







今天再介绍一位港中文的大佬xintao wang 大佬目前已经有3435 google citations了。大佬的论文都开源在自己的github上。
相关的论文可以查看地址
经典视频超分论文总结1
经典视频超分论文总结2
经典视频超分论文总结3
经典视频超分论文总结4
经典超分论文总结5
先讲几篇他早期的超分论文,包括两篇VSR和一篇SISR,
1、ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks(ECCV2018 workshop)
SISR,google cite达到了令人窒息的1425!
1.1 摘要
话说当年有个工作叫SRGAN,开创了GAN用于超分的先河,作者琢磨琢磨想:SRGAN可太强了,会生成真实的纹理。但是啊,它虽然会产生幻想的(hallucinated)细节,但也伴随着生成了令人不开心的伪影。不如我们对他的三个主要部分(网络结构,对抗损失,感知损失)强化一下吧。然后就顺手提出了ESRGAN。并顺手拿到了PIRM2018-SR的第一名,顺便发个论文就有了1425个cite!
1.2 网络结构
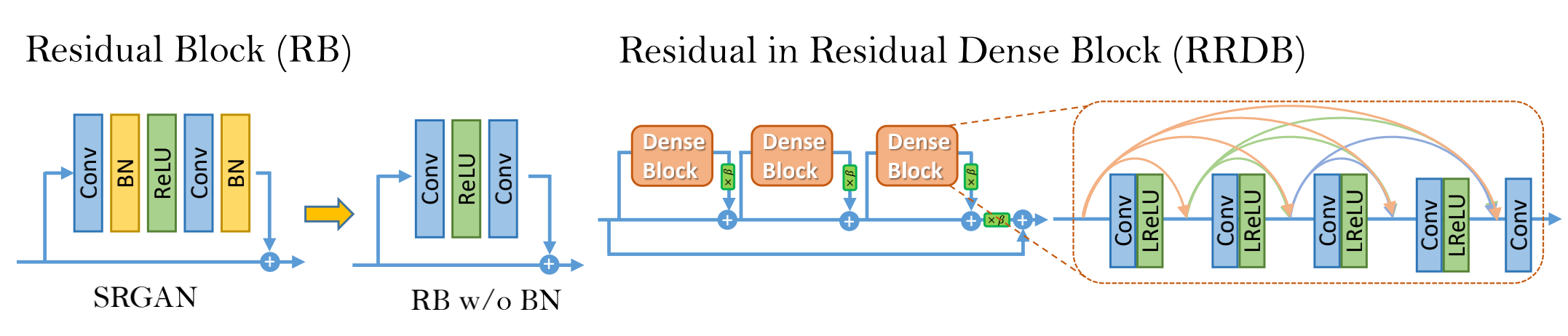
作者在SRGAN的基础上做了两点改进。
1)移除所有的BN层。因为作者认为在基于PSNR的任务中,比如SR,deblurring。移除BN层会提升效果,并且避免复杂的计算。当训练和测试数据统计特征不同时,BN层会引入伪影,并且限制了生成能力。作者实证(empirically)发现BN在网络deeper和训练GAN时更容易引入伪影。
2)使用RRDB代替SRGAN中的RB,结构图如下。需要说明的是图中的
∗
b
e
t
a
*beta
∗beta 是对残差缩放,用于对所有参数乘[0,1]间的常量,而非尺寸的扩大和减小,这样可以稳定训练。同时作者使用的小的初始化,这样残差更容易训练。
1.3 相对鉴别器 Relativistic Discriminator
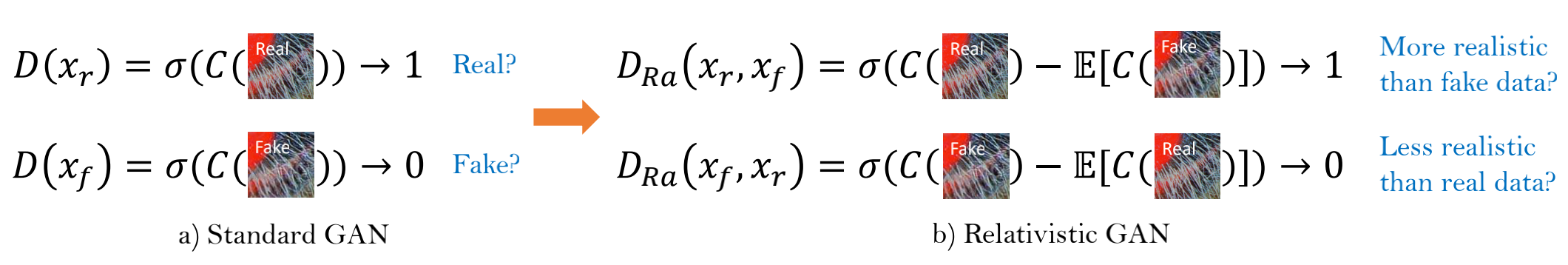
标准GAN是输入真实图像和生成的图像判别。本文参考Relativistic GAN,判断真实图像比假图像更真实的概率。其中E表示mini batch中所有fake image的平均。得到输出结果后,判别loss和生成loss分别表示为:

1.4 感知损失 perceptual Loss
这个蛮常见的,用不同输入经过VGG19的特征计算loss,与之前采用激活后特征相比,本文采用激活钱特征,有两个好处。
1)激活后的特征一般是比较稀疏的,比如VGG19-54层在输入猩猩时只有11.17%的激活。
2)激活后的特征会导致重建后的亮度不连续。
1.5 网络插值
神奇的一个操作。首先我们先基于PSNR获得一个生成网络 G P S N R G_{PSNR} GPSNR, 然后通过fine-tuning获得一个基于GAN的网络 G G A N G_{GAN} GGAN,然后将这两个网络的参数甲醛就得到了一个插值的网络 G I N T E R P G_{INTERP} GINTERP!参数插值表示为:
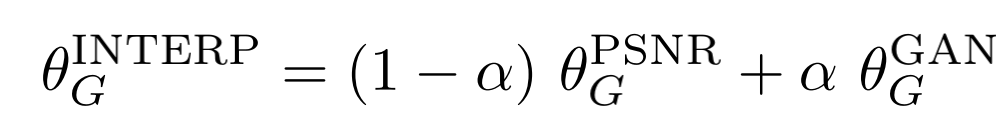
其中alpha在[0, 1]间。这种模型有两个优点。1)可以在任何alpha情况下产生有意义的结果,同时不引入伪影。2)平衡感知质量和保真度
2 EDVR: Video Restoration with Enhanced Deformable Convolutional Networks(CVPR19 workshop)
VSR领域里还是蛮知名的方法,NTIRE19时的冠军算法,本文google cite也达到了300多。
2.1 摘要
从标题可以看出来,文章最重要的是提出了Enhanced Deformable Convolutional。在NTIRE19比赛中使用了REDS数据集,带来了两个显著的问题:1)怎么在给定的剧烈运动(large motions)情况下对齐多帧图像。2)怎么融合具有不同运动和模糊的不同帧。
作者据此提出了强化反卷积(Enhanced Deformable Convolutional)。
在解决第一个问题时,作者采用金字塔(Pyramid),级联( Cascading)和可变形的(Deformable)对齐,模块,其中帧对齐是在特征层面使用可变形卷机按照从粗到细(coarse-to-fine)的方式实现的。在解决第二个问题时,提出了时空注意力(Temporal and Spatial Attention ,TSA)融合模块。用于强调重要特征。
2.2 网络结构
本文的整体结构如下:
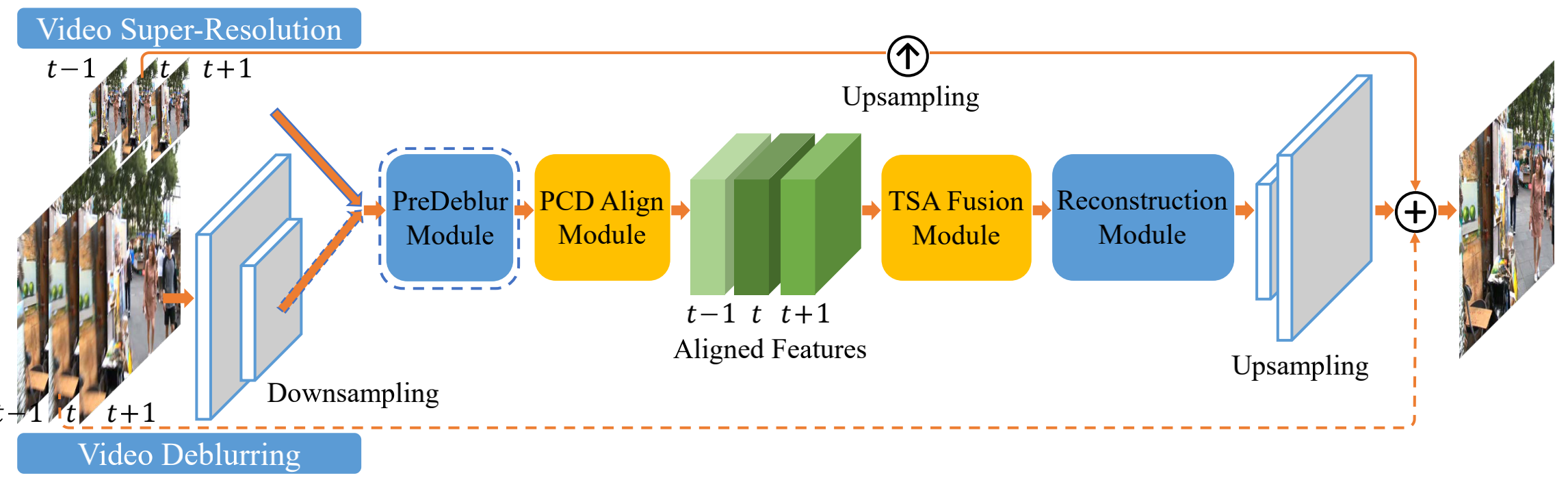
VSR可直接输入网络,其他任务比如deblurring先经过步长=2的卷积降采后输入到网络中。接下来将逐模块介绍。
2.2.1 PreDeblur Module
这个模块在论文中没有介绍 ,但是看BasicSR代码可以看出来。就是一个降采样两次的3层Unet,通过步长=2的卷积降采,然后lReLU激活。上采样使用双线性插值。
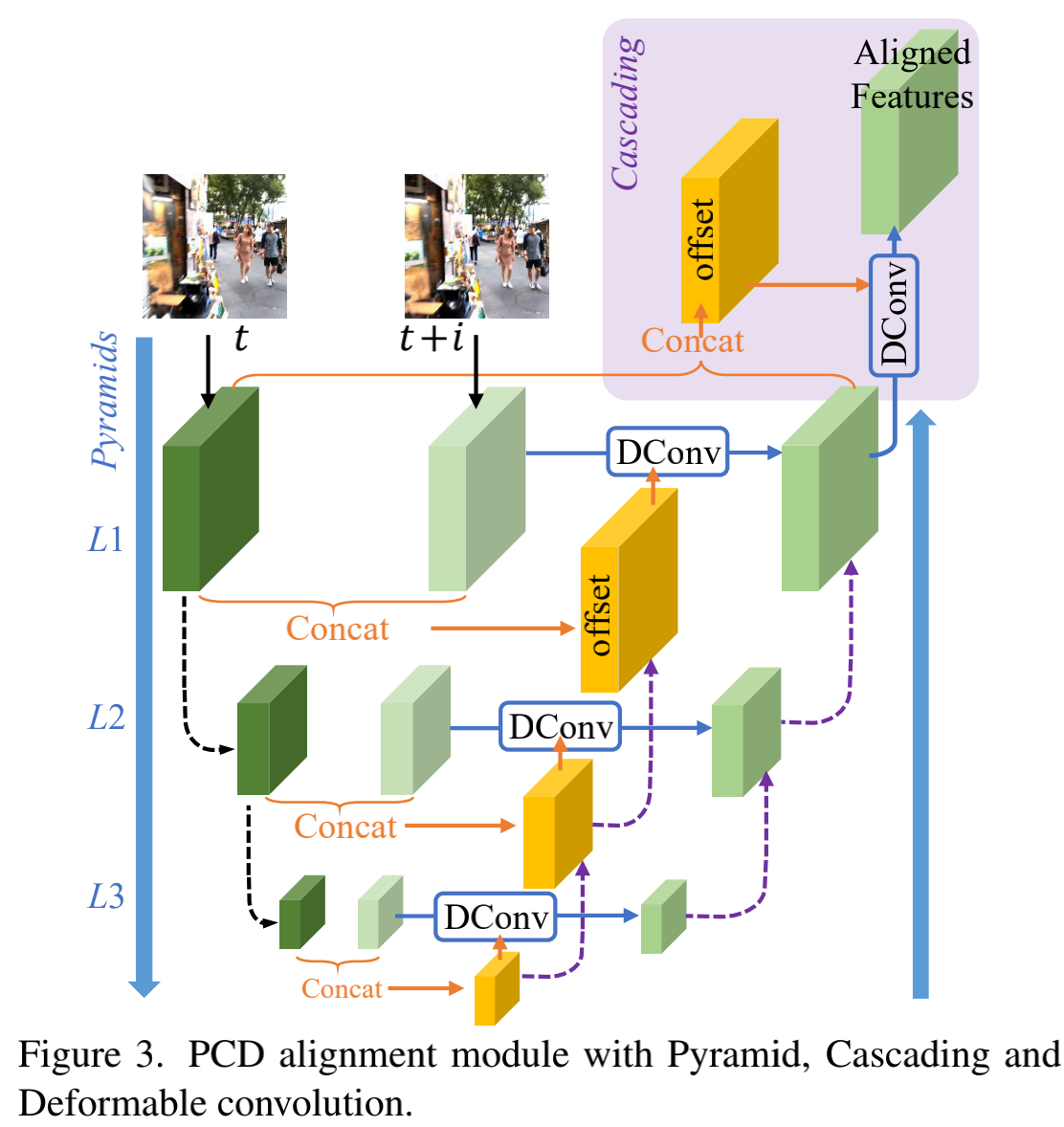
2.2.2 PCD Align Module
论文中几个公式在讲反卷积感觉可以不用care,还是直接看图吧,一目了然。黑色虚线是通过步长为2的卷积将采。金字塔是说将采了三次,DConv就是反卷积了。这个级联(cascading)我看代码难道是offset经过两次卷积的意思?然后将经过两次lre lu(Conv(offset))的结果和浅绿色的反卷积得到的特征concat后送入DConv,得到对齐特征。
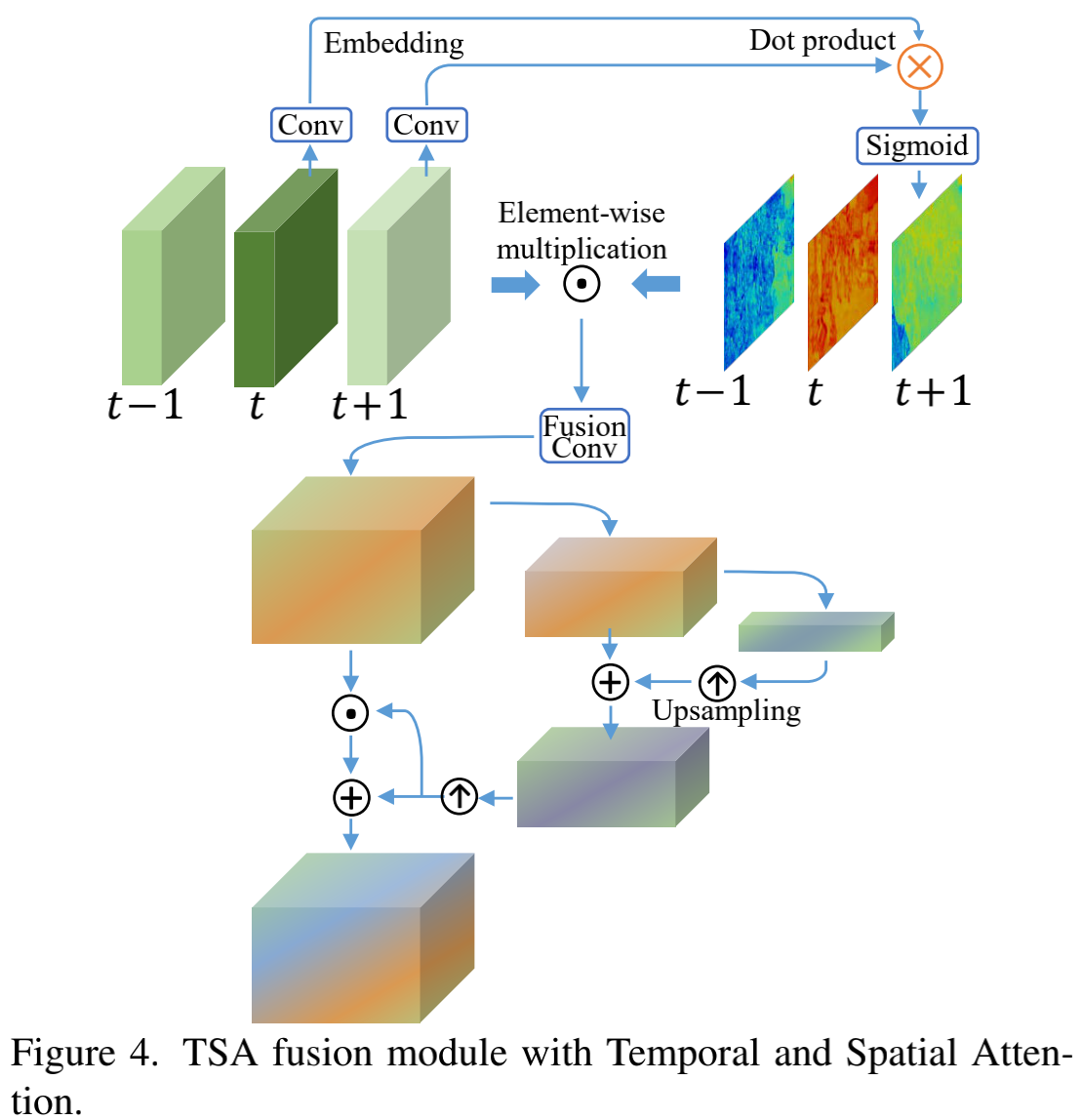
2.2.3 Fusion with Temporal and Spatial Attention
此模块认为帧间时序相关性和帧间空间相关性在融合时至关重要。因此模块核心在于在嵌入空间(embedding)计算帧间相似性h,然后给相似的更多Attention。相似性距离h可以表示为:
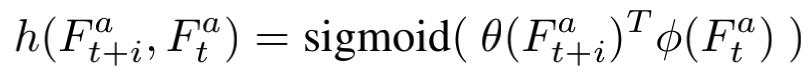
计算方法为对 Conv(中间帧) ,然后对相邻帧逐帧送入Conv,与中间帧卷积后得到的特征相乘,再计算sigmoid得到相似性h。
后面部分类似Unet不再细讲。
2.3 级联
作者还有个凡尔赛的地方。他说本来一个EDVR网络就已经能够拿第一了,但是咱把两个EDVR级联起来会效果更好。直觉上,可以大大减轻后面网络对齐和融合的压力。级联时候接一个浅一点的EDVR网络,用于refine第一阶段的输出帧。 这样好处有两点:
1)有效移除运动模糊,提升SR质量。
2)减轻输出帧间的不一致。
3 BasicVSR: The Search for Essential Components in Video Super-Resolution and Beyond(CVPR2021)
从题目看作者在研究VSR中至关重要的组件,并基于此提出了一个框架,安装时候需要编译DConv,有困难的话可以参考我的博客。
3.1 摘要
说作者通过考虑SVR的四个重要部分传播,对齐,集成,上采(Propagation, Alignment, Aggregation, and Upsampling.),以最小的重新设计,复用现有的组件,进化出了一个厉害的框架BasicSR,然后速度和效果都达到最好。同时由在此基础上加强提出了 信息重装和耦合传输(information refill mechanism and coupled propagation scheme),究极进化成了IconVSR框架。
3.2 BasicVSR
propagation和对齐会导致效果的大的摆动(seing),因此实验建议采用双向传播,并用光流法估计相邻帧间的相关性,通过这些简单的修改,可以提升0.61dB的PSNR,速度提升24倍。
3.2.1 Propagation
说天下传播有三种,局部的(Local),单向的(Unidirectional)和双向的(Bidirectional)。
Local:这局部的就是每次输入连续的几帧,然后划窗向后。这种信息只限于局部的,效果不好。这个作者做了实验,当分割的组K越大,Local越小,也就是划窗内帧数越少,这样效果越差。
Unidirectional :信息从第一帧传输到最后一帧,这就导致开始信息少,后面信息包含前面所有,所以前面帧的结果就是次优的。这个作者也做了实验,越靠后的帧计算的PSNR越高。
Bidirectional:所以咱用双向的啊。你看作者这贴心的设计,还把反向得到的
h
b
i
h^{i}_{b}
hbi送到正向作为输入,这样多方便信息融合。
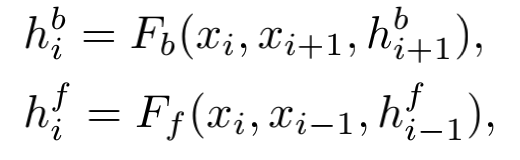
3.2.2 Alignment
话说这天下对齐也有三种。不对齐(without),图像对齐(Image),特征对齐(Feature)
without:不对齐一般是使用rnn网络的操作,会导致性能略差。作者将BasicSR的对齐删掉,PSNR降低了1.19dB。
Image :图像对齐,如早期的光流+warp。但不精准的光流会引入图像模糊和不真实(blurriness and incorrectness)
Feature :所以对特征采用光流法,然后将对齐的特征输入到多个残差网络中加强。
3.2.3 Aggregation and Upsampling
基本成分。
3.3 IconVSR
只整合别人的怎么能满足呢?作者又提了点自己的小新idea,Information-refill mechanism and coupled propagation,让BasicSR究极进化到IconVSR。这两个模块图如下:
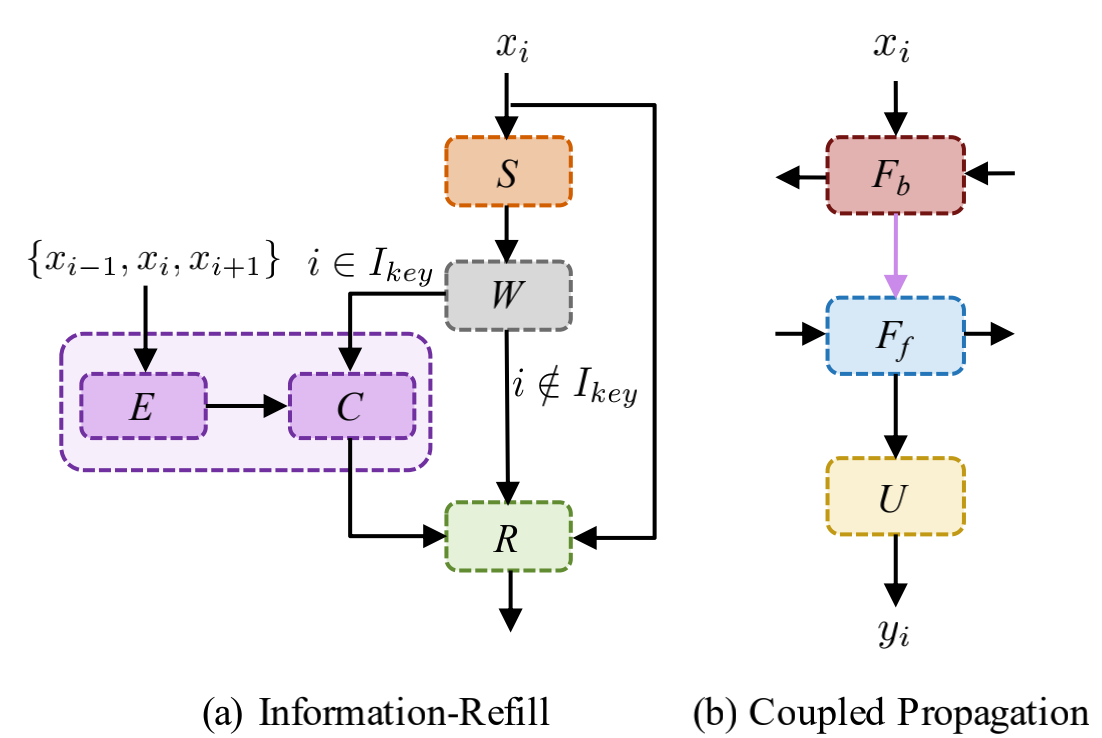
3.3.1 Information-refill
作者认为闭塞区域和图像边界的不准确的对齐会导致错误累计,尤其是当我们采用了长时间传播(longterm propagation)。为了缓解这种问题提出该结构,该结构利用附加模块从稀疏选定的帧中提取特征,然后将其插入到主网络用于特征细化。公式表示为
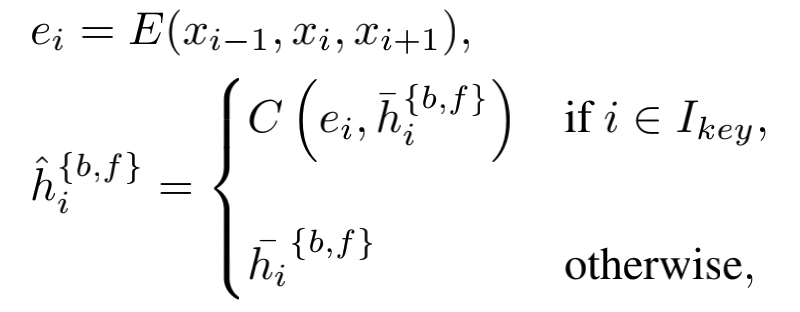
其中 I k e y I_{key} Ikey表示选定的关键帧,E为特征提取,C为卷积。可以看出当当前帧为关键帧时,送入Information-refill,这样计算负担小。最后输入到残差网络中。
3.3.2 coupled propagation
这个简单,看见那个粉色尖头没?就是说反向传播的特征作为前向传播的输入的一部分。
说点其他的
1)先说点搞笑的
作者写BasicVSR这篇论文在开始就在怼其他的VSR设计的什么玩意,也太复杂(highly complex)了吧!比如那个EDVR,一大堆对齐,一大堆Attention。(小声bb:emmmm话说这不是你自己的论文吗?咱引用自己还能骂着引用的😂😂😂)
2)有点难受的是
BasicVSR后面更新了BasicVSR++,并获得的NTIRE2021的冠军,再往后的NTIRE2022 SR就是各种拼数据集,拼模型大小,拼集成了,好多直接把BasicVSR++作为自己模型的一个Block,然后各种堆叠。啊这,网络设计的美感呢?
周末啦886!
大佬到了腾讯后更是杀疯了,之前在港中文中的两篇worshop被引爆炸,现在要中就中正刊。本文介绍最新的GFPGAN和Real-ESRGAN,都是SISR和盲超分。
4、GFPGAN:Towards Real-World Blind Face Restoration with Generative Facial Prior (CVPR 2021)
本篇论文专著于人脸的超分,效果我愿称之为最强。话不多说,先上张对比看看

4.1 摘要
盲超分通常需要脸部先验(脸部几何先验或参考先验)来保证真实性和可信的细节。但是非常低质的输入不能提供精准的几何先验,HQ的参考先验又缺失,那还怎么真实应用呢?所以GFPGAN利用之前训练的FaceGAN的丰富且不同的先验用来盲Face SR。GFP通过空间特征转换层合并到Face重建过程,这保证了真实性与保真性的平衡。
4.2 方法
本文方法相对于之前的一些连连看复杂的多,我尽量能讲详细点。

上图就是整个网络的整体架构。首先整体把握一下,来,咱先只看蓝色和绿色框所代表的生成器部分。首先生成器包含降质移除模块(Degradation Removal)和预训练的Face GAN(Pretrained GAN)。他们通过一个隐藏编码映射(latent code mapping)和几个通道分离空间特征转换层(Channel-Split Spatial Feature Transform,(CS-SFT))连接。
降质移除模块就是一个Unet,作者将Unet最深层的特征作为隐藏特征(latent feature,表示为
F
l
a
t
e
n
t
F_{latent}
Flatent);然后将反卷积过程中不同尺寸的特征称之为多分辨率空间特征( multi-resolution spatial features, 表示为
F
s
p
a
t
i
a
l
F_{spatial}
Fspatial)。
预训练Face GAN此时采用StyleGAN2。 F l a t e n t F_{latent} Flatent首先经过一个MLP映射为隐藏编码(latent codes)W,然后再把W送入StyleGAN2,得到 F G A N F_{GAN} FGAN。 F G A N F_{GAN} FGAN和¥F_{spatial}$输入到图中浅黄色框表示的CS-SFT中。最后生成结果。
4.2.1 降质移除模块
该模块设计用来移除复杂将质(如模糊,噪声,JPEG压缩等),并提取两种“clean”特征 F l a t e n t F_{latent} Flatent和 F s p a t i a l F_{spatial} Fspatial。之所以用Unet是因为:1)Unet可以增加感受野2)可以生成多种分辨率。并且作者训练的早期阶段,在decoder时候将每个尺度的特征都用来生成结果,并与GT图像计算L1 loss。
4.2.2 生成脸部先验和隐藏层编码映射 (Generative Facial Prior and Latent Code Mapping)
话说一般超分是把隐藏编码Z直接送到预训练的GAN中生成输出,但这需要时间迭代。因此本文用中间卷积特征 F G A N F_{GAN} FGAN,这样可以包含更多细节,通过输入特征进一步调制获得更好的保真度。公式简明表示如下
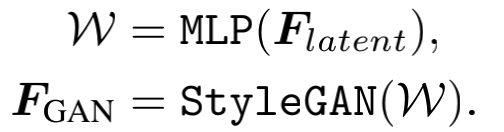
4.2.3 通道分割空间特征变换( Channel-Split Spatial Feature Transform)
模块为用
F
s
p
a
t
i
a
l
F_{spatial}
Fspatial调制(modulate)特征
F
G
A
N
F_{GAN}
FGAN。
首先用
F
s
p
a
t
i
a
l
F_{spatial}
Fspatial通过卷积生成缩放
α
\alpha
α和位移
β
\beta
β两个仿射变换参数。这两个参数对
F
G
A
N
F_{GAN}
FGAN进行变换,先点乘然后相加,公式表示如下
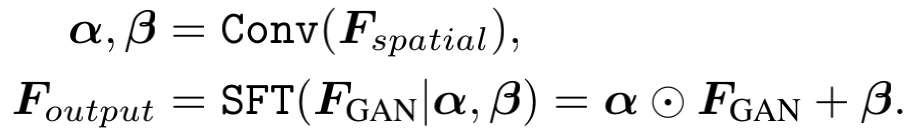
接着来说 F G A N F_{GAN} FGAN,他在通道方向倍分为两部分,一部分进行上边所说的仿射变换,另一部分不做任何变化,最后将这两部分concat后卷积融合的到最终输出。chnnel-split既能直接融合StyleGAN2中的先验信息,又可以有效调制输入图像。所以实现了保真和纹理真实的平衡,同样可以减少计算。
这个CS-SFT作用于每种分辨率的特征。
4.3 损失函数
4.3.1 重建损失 Reconstruction Loss
此部分包含重建图像和GT计算L1 Loss 和 感知loss。感知loss为将重建图像与GT送入预训练的VGG19网络,提取{Conv1, … , Conv5}激活前的特征,计算L1 loss
4.3.2 对抗损失 Adversarial Loss
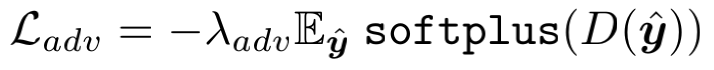
将重建图像送入判别器D,然后得到的输出经过Softplus激活函数后计算均值。其中Softplus函数可以看作平滑的ReLU,表示为 S o f t p l u s ( x ) = l o g ( 1 + e x ) Softplus(x) = log(1 + e^x) Softplus(x)=log(1+ex)
4.3.3 面部成分损失 Facial Component Loss
作者通过网络把左右眼,嘴巴使用ROI Align单独截取出来,送入三个小的判别器,然后计算损失。loss包含判别Loss和特征风格loss(feature style)
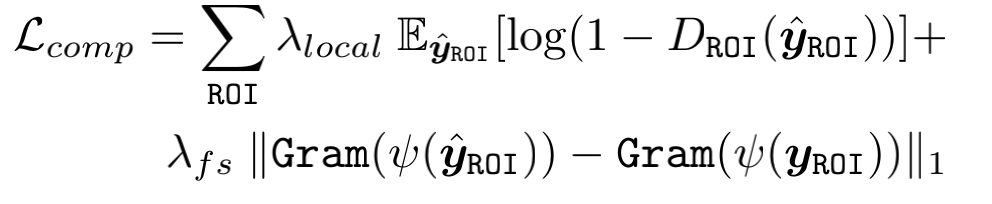
其中第一项是判别loss,将生成图像的ROI区域经过判别器得到输出
第二项为特征风格loss,将生成图与原图经过判别器时的多个不同分辨率的特征计算Gram矩阵相似度。Gram矩阵是用来计算特征相关性并且可以有效捕获纹理信息。从经验上看,在生成真实的面部细节和减少令人不快的伪影方面,特征风格loss 比以前的特征匹配loss表现得更好。
4.3.4 身份保持损失 Identity Preserving Loss
使用预训练的人脸识别模型ArcFace捕获身份识别的最突出特征。实现过程将生成图像与GT同时送入ArcFace得到特征,然后用L1 loss计算特征相似性。
5 Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data
使用纯仿真数据实现盲超分。所以本文的主要工作在于利用纯仿真数据来拟合真实世界将质的因素。至于网络结构只稍微改变了一下判别器。
5.1 摘要
作者说其他工作虽然也想盲超分,但是未知和复杂的降至来重建LR图像,但是和现实降质图像比差远了。所以我来提供一个高阶将质方案,当然我也考虑到了仿真数据常见的振铃和过冲伪影(ringing and overshoot artifacts)。因为咱要办的事变复杂了,所以用Unet来提升判别器的能力。
5.2 典型降质建模方法
全文主要介绍了四种降质方法。模糊(Blur),噪声(noise),降采(Resize(Downsampling)),JPEG压缩(JPEG compression)。用公式可以表示为
![]()
其中k表示模糊核,用来和原图做卷积;下箭头表示将采;n表示噪声;
[
‘
]
J
P
E
G
[`]_{JPEG}
[‘]JPEG表示JPEG压缩
5.2.1 模糊(Blur)
一般用线性模糊核卷积降质,常用各向同性和各向异性高斯核(Isotropic and
anisotropic Gaussian filters),接下来就是用公式讲高斯模糊核k怎么表示,不感兴趣可以忽略,感兴趣可以研究一下下面这两个公式。

其中
Σ
\Sigma
Σ表示协方差矩阵,具体如下;C表示空间坐标,N归一化常量。

σ
1
\sigma_1
σ1和
σ
2
\sigma_2
σ2两个主轴,当相等时,高斯核k为各向同性(Isotropic),否则为各向异性。
此外为了引入更多样的核形状,还采用了广义高斯模糊核(generalized Gaussian blur kernels)和高原状分布( plateau-shaped distribution)
5.2.2 噪声(Noise)
加性高斯噪声,作者会对RGB三通道分别或者一起加noise
泊松噪声,用来方针传感器噪声(sensor nosie),即在给定曝光水平下感测的光子数量的变化。
5.2.3 降采(Resize(Downsampling))
最近邻、区域调整、双线性插值、双立方差值
不同方法产生不同效果,有些生成模糊结果,有些生成尖锐信息。
5.2.4 JPEG压缩(JPEG compression)
首先将图像转到YCbCr颜色空间,然后将色度通道降采。然后将图像分割成8×8个块,每个块用二维离散余弦变换(DCT)进行变换。压缩率q在[0,100]区间,q越小,表示压缩率越高。
5.3 高阶降质建模
如图,作者认为上面这些流程走一遍也不行啊,还是和实际有很大gap,那就再多走几遍,但每次超参不同。

5.4 振铃和过冲伪影
振铃(ringing):图像尖锐变化附近的模糊边缘
过冲伪影(overshoot artifacts)过度边缘出的跳跃增加
都是因为信号带宽限制的结果
作者采用
s
i
n
c
sinc
sinc filter截取高频信息来仿真振铃,该函数用在两个地方,模糊处理和仿真的最后一步。至于最后一步是
s
i
n
c
sinc
sinc 还是JPEG压缩是随机的。
5.5 网络和训练
网络 :使用ESRGAN,但是判别器改为Unet。又因为Unet增加了训练的不稳定性,因此采用光谱归一化正则(spectral normalization regularization)来稳定训练,同时还可以缓解GAN训练导致的过度锐化和伪影。
训练:先用L1训练获得Real-ESRNet,指标为psnr
然后将其当作生成器,训练Real-ESRGAN,loss包含L1,GAN loss,Perceptual loss
小彩蛋
Real-ESRGAN的代码推论时会有一个参数–face-enhance,如果使用该参数,则直接调用GFP-GAN的网络生成结果,否则才会使用本网络。而GFP-GAN在推论时又会单独把脸裁剪出来,脸部使用GFP-GAN,其他背景使用Real-ESRGAN
最后多多评论交流哈,最好能点赞收藏一下















 942
942











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









