







源自:系统工程与电子技术
作者:张堃, 华帅, 袁斌林, 杜睿怡
“人工智能技术与咨询” 发布
摘要
针对无人集群自主作战体系设计中的关键问题, 提出基于Multi-Agent的无人集群自主作战系统设计方法。建立无人集群各节点的Agent模型及其推演规则; 对于仿真系统模块化和通用化的需求, 设计系统互操作式接口和无人集群自主作战的交互关系; 开展无人集群系统仿真推演验证。仿真结果表明, 所提设计方案不仅能够有效开展并完成自主作战网络生成-集群演化-效能评估的全过程动态演示验证, 而且能够通过重复随机试验进一步评估无人集群的协同作战效能, 最后总结了集群协同作战的策略和经验。
关键词
Multi-Agent, 无人集群, 体系设计, 协同作战
引 言
近年来, 利用大量低成本、轻量级[1]的中小型无人机构建自主无人机作战群成为现代无人集群的一个重要发展方向[2]; 其可搭载各种电子设备或武器单元, 代替单一平台, 通过个体间行为紧密耦合协同来突破对动态复杂作战环境适应性的缺陷[3]。随着信息化军事变革越来越深入, 以网络中心战[4]和分布式杀伤[5]为代表的各种作战样式不断涌现, 这些基于信息栅格的网络化作战样式为当前传统集群的指挥控制方式带来了巨大冲击, 这使得对无人集群指挥控制的研究成为军事领域的研究热点。利用真实的战争对指挥控制领域的相关问题进行研究是最理想的, 但其成本和代价可能是无法估量和不可承受的。那么, 利用仿真对组织设计、任务规划等指挥控制相关问题进行深入研究就成为解决上述难题的有效手段。对于任何系统仿真, 都要先解决模型建立的问题, 指挥控制系统及其所属的作战环境是横跨物理域、信息域和认识域的复杂系统, 如何对这样一个复杂系统进行建模和仿真, 已成为当前急需解决的问题。
以组织理论为代表的传统指挥控制系统在设计上主要是基于效果的作战思维[6], 缺少对系统中各要素之间协同与对抗的动态策略设计, 将作战任务的划分简化为资源匹配问题, 缺少与现实指挥控制权限和指挥流程的考虑[7]。以复杂网络[8]和智能体[9]为代表的新型指挥控制系统虽然对系统的组织关系进行了一定程度的网络化描述, 但是缺少对组织结构中指挥体制、指挥流程以及智能体的组织规则的设计与描述。
因此, 为实现无人集群的自主作战, 需要分布式智能指挥控制系统进行支撑, 该作战系统主要包括态势感知、作战规划与决策、行动控制、仿真推演与训练、人机交互等智能技术。本文从无人集群算法和软件部署架构的特殊性考虑, 由于无人集群的分布式和无中心式特性[10], 其特征与人工智能Agent的特点相符[11], 最容易用Agent的思想对无人集群的分布式特性进行建模, 故本文通过对Agent仿真建模方法以及作战空间中各实体特性的研究, 提出适合仿真实体的Agent仿真建模方法, 并对如何管理和调度Agent实体模型进行探索和尝试, 然后搭建分布式Agent指挥控制仿真环境, 对指挥控制领域的具体问题进行研究, 通过构建无人集群自主作战系统, 验证仿真实体建模方法和管理调度技术的可行性。
1 系统架构设计
计算机领域中Agent技术的研究和应用源于美国麻省理工学院的分布式人工智能(distributed artificial intelligence, DAI)的研究项目, 其不仅是一种解决复杂的学习、规划和决策问题的方法[12], 而且也是解决新的分布式应用问题的有效途径。DAI系统通常由具有自主学习能力的处理节点Agent组成, 这些节点分散在很大的范围内, 能够独立运作, 也可通过部分节点间的通信来完成协作[13]。Multi-Agent系统(Multi-Agent system, MAS)[14]是一个有组织、有序的Agent群体, 是对Agent的一种聚合。系统中各Agent能够相互通信, 并在通信的基础上建立协作关系。Agent能够根据用户设定的规则以及相互之间的协议对冲突或自身需求进行沟通, 这样就能产生合力, 促进整个系统的效能提升。
1.1 Multi-Agent体系结构
基于Agent建模是在系统抽象时利用Agent作为基本抽象单位, 可赋予Agent一些决策能力, 并预先设定好Agent间的沟通方式, 这样就得到一个系统的抽象模型[15]。整个建模过程既可以从总体体系架构开始, 并延伸到个体, 为每个系统单元设计适合的Agent, 也可先设计好每个Agent, 再按照MAS架构设计Agent之间的交互方式。很多文献都将Agent典型结构描述成由3个基本单元组成, 分别是传感器[16]、处理器[17]和效应器[18]。由于典型结构将所有Agent自主能力和智能行为笼统地以一个处理器来体现, 这会给此处理器的设计带来很大困难。基于对以上问题的考虑, 为了适配无人机集群协同自主作战的需求, 本文将采用多智能体体系设计基本作战单元, 其结构示意图如图 1所示。
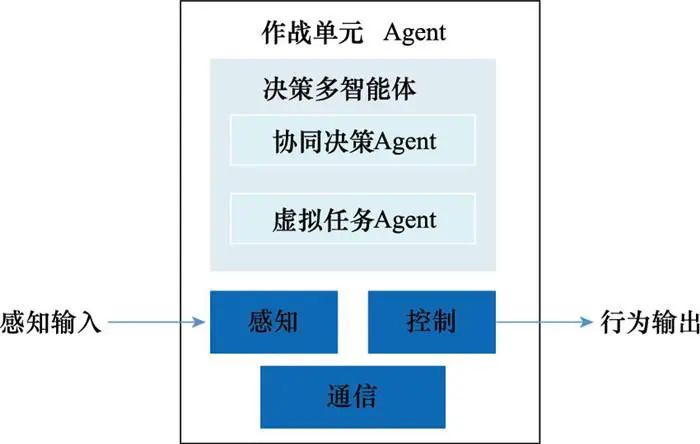
图1 作战单元结构示意图
1.2 Agent模型定义
根据以上Agent类型结构, 为进一步研究Agent行为、关系、通信和交互, 对Agent模型做以下定义: 形式化状态S和行为B共同构成Agent, 其表达式如下所示:

(1)
(1) 状态相关描述
分别从事件、状态、状态空间等角度对Agent状态进行描述, 具体描述及定义如下。
定义1 事件。在特定时间, 系统的状态变化称为事件。
定义2 状态。事物所有属性的表达形式称为状态。对于对象在特定时间的状态, 有如下所示:
![]()
(2)
定义3 状态域。状态域用于描述模型Agent中的某些特征属性。在状态S=(S1, S2, …, Sn)中, S1, S2, …, Sn表示状态域。
定义4 状态空间。如果系统有N个状态, 则状态域的域值构成一个N维状态空间, 如下所示:
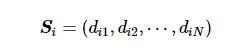
(3)
定义5 传递函数。系统的映射Q: f: S→S′即为传递函数, 具体如下所示:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 288
288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









