽一波
最后再次说明一下问题。
1、代码中丢失的Fast Spatial Alignment,exit switch模块,我怀疑是exit switch直接选择了帧输入,所以这两部分在代码中就舍弃了。然后Temporal Grouping应该就是数据处理时候的把[1,2,3,4,5,6,7]变成[1,4,7,3,4,5,2,4,6]。
2、一直说的空洞卷积,我确实没找到在哪里。
3、论文最后提到的Fast Spatial Alignment,同1。
虽然我知道我和大佬之间有不可弥补的差距,但还是好想吐槽。这个代码看的我太难受了,本来论文很容易懂的,但是匹配代码搞了我一下午时间。累哭了==,求求点个赞吧
3 Video Super-Resolution with Recurrent Structure-Detail Network(RSDN,ECCV2020)
之前我们看的VSR文章基本都是输入图像,网络学习帧间残差(纹理部分),在输出前将残差与双线性插值后的LR图像(结构部分)相加得到最终结果。本文在输入阶段就把输入图像分为结构和纹理两部分,并送入循环网络。其中结构部分S通过双线性插值将采再上采获得,原图-S即可获得纹理D。
3.1 网络结构
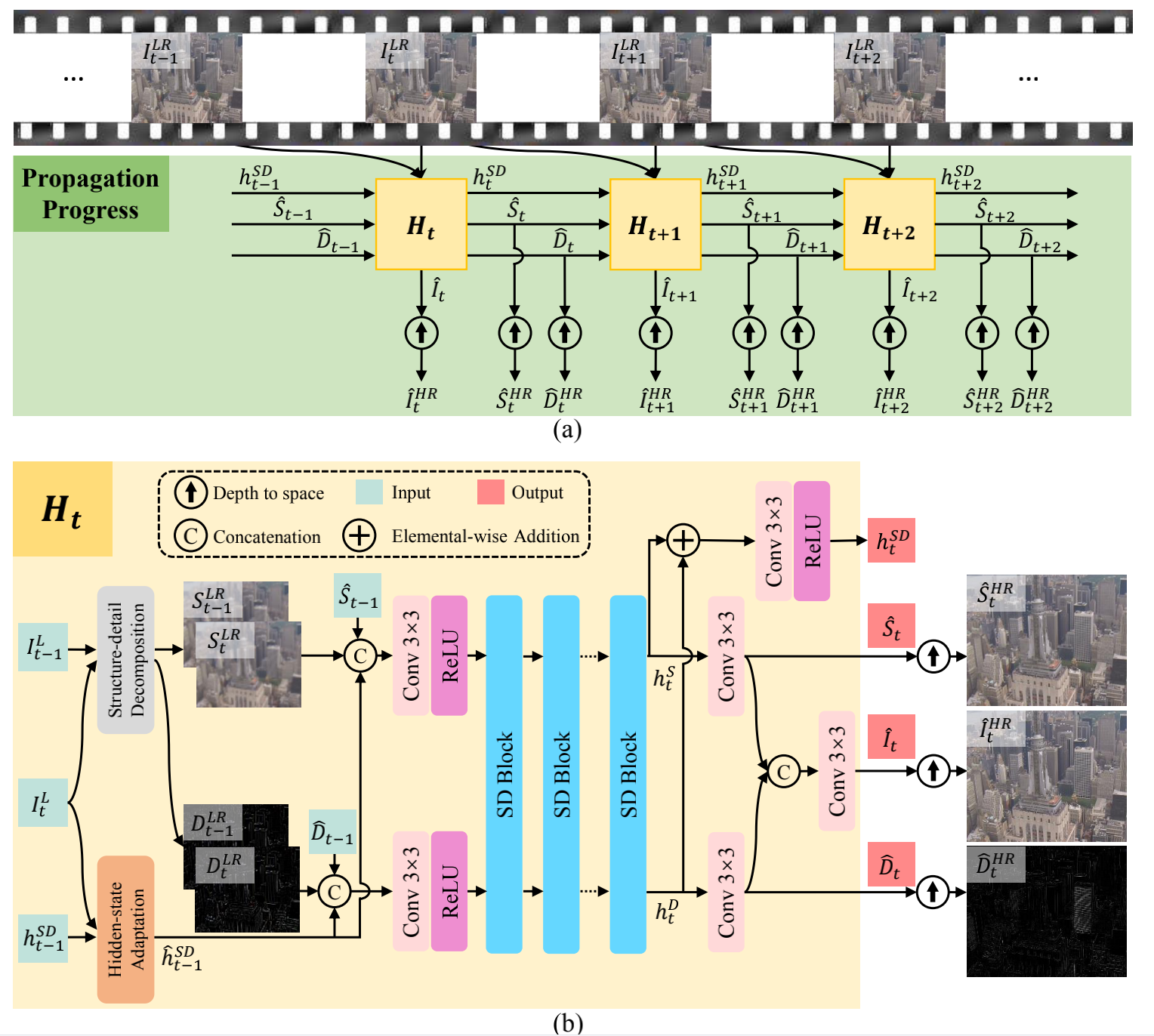
该部分看图应该就能看懂,主要是理解好输入输出模块。
I
t
−
1
L
I^{L}_{t-1}
It−1L : 输入的上一帧图像
I
t
L
I^{L}_{t}
ItL : 输入的当前帧图像
这两帧图像经过Structure-detail Decomposition(也就是双线性插值将采后再上采)得到各自的结构部分D和纹理部分S
h
t
−
1
S
D
h^{SD}_{t-1}
ht−1SD : 上一次循环获得的隐藏状态
S
^
t
−
1
\hat{S}_{t-1}
S^t−1 : 上一次循环获得的纹理部分
D
^
t
−
1
\hat{D}_{t-1}
D^t−1 : 上一次循环获得的结构部分
重点讲讲Hidden State Adaptation
作者认为隐藏层应该适应不同的当前帧不同的 appearance,因此提出HSA结构,融合隐藏层和图像。highlight隐藏层中和当前帧相似的部分,并抑制不同的部分。
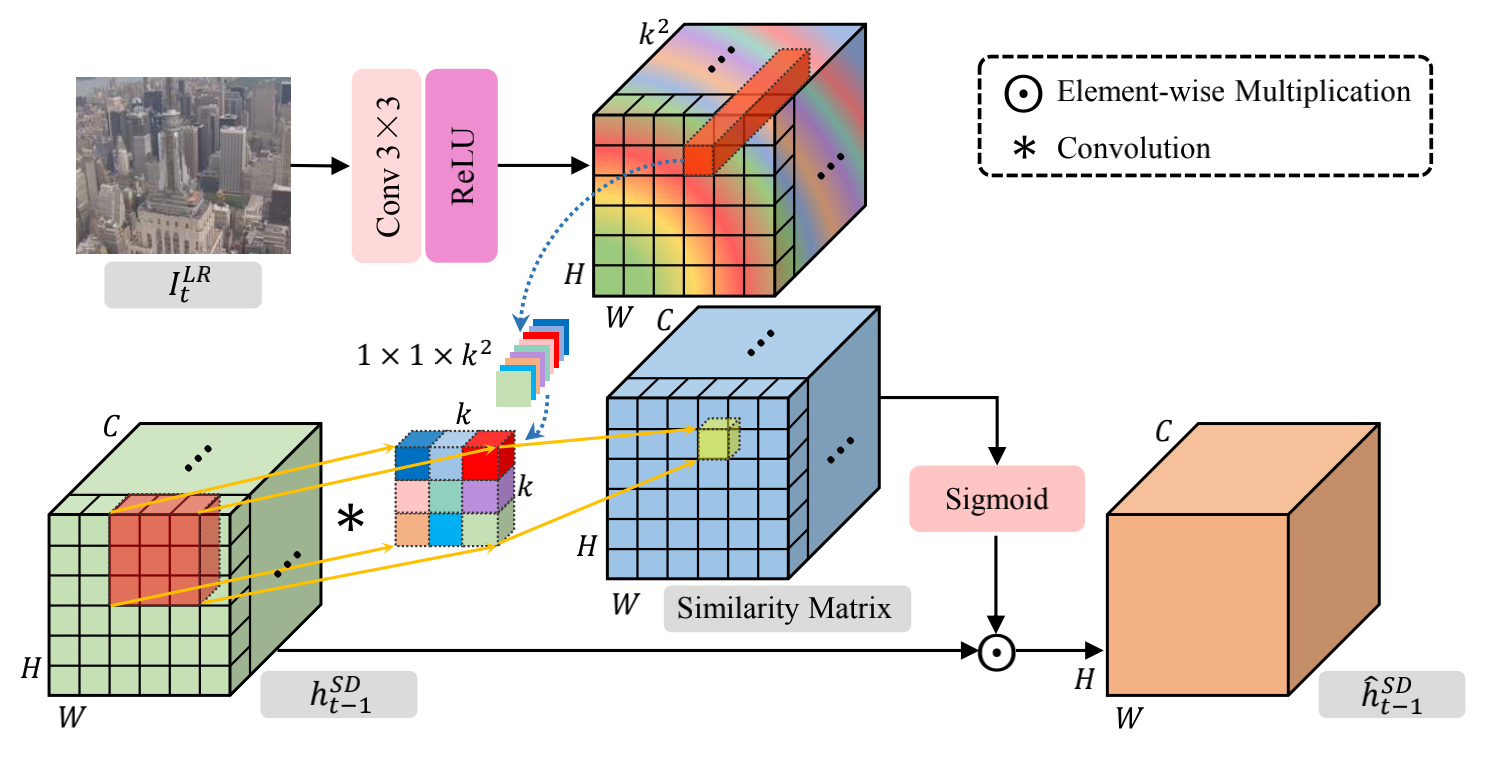
此处好像和代码也是不完全相同==贴一下源代码,相应对该部分的讲解直接写在注释里
class DynamicUpsamplingFilter_3C(nn.Module):
'''dynamic upsampling filter with 3 channels applying the same filters
filter_size: filter size of the generated filters, shape (C, kH, kW)'''
def __init__(self, filter_size=(1, 5, 5)): # 使用设置为(1,3,3)
super(DynamicUpsamplingFilter_3C, self).__init__()
nF = np.prod(filter_size)
expand_filter_np = np.reshape(np.eye(nF, nF),
(nF, filter_size[0], filter_size[1], filter_size[2])) # [9, 1, 3, 3]
expand_filter = torch.from_numpy(expand_filter_np).float()
self.expand_filter = expand_filter.repeat(128,1,1,1) #此部分制作卷积核 [128*9, 1, 3, 3]
def forward(self, x, filters):
'''
x: Hsd,即上图绿色的矩形 [B, 128, H, W], 128为设置的隐藏层通道数,由超参控制,用于总结前几帧的信息
filters: 上图中经过Conv,ReLU得到的彩色的卷积,[B, 3^2, H, W]
Return: filtered image, [B, 128, H, W]
'''
filters = filters.unsqueeze(dim=2) # [B, 9, 1, H, W]
B, nF, R, H, W = filters.size() # nF = 9 = 3^2
# using group convolution
input_expand = F.conv2d(x, self.expand_filter.type_as(x), padding=1,
groups=128) # 此处没懂,权重不该是filter吗? [B, 128*9, H, W]
input_expand = input_expand.view(B, 128, nF, H, W).permute(0, 3, 4, 1, 2) # [B, H, W, 128, 3^2]
filters = filters.permute(0, 3, 4, 1, 2) # [B, H, W, 3^2, 1]
out = torch.matmul(input_expand, filters) # [B, H, W, 128, 1]
return out.permute(0, 3, 4, 1, 2).squeeze(dim=2) # [B, 128, H, W]
此部分我觉得时copy的VSR-DUF的Dynamic Upsampling Filters。只是应用对象不同。
问题1:为啥按图来说Conv2d时候的权重该是filter,实现是self.expand_filter
问题2:好像并没有sigmoid操作啊
问题3:好像相乘的对象也不对
求大佬指教
3.2 Loss
对三个输出I,D,S分别计算 Charbonnier loss















 37
37











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









