







继续看论文,感觉头发都要掉完了,哭==
这次写paperWithCode上vid4榜首的两篇论文
相关的论文可以查看地址
经典视频超分论文总结1
经典视频超分论文总结2
经典视频超分论文总结3
经典视频超分论文总结4
经典超分论文总结5
10 Deep Video Super-Resolution Network Using Dynamic Upsampling Filters Without Explicit Motion Compensation(VSR-DUF, CVPR18)
震惊,18的论文能效果拍这么靠前。从题目就知道这篇文章的贡献是提出了一个动态上采filter,替代了其他论文中的MC。
10.1 网络结构
这部分不是重点,大概看图就能理解。其中Filter和Xt相乘的地方就是使用Dynamic Upsampling。然后与残差相加获得最终结果
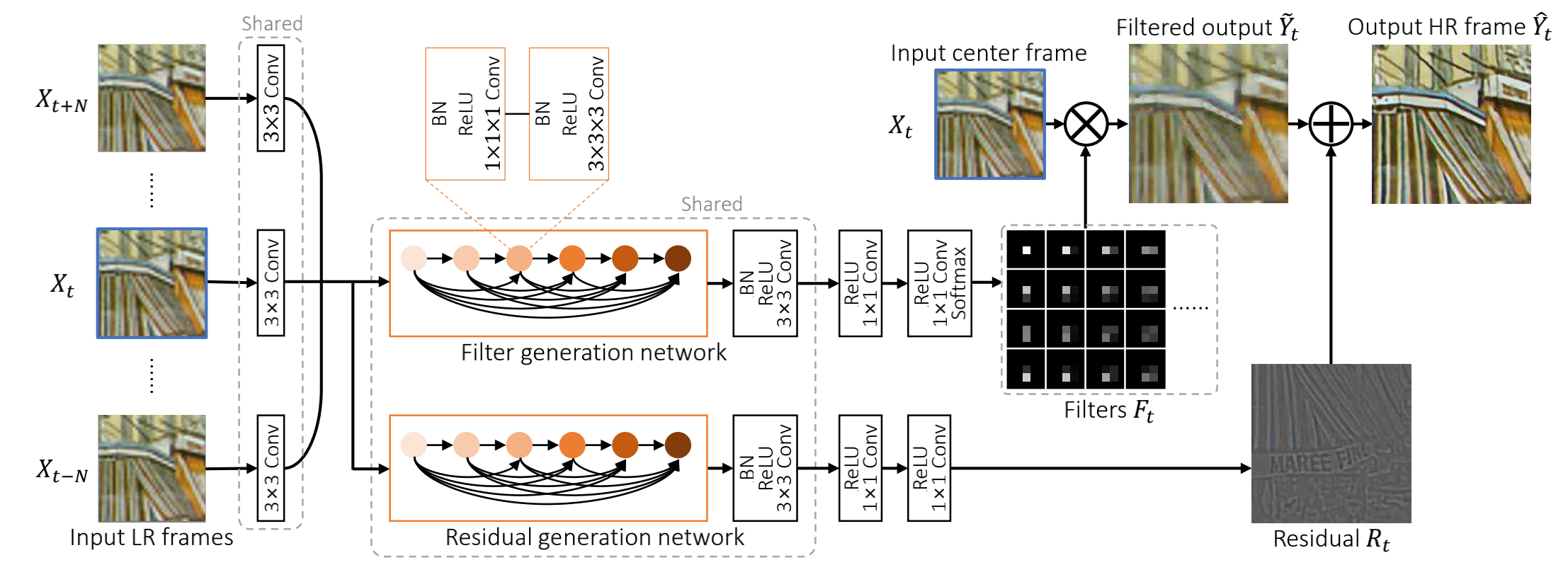
10.2 重点讲讲Dynamic Upsampling Filters
作者认为传统双线性或双三次插值的卷积核都是固定的,虽然计算快,但无法保持尖锐和纹理( sharp and textured)区域。该模块图示如下
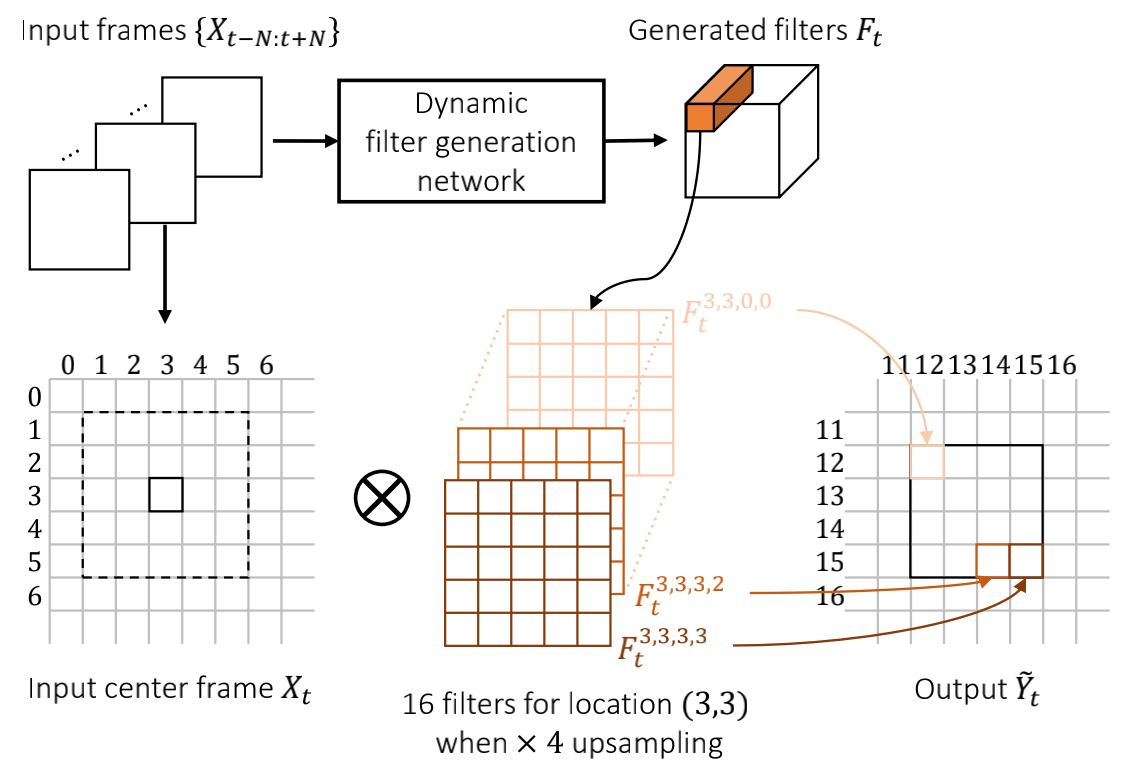
代码实现如下:
def DynFilter3D(x, F, filter_size):
'''
3D Dynamic filtering
input x: (b, t, h, w) # t=1 只取了中间帧
F: (b, h, w, tower_depth, output_depth)
filter_shape (ft, fh, fw) [1,5,5]
'''
# make tower
filter_localexpand_np = np.reshape(np.eye(np.prod(filter_size), np.prod(filter_size)), (filter_size[1], filter_size[2], filter_size[0], np.prod(filter_size)))
filter_localexpand = tf.Variable(filter_localexpand_np, trainable=False, dtype='float32',name='filter_localexpand') # [5,5,1,5*5]
x = tf.transpose(x, perm=[0,2,3,1]) # [b,h,w,T=1]
x_localexpand = tf.nn.conv2d(x, filter_localexpand, [1,1,1,1], 'SAME') # b, h, w, 1*5*5
x_localexpand = tf.expand_dims(x_localexpand, axis=3) # b, h, w, 1, 1*5*5
x = tf.matmul(x_localexpand, F) # b, h, w, 1, R*R
x = tf.squeeze(x, axis=3) # b, h, w, R*R
return x
看到这个代码我都震惊了,和上一篇RSDN中的Hidden State Adaptation不说相似吧,最起码也可以说是一模一样。但那篇是20年的
说明1: 图中的Dynamic Filters Generation network就是F的生成部分。
说明2:输入x之所以没有通道维C,是因为作者逐通道计算,然后再组合。
说明3:filter_localexpand 是用于拓展x的通道数,将x像素纵向分配到不同的通道。
说明4:输出的x需要在经过Depth2Space才能得到图示的output Y
10.3 损失函数
Huber loss
11 iSeeBetter: Spatio-temporal video super-resolution using recurrent generative back-projection networks(CVM2020)
传统CNN终究具有一定的局限性,无法恢复丢失的细节信息,终究还是的靠GAN来想象出来。该网络很简单,生成器直接使用RBPN,鉴别器采用SRGAN的(小声bb:某乎的标题党“即插即用,涨点神器”,还让我恍惚间以为提了什么block或者attention 呢)
代码链接
11.1 RBPN
这不再写了,详见我之前的博客 不过正好论文有图,补充一下SISR和MISR的可视化结构

SISR,采用的DBPN的结构,将采使用8*8卷积核,步长=4,pad=2

resnet结构用于构成MISR,但好像不是图中所示的3个tiles,代码实现如下
modules_body1 = [ResnetBlock(base_filter, kernel_size=3, stride=1, padding=1, bias=True, activation='prelu', norm=None) \
for _ in range(n_resblock)]
modules_body1.append(DeconvBlock(base_filter, feat, kernel, stride, padding, activation='prelu', norm=None))
self.res_feat1 = nn.Sequential(*modules_body1)
11.2 判别器

11.3 Loss
MSE Loss:(SR, HR)
Perceptual loss: 将估计的SR图和GT分别输入VGG19获得的feature map
Adversarial loss :判别器的输出取-log
Total-Variation loss(TV loss):用于描述生成的SR图像中每个像素和它垂直上方、水平左侧相邻像素间的差值。用于平滑图像,去燥。但会丢失图像中边缘的尖锐信息。

代码实现如下:
class TVLoss(nn.Module):
def __init__(self, tv_loss_weight=1):
super(TVLoss, self).__init__()
self.tv_loss_weight = tv_loss_weight
def forward(self, x):
batch_size = x.size()[0]
h_x = x.size()[2]
w_x = x.size()[3]
count_h = self.tensor_size(x[:, :, 1:, :])
count_w = self.tensor_size(x[:, :, :, 1:])
h_tv = torch.pow((x[:, :, 1:, :] - x[:, :, :h_x - 1, :]), 2).sum()
w_tv = torch.pow((x[:, :, :, 1:] - x[:, :, :, :w_x - 1]), 2).sum()
return self.tv_loss_weight * 2 * (h_tv / count_h + w_tv / count_w) / batch_size















 1631
1631











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









