






源自:控制与决策
作者:李歆 李显 李帅 周晓锋 金樑
“人工智能技术与咨询” 发布
摘 要
实际多模态化工过程通常由于产品需求等调整而产生新模态, 现有基于深度学习的故障诊断方法存在未充分利用现有模态设计经验、小样本下难以训练模型等局限. 针对上述问题, 提出一种基于元学习(meta learning, ML)和网络结构搜索(neural architecture search, NAS)的新模态故障诊断方法MetaNAS. 首先, 利用NAS自动获取现有模态性能最优的网络模型; 然后, 利用ML从现有模态的NAS过程中学习故障诊断模型的设计经验; 最后, 当新模态产生时, 在已学习设计经验基础上进行梯度更新, 即在小样本条件下快速得到新模态故障诊断模型. 通过数值系统和田纳西伊斯曼(Tennessee Eastman, TE)化工过程的仿真实验充分验证所提出方法的有效性和可行性.
关键词
新模态 故障诊断 元学习 网络结构搜索 小样本
引 言
随着许多传感器和工业网络的发展, 现代化工正朝着大规模、分层、信息集成和强交互的方向发展, 导致化工生产过程频繁出现故障和产品质量不稳定的问题, 化工过程故障诊断是保证产品质量和确保生产高效运行的有效技术之一[1-2]. 在实际化工生产过程中, 产品等级或指标的调整、物料质量的波动和进料比的不平衡均会导致化工过程具有多模态特性[3]. 因此, 多模态特性广泛存在于现代制造业[4]. 与单模态过程相比, 多模态过程数据更加复杂, 通常表现为非线性时间相关、非高斯分布伴随新模态等[5]. 若将深度学习直接用于多模态化工过程, 将难以适应新模态等复杂特性, 并在小样本下难以构建准确的故障诊断模型[6-7]. 因此, 小样本下基于深度学习的新模态故障诊断方法具有研究价值[5].
现有多模态化工过程故障诊断方法可分为统计学习、机器学习和深度学习方法, 其中统计学习和机器学习方法研究起步较早[1-8]. 如: Zhao等[9]研究了采用多个局部PCA统计模型的局部模态故障诊断方法, 但是该方法在离线建模阶段需要利用准确的模态信息; 针对模态先验知识不完备问题, Tan等[10]将聚类方法应用于多模态化工过程, 有效地提高了故障诊断的准确率; Wang等[11]提出了基于不同模态间转换概率的稳定和过渡模态故障诊断方法; Natarajan等[12]通过计算测试数据到训练数据中心的最小距离, 给出选取局部最优PCA模型准则. 深度学习近年来在众多领域均取得了重要进展, 但是关于深度学习在多模态化工过程故障诊断方面的研究还相对较少, 如王玉静等[13]未考虑多模态局部差异特性, 将所有模态数据直接输入至深度学习网络中, 依靠模型强大的学习能力学习特征与故障间的非线性映射关系. 此外, 深度学习故障诊断模型的训练通常要求大量有标签数据, 但是新模态往往仅有少量数据. 如何在小样本条件下充分利用多模态过程特性和现有模态的模型设计经验, 快速构建基于深度学习的新模态故障诊断模型, 对保障实际化工过程安全和产品质量具有重要意义.
现有小样本数据学习方法可分为3类: 基于数据增强的方法、基于模型改进的方法、基于算法优化的方法[14]. 基于数据增强方法通过生成新数据, 达到扩充数据集的目的[15], 但是对于数据的操作不具有普适性, 且要求设计者对相关领域有足够的了解. 基于模型改进的方法通过限制模型复杂度、缩小假设空间、减少VC维进行小数据建模[16], 但是需要先验知识和设计者的丰富经验, 上述方法无法有效利用已有模态的设计经验. 基于算法优化的方法通过改进优化算法更快地搜索到合适的解[17], 元学习便是一种改进优化算法. 元学习方法的提出为解决现有模态的模型设计经验利用不充分和小样本等问题提供了研究思路[18], 如Finn等[19]提出MAML (model agnostic meta learning)方法, MAML首先训练一组初始化参数, 然后进行一步或多步的梯度调整来达到仅用少量数据便能够快速适应新任务的目的. 但是MAML对神经网络结构非常敏感, 需要耗时的超参数搜索来稳定训练和提高模型泛化能力[20]. 针对上述问题, Antoniou等[21]对MAML的鲁棒性、训练稳定性、内环超参数自动学习、推理和训练期间计算效率等方面进行优化, 显著提高了MAML的泛化性能, 但是同时也牺牲了计算量和内存量[22]. Nichol等[23]将MAML中计算二阶微分过程改为在每个任务中执行标准形式的随机梯度下降(stochastic gradient descent, SGD), 不用展开计算图或计算任意二阶导数, 降低了MAML所需的计算量和内存. 但是以上方法的网络结构单一, 不能随着任务的改变而变换网络结构, 且元学习面临网络结构设计繁琐、参数寻优耗时等问题.
为解决以上问题, 本文提出一种新模态故障诊断方法MetaNAS. 该方法利用元学习找到最优初始参数, 新模态在最优初始参数的基础上只需进行少数的几步梯度更新便能够找到表现最优的网络结构. MetaNAS通过元学习来学习已有模态故障诊断模型的设计经验, 即学习NAS中需要学习的最优初始参数, 使得新模态小样本下在最优初始参数的基础上进行少数的几步更新便得到故障诊断模型. 在此基础上, 通过赋予候选通道权重, 表示通道的重要性, 采用连续优化的权重替代离散的通道选取过程, 将离散的通道选取过程连续化. MetaNAS解决了通过NAS进行故障诊断存在的未充分利用现有模态设计经验、小样本下难以训练模型等局限.
本文的主要内容如下: 1) 所提出MetaNAS方法可自动设计故障诊断网络模型, 实现新模态小样本下的自动故障诊断; 2) 针对未充分利用现有模态设计经验、小样本下难以训练模型等问题, 采用元学习来学习现有模态的模型设计经验, 得到最优初始参数, 使得新模态在小样本下只需要少数几步的梯度更新便可得到故障诊断模型; 3) 通过连续松弛优化将离散的通道选择过程转换为连续的优化过程, 使得NAS更加高效、便捷.
1 基本方法
1.1 MAML
分别以D、Dmeta-train 、Dmeta-test 表示整个数据集、训练集和测试集, 在元学习中, 按照Dmeta-train 的分布p(T) 采样一系列任务T . 其中: 在第i 个任务中包含N 个类别, 每个类别有K 个样本, 将该问题称为一个N 类K 样本问题[19]. 每个N 类K 样本问题中数据又被分为训练集和测试集, 为了不混淆, 将Ti 中的训练集称为支持集(support set), 测试集称为查询集(query set), 分别记为
![]()
和
![]()
[19]. MAML的核心思想是在所有任务T 中学习一个最优的初始参数
![]()
, 使得Dmeta-test 在
![]()
的基础上进行一步或多步的梯度调整, 达到仅用少量数据便能够快速适应新任务、获得很好性能的目的. 按照如下规则学习最优的初始参数[19]:
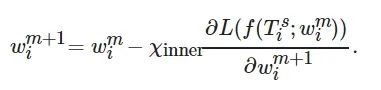
(1)
其中: χinner 为参数w 的内部学习率, m 为每个任务T 中的更新步长, f 为网络权重w 的参数化函数, L 为损失函数. 在内部学习过程中, 采用
![]()
计算任务Ti 的损失, 并令参数w 从
![]()
更新为
![]()
, 其中
![]()
. 在M 步后, 采用
![]()
中的
![]()
更新最优初始参数, 可表示为[19]
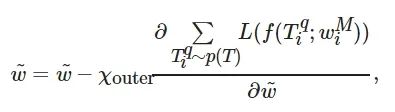
(2)
其中χouter 为参数
![]()
的外部学习率, 最终当模型收敛时, 得到最优初始参数
![]()
. 这使得初始参数非常敏感, 以至于在Dmeta-test上只需要更新几步便可得到较优的模型[19].
1.2 AutoFD
自动故障诊断(automatic fault diagnosis, AutoFD)[24]方法的核心思想是通过连续松弛优化将离散的网络搜索过程连续化, 将所有候选操作分别赋予权重; 然后再利用梯度下降分别对操作权重和网络参数进行优化; 接着利用操作权重参数选择对应的操作构成最终的网络模型.
设O 为候选操作集, 每个候选操作表示为o , 给定输入x , 则连续松弛优化后的操作输出
![]()
[24]为
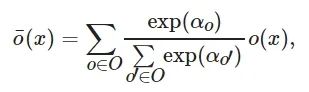
(3)
其中α 为操作权重向量, 表示不同候选操作在对应边中的重要性, 训练完成后根据操作权重参数选取最大的权重对应的操作为最终结果[24].
通过连续松弛优化, NAS问题转变为一个双优化问题, 运用双步更新算法可求解该问题[24], 有
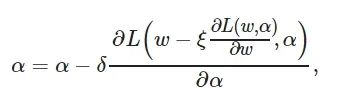
(4)
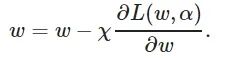
(5)
其中: L 为损失函数, ξ 为内部学习率[24].
2 MetaNAS故障诊断模型
针对现有方法存在未充分利用之前模态的模型设计经验以及需要大量特征数据等问题, 本文提出了MetaNAS方法, 方法整体流程如图 1所示. MetaNAS首先对候选通道赋予权重, 通过优化连续的权重替代选取通道的过程, 将离散的通道选取过程转变为连续的优化过程; 然后利用MAML[19]学习NAS[24]中需要学习参数的最优初始参数, 当有新的模态出现时, 在新模态仅有少量数据的情况下, 只需要在最优的初始参数的基础上进行少数的几步更新便得到较优的新模态故障诊断模型.
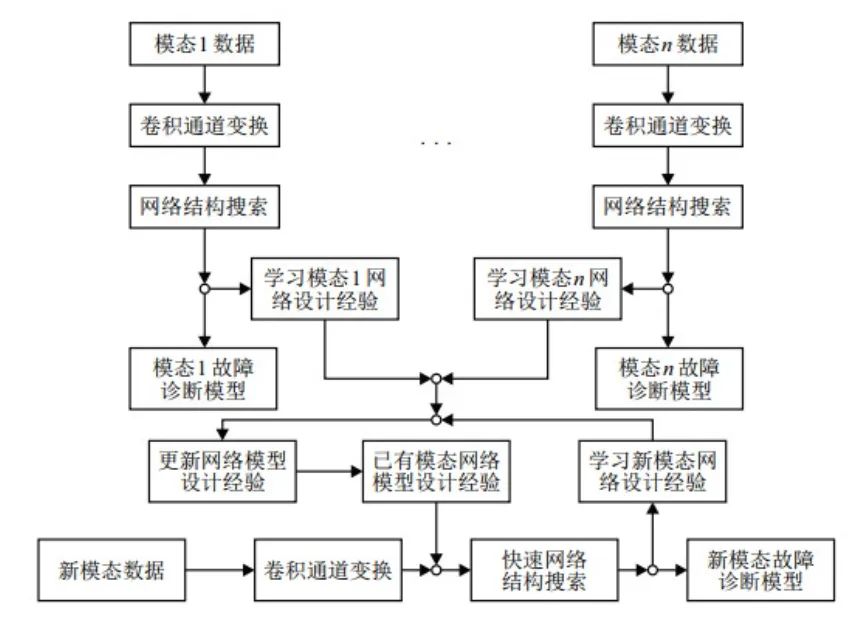
图 1 MetaNAS方法流程
2.1 通道权重参数
AutoFD[24]利用了多通道卷积增强网络的表现能力, 但是对卷积通道选择却非常耗时. 为了令NAS更高效, 本文利用连续松弛优化[24]将离散的卷积通道选择过程连续化. 以C={C1,C2,…,Cn} 表示候选通道集合, 将这个通道作为网络的候选输入通道, 即I={I1,I2,…,In} , 这些候选输入通道的选择过程是离散的, 将通道赋予一个权重β={β1,β2,…,βn} , 并通过Softmax函数将这些权重进行变换, 将候选通道集里所有的通道混合在一起, 得到一个混合的输入Input为
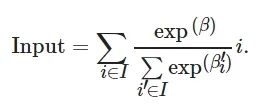
(6)
这样每个通道C 便和一个与其相对应的权重系数β 联系起来, 连续松弛优化利用连续的权重系数表示离散的候选通道[24]. 这个连续的权重系数表示对应的通道在网络输入中的重要程度, 因此可对网络在验证集上的表现采用梯度下降法以快速更新各操作的权重, 有效避免了训练所有网络输入并选出表现好的网络输入这一耗时的过程, 在搜索完成后, 选取权重系数前3大值所对应的通道, 作为最终操作卷积通[24].
通过以上方法, NAS问题转变为学习损失函数Lval(w∗,α∗,β∗) 最小的操作权重α∗ 、网络权重w∗ 和通道权重β∗ 值的双层优化问题[24], 即
![]()
(7)
![]()
(8)
![]()
(9)
2.2 MetaNAS方法
为了令新模态故障诊断的NAS过程更加高效, 本文利用MAML学习之前模态的设计经验, 在学习到的设计经验基础上, 对新模态化工过程进行NAS[24]. 第1.1节中MAML在训练集上训练, 得到了在新任务中快速适应的最优初始参数
![]()
. 同样, 在MetaNAS中采用训练集数据学习最优的网络初始参数
![]()
、操作权重初始参数
![]()
、通道权重初始参数
![]()
, 使得MetaNAS在新的任务上进行少数的几步梯度更新便能够快速得到较优的模型, 其中参数
![]()
、
![]()
、
![]()
均为第1.1节和第2.1节中定义的NAS参数.
为了学习之前模态的NAS设计经验, 本文基于MAML[19]的策略学习最优的NAS初始参数
![]()
、
![]()
、
![]()
. 类似于AutoFD[24], 操作权重参数α 、网络参数w 、通道权重参数β 不能独立地进行训练, 因此初始参数
![]()
、
![]()
、
![]()
也需要联合优化. 在MetaNAS中, 初始参数
![]()
、
![]()
、
![]()
也通过联合优化求解.
在第1.1节中利用式(1)和(2)更新最优初始参数
![]()
. 其中: 采用式(1)更新内部参数, 采用式(2)更新外部初始参数. 同样, MetaNAS也包含2个部分: 内部参数更新和外部初始参数更新. 内部参数更新部分, 在特定任务
![]()
中, NAS参数w 、α 、β 按照下式进行联合优化:
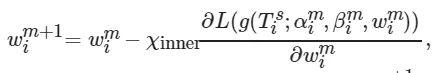
(10)
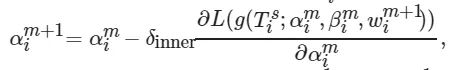
(11)
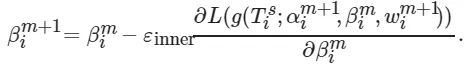
(12)
其中: χinner 为网络参数w 的内部学习率; δinner 为操作权重参数α 的内部学习率; εinner 为通道权重参数β 的内部学习率; g 为w 、α 、β 的参数化函数, 初始时:
![]()
. 在外部参数更新中, 为了得到一个最优的初始点, M 步后, 计算任务
![]()
中损失函数
![]()
, 按照下式联合优化参数
![]()
:
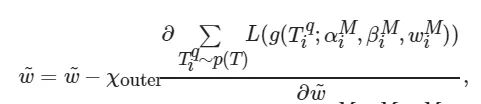
(13)
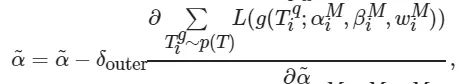
(14)
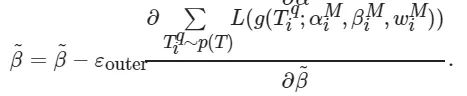
(15)
其中: χouter 为网络参数
![]()
的外部学习率, δouter 为操作权重参数
![]()
的外部学习率, εouter 为通道权重参数
![]()
的外部学习率. 当结果收敛, 便得到了最优的初始参数
![]()
, 新任务在参数
![]()
的基础上更新, 快速得到较优结果.
2.3 新模态故障在线诊断步骤
所提出的新模态化工过程故障诊断算法可分为建立模型、搜索阶段、训练优化阶段、实时诊断4个步骤, 具体如下.
step 1: 建立模型.
网络模型为由若干个卷积神经网络单元链接起来的两路支路, 且支路内、支路间各网络单元间经过边操作链接, 两路支路始端输入待处理的数据, 两路支路末端还连接用于输出故障诊断结果的全连接层, 所述网络单元内还包括边操作和节点, 单元内输入同样分为两路, 输出为一路, 同方法AutoFD[24]中的网络模型.
step 2: 搜索阶段.
step 2.1: 对多个模态的原始化工生产过程数据进行归一化和维度预处理, 使得满足元学习网络结构搜索的数据维度;
step 2.2: 对预处理后的数据施加操作, 构成多通道卷积的候选通道, 并与预处理后的数据拼接, 生成网络搜索阶段的输入;
step 2.3: 对候选输入通道分别赋予权重, 进一步得到混合输入;
step 2.4: 定义候选操作集, 并赋予每个操作一个权重;
step 2.5: 反复迭代以上step 2.3和step 2.4, 选用Adam/SGD优化器, 利用交叉熵损失函数, 反向传播调整网络参数、通道权重参数、操作权重参数, 从而得到最优的网络初始参数、通道最优初始参数、操作最优初始参数作为新模态的初始参数.
step 3: 训练优化阶段.
step 3.1: 对于新模态化工生产过程数据进行归一化和维度预处理, 使得满足元学习网络结构搜索的输入数据维度;
step 3.2: 将最优网络初始参数
![]()
、最优通道权重初始参数
![]()
、最优操作权重初始参数
![]()
作为初始参数对输入网络的新模态化工生产过程数据进行训练, 得到训练后优化的网络参数w∗ 、通道权重参数β∗ 、操作权重参数α∗ ;
step 3.3: 通过step 3.2优化得到的通道权重参数β∗ 、操作权重参数α∗ 筛选网络中选用的卷积通道和卷积操作, 获取新模态对应的故障诊断网络模型.
step 4: 实时诊断.
将实时得到的数据进行归一化和预处理, 使得满足网络的输入数据维度. 输入step 3.3得到的故障诊断网络模型, 将网络模型的输出作为实时诊断的结果.
3 实验验证
对于所有数据集, 在网络搜索阶段, 采用与AutoFD[24]相同的候选操作、候选卷积通道和网络的结构, 候选卷积通道
![]()
. 学习设计经验阶段的网络由操作权重参数
![]()
和通道权重参数
![]()
决定. 候选操作为: 3×3可分离卷积、5×5可分离卷积、3×3空洞卷积、5×5空洞卷积、3×3最大池化、3×3平均池化、保持原输入、清除原输入. 当有新的任务时, 便可在原网络结构参数的基础上更新得到最优网络结构
![]()
、
![]()
.
数据集首先被划分为验证集和测试集, 然后将训练集细分为训练集和验证集, 测试集细分为训练集和测试集. 为了便于区分, 将以上4个集合分别记为训练阶段的训练集、训练阶段的验证集、测试阶段的训练集、测试阶段的测试集.
首先在训练阶段的训练集中从选取好的N 个类别样本中随机抽取K 条数据作为一个任务T , 然后在训练阶段的验证集中从每个类别的样本中随机抽取10条数据作为训练阶段的测试数据. 因此在任务T 中应有N(K+10) 条数据, 在NAS过程中, 设网络训练Eoph为E1 , 每次均先随机抽取S1 个独立的任务, 然后再用这S1 个任务进行网络的搜索训练. 在内部搜索阶段, 选用普通的SGD优化网络的参数、操作权重参数、通道权重参数, 设内部搜索阶段内部学习率为χinner 、δinner 、εinner , 通过调整内部步长M 权衡网络的准确率和效率. 在外部搜索阶段, 选用Adam优化器优化网络的初始参数、操作权重初始参数、通道权重初始参数, 设外部学习率为χouter 、δouter 、εouter . 在验证阶段, 首先在测试阶段的训练集中从N 个类别的样本中随机抽取K 条数据作为一个任务T , 然后在测试阶段的测试集中从每个类别的样本中随机抽取Q 条数据作为验证阶段的测试数据, 因此在任务T 中应有N(K+Q) 条数据. 设网络训练Eoph为E2 , 每次均先随机抽取S2 个独立的任务, 最终的准确率为S2 个独立任务的平均诊断准确率.
所有训练和验证实验均是在配置Intel i7-10 875 H 2.30 GHz, 16 GB DDR 4, WDC PC SN 730, NVIDIA GeForce RTX 2 060的PC机上完成. 所有Python代码均在Pytorch框架下完成, 利用CUDA和cudnn提供的并行加速能力实现快速的训练和诊断任务.
3.1 数值系统案例
本文采取Ge等[25]提出的一个典型的多模态数值仿真模型进行测试, 此模型已被很多学者采用验证多模态算法的有效性, 模型的具体结构为
![]()
(16)
![]()
(17)
![]()
(18)
![]()
(19)
![]()
(20)
其中: x1 、x2 、x3 、x4 、x5 为5个变量; s1 、s2 分布不同; e1 、e2 、e3 、e4 、e5 为5个相互独立的噪声, 服从均值为0、标准差为0.01的高斯分布. 根据s1 、s2 的两种不同分布, 模型有两种不同的模态1 (mode 1)和模态2 (mode 2), 分别为[26]
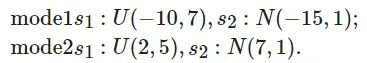
(21)
其中: U 为均匀分布, N 为高斯分布. 采集的每条数据包含了5个时刻的数据[d1,d2,d3,d4,d5],di为每个时刻的[x1,x2,x3, x4,x5] , 每条数据有25个特征. 对于每个模态, 首先生成1 000个正常样本, 然后生成的后1 000个样本为故障数据, 故障数据按照如下规则生成[26].
故障1: 在第1 001个样本开始加上幅值为4的阶跃信号;
故障2: 在第1001个样本开始加上0.02 (i -400)的斜坡信号;
故障3: 在第1 001样本开始加上幅度、偏移和频率均为1的正弦信号.
每个模态的正常和故障1 ∼ 故障3分别生成了1 000条数据. 其中: 将mode 1的4 000条数据作为训练集, 数据按照7 : 3的比例划分为训练集和验证集, 学习最优初始参数; mode 2也包含4 000条数据, 将数据按照7 : 3的比例划分为训练集和测试集.
数据集的划分按照类别N=4 , 数据条数K=10,50,100,150 , 网络训练Eoph的E1=10 , 随机抽取独立的任务个数S1=100 , 内部学习率χinner=0.05 、δinner=15 、εinner=15 , 内部步长M=4 , 外部学习率χouter=10−3 、δouter=10−3 、εouter=10−3 , 验证阶段的测试数据大小Q=150 , 网络训练Eoph的E2=5 , 随机抽取独立的任务个数为S2=80 , 数值系统多故障实验结果如表 1所示.
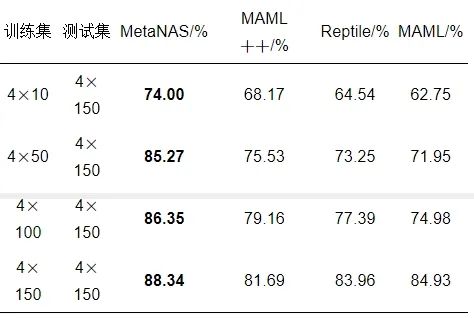
表 1 不同训练集规模下数值仿真多故障诊断准确率
由表 1可见, 随着在mode 2数据上训练集规模的增大, 各方法从数据中学习到的知识量也相应增加, MetaNAS、MAML++[21]、Reptile[23]、MAML[19] 的诊断准确率也随之上升. 训练集规模为4×10的MetaNAS诊断准确率高达74%, 而对比方法最高为MAML++的68.17%. 训练集规模为4×50的MetaNAS诊断准确率为85.27%, 对比方法均未超过76%. 训练集规模为4×100时, MetaNAS的诊断准确率为86.35%, 对比方法均未超过80%. 训练集规模为4×150时, MetaNAS的诊断准确率为88.34%, 对比方法均未超过84%. 在每类训练集的规模上, MetaNAS均取得了最高的诊断准确率.
3.2 TE多模态仿真
TE化工过程是一个标准实验仿真平台, 本文采用的是http://depts.washington.edu/control/LARRY/TE/download.html提供的TE仿真平台进行仿真[27]. 在多模态过程故障诊断实验研究中, 设置TE过程仿真平台中6种G/H产品比率获取6个模态下的正常工况和故障工况下的过程数据, 通过多模态TE过程的故障诊断实验验证MetaNAS的性能.
在每个模态正常工况仿真72 h, 采样间隔为3 min, 获得1 440个正常样本; 采集故障样本时设置了15种故障, 如表 2所示, 包括7种阶跃变化故障(故障1 ∼故障7)、5种随机变化故障(故障8 ∼故障12)、1个缓慢漂移故障(故障13)和两种堵塞故障(故障14和故障15), 在正常工况下仿真10个小时后引入故障, 继续仿真62个小时, 采样间隔为3 min, 即采集故障样本仿真过程中每次收集到200个正常样本和1 220个故障样本[27].
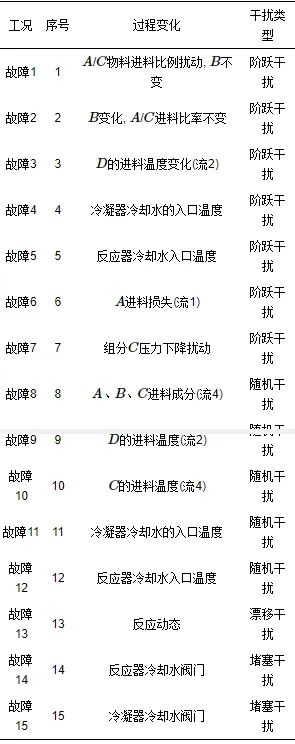
表 2 TE运行模式单故障描述[28]
在多模态过程故障诊断实验中, 对获取的6个模态过程数据, 选取各模态下1 000个正常样本(共6 000个正常样本)和每种故障1 000个样本(即每种故障6 000个样本)组成待使用数据集, 每条数据包含12个操作变量和41个过程变量, 每条数据的变量维度均为53, 在数据尾部充0, 再转换为8×8的二维矩阵作为网络的候选输入.
将模态1 ∼模态5的数据作为训练集, 模态6的数据作为测试集. 首先对多模态数据集进行单故障诊断实验, 数据集的划分N=2 , 数据条数K=10,50,100,150 , 网络训练Eoph的E1=12 , 随机抽取独立的任务个数S1=200 , 内部学习率χinner=0.05 、δinner=15 、εinner=15 , 内部步长M=4 , 外部学习率χouter=10−3 、δouter=10−3 、εouter=10−3 , 验证阶段的测试数据大小Q=150 , 网络训练Eoph的E2=6 , 随机抽取独立的任务个数为S2=90 , 单故障诊断结果如表 3所示.
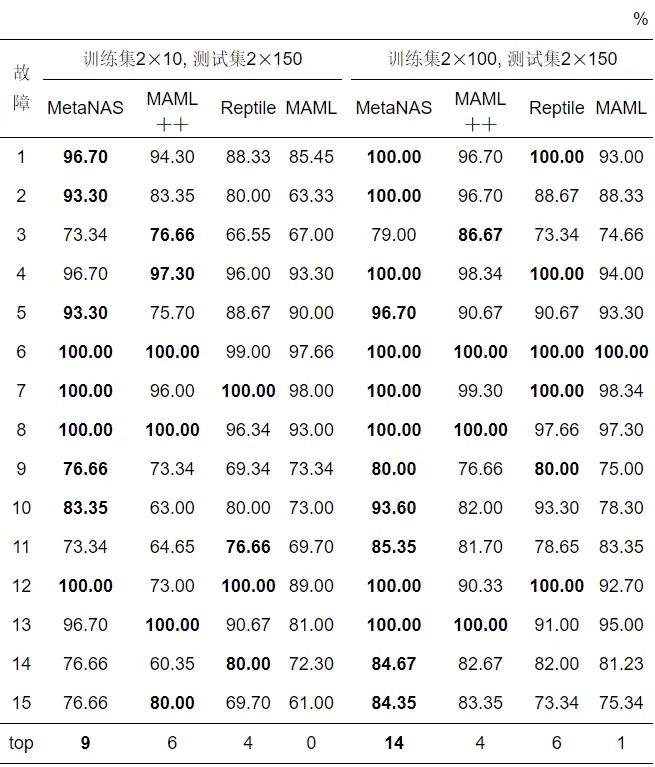
表 3 不同训练集规模下TE单故障诊断准确率
由表 3可见, 当训练规模为2×10时MetaNAS有9个故障均取得了最高的诊断准确率, 相比于MAML++的6个、Reptile的4个与MAML的0个取得了更好的诊断性能. 随着训练规模的增长, 当训练规模为2×100时, MetaNAS在15个故障中有14个故障均取得了最高的诊断准确率, 相比于MAML++的4个、Reptile的6个与MAML的1个取得了更好的诊断准确率, 且当训练集规模为2×100时, MetaNAS在故障1、故障2、故障4、故障6、故障7、故障8、故障12、故障13上均取得了100%的诊断准确率.
对多模态数据集进行多故障诊断实验, 选取正常0、故障1、故障8、故障13、故障15共5个工况作为研究对象, 涵盖了常见的阶跃干扰、随机干扰、漂移干扰、堵塞干扰等故障. 数据集的划分N=5 , 数据条数K=10,50,100,150 , 网络训练Eoph的E1=15 , 随机抽取独立的任务个数S1=500 , 内部学习率χinner=0.1 、δinner=30 、εinner=30 , 内部步长M=5 , 外部学习率χouterr=10−3 、δouterr=10−3 、εouterr=10−3 , 验证阶段的测试数据大小Q=150 , 网络训练Eoph的E2=10 , 随机抽取独立的任务个数为S2=100 , 多故障诊断结果如表 4所示.
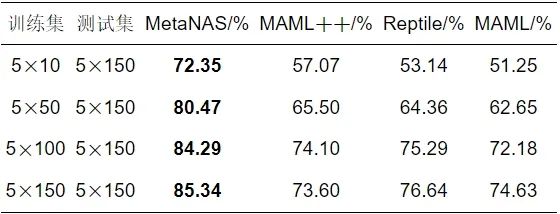
表 4 不同训练集规模下TE多故障诊断结果
由表 4可见, 随着模态6训练集规模的增大, MetaNAS、MAML++[21]、Reptile[23]、MAML[19]的诊断准确率均随之上升. 训练集规模为5×10的MetaNAS诊断准确率为72.35%, 而对比方法最高为MAML++的57.07%. 训练集规模为5×50的MetaNAS的诊断准确率为80.47%, 对比方法均未超过66%. 训练集规模为5×100时, MetaNAS的诊断准确率为84.29%, 对比方法均未超过76%. 训练集规模为5×150的MetaNAS的诊断准确率为85.34%, 对比方法均未超过77%. 在每类训练集的规模上, MetaNAS均取得了最高的诊断准确率.
由于MetaNAS的优点是利用设计经验, 为新模态设计特有网络结构, 不像MAML++[21]、Reptile[23]、MAML[19]一样使用固定网络模型, 因此它通常需要额外的时间开销来进行网络模型的生成. TE多故障实验过程中, MetaNAS、MAML、MAML++、Reptile方法模型参数量大小分别为2.4兆、3.2兆、3.2兆、3.2兆, 验证阶段每批次中MetaNAS比MAML多耗费约1.5 s的网络模型生成时间, 其中模型参数量通过thop.profile ()函数计算得到, 模型运行时间通过time.time ()函数计算得到.
总结以上3个实验可得出, 在大部分故障中MetaNAS的诊断准确率均高于MAML++[21]、Reptile[23]与MAML[19]等对比方法, MetaNAS在MAML的基础上利用AutoFD进行NAS, 为MAML提供了丰富的候选网络结构, 解决了元学习网络结构单一的问题, 且MetaNAS的网络模型不需要复杂耗时的设计过程. 对比3个实验结果中MetaNAS和MAML的结果可见, 在同一数据集的不同训练集规模情况下, MetaNAS的诊断结果均高于基础方法MAML, 表明MetaNAS在加入AutoFD后, 由于网络模型结构可学习, MetaNAS可获得更优的故障诊断能力, 且MetaNAS在众多故障中的故障诊断结果优于在MAML的基础上进行改进的MAML++[21]与Reptile[23]算法, 表明了MetaNAS方法的有效性.
4 结论
本文提出了MetaNAS方法, 该方法通过元学习找到NAS中需要学习的最优初始参数, 新模态在最优初始参数的基础上只需进行少数的几步梯度更新便能够找到表现最优的网络结构. MetaNAS利用NAS为元学习方法提供了丰富可学习的网络架构, 使得元学习的网络结构不再单一, 同时也使得网络设计自动化, 新模态在小样本下也可快速得到性能较优的故障诊断模型. 在此基础上, 通过对候选通道赋予权重和连续优化, 替代选取通道的过程, 将离散的通道选取过程转变为连续的优化过程. MetaNAS解决了通过NAS进行故障诊断存在的未充分利用现有模态设计经验、小样本下难以训练模型等局限. 通过数值系统和TE过程仿真验证了所提出方法在新模态小样本下故障诊断中的有效性和优越性. 但是现有的模型设计经验均是从同一化工过程的不同模态中获取, 缺少对不同工业过程模型设计经验的学习. 下一步的工作重点将放在关于不同工业过程模型设计经验的学习算法和不平衡数据集上的NAS算法研究.
声明:公众号转载的文章及图片出于非商业性的教育和科研目的供大家参考和探讨,并不意味着支持其观点或证实其内容的真实性。版权归原作者所有,如转载稿涉及版权等问题,请立即联系我们删除。
“人工智能技术与咨询” 发布


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









