






模型简介
当前有四大生成模型:生成对抗模型、变微分自动编码器、流模型以及扩散模型。
扩散模型在诸多应用领域都有出色的表现,如计算机视觉,NLP、波形signal处理、多模态建模、分子图建模、时间序列建模、对抗性净化等。
原理:扩散现象
物理:物质分子从高浓度向低浓度区域转移,直到均匀分布。
AI:由熵增定律驱动,先给一幅图片增加噪声,让其变得极其混乱,再训练AI把混乱的照片变回有序(实现图片生成)。
Diffusion对于图像的处理包括以下两个过程:
-
我们选择的固定(或预定义)正向扩散过程 q :它逐渐将高斯噪声添加到图像中,直到最终得到纯噪声
-
一个learn的反向去噪的扩散过程 pθ:通过训练神经网络从纯噪声开始逐渐对图像去噪,直到最终得到一个实际的图像
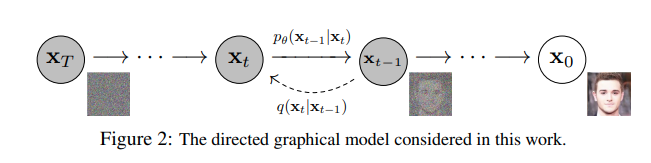
1.前向过程(加噪)
1)不断往输入数据中增加噪声,最后变为纯噪声(#噪声(Noise):是真实标记与数据集中的实际标记间的偏差。)。
2)每一个时刻都要增加高斯噪声,后一时刻都是前一时刻增加噪声得到。
3)这个过程可以看做不断构建标签的过程。
前向过程是不断加噪的过程,加入的噪声随着时间步增加增多,根据马尔可夫定理,加噪后的这一时刻与前一时刻的相关性最高也与要加的噪音有关(是与上一时刻的影响大还是要加的噪音影响大,当前向时刻越往后,噪音影响的权重越来越大了,因为刚开始加一点噪声就有效果,之后要加噪声越来越多 )
2.逆向过程(去噪)
从一个随机噪声开始,逐步还原成不带噪音的原始图片——去噪过程,逆向过程其实时生成数据的过程。
U-Net神经网络预测噪声
神经网络需要在特定时间步长接收带噪声的图像,并返回预测的噪声。请注意,预测噪声是与输入图像具有相同大小/分辨率的张量。因此,从技术上讲,网络接受并输出相同形状的张量。那么我们可以用什么类型的神经网络来实现呢?
这里通常使用的是非常相似的自动编码器,您可能还记得典型的“深度learning入门”教程。自动编码器在编码器和解码器之间有一个所谓的“bottleneck”层。编码器首先将图像编码为一个称为“bottleneck”的较小的隐藏表示,然后解码器将该隐藏表示解码回实际图像。这迫使网络只保留bottleneck层中最重要的信息。
在模型结构方面,DDPM的作者选择了U-Net,出自(Ronneberger et al.,2015)(当时,它在医学图像分割方面取得了最先进的结果)。这个网络就像任何自动编码器一样,在中间由一个bottleneck组成,确保网络只learn最重要的信息。重要的是,它在编码器和解码器之间引入了残差连接,极大地改善了梯度流(灵感来自于(He et al., 2015))。
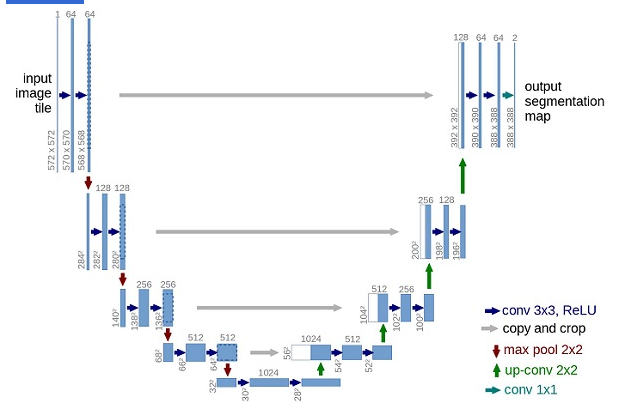
可以看出,U-Net模型首先对输入进行下采样(即,在空间分辨率方面使输入更小),之后执行上采样。
用猫图像说明如何在扩散过程的每个时间步骤中添加噪音。
from PIL import Image
image = Image.open('./image_cat/jpg/000000039769.jpg')
base_width = 160
image = image.resize((base_width, int(float(image.size[1]) * float(base_width / float(image.size[0])))))
image.show()复制
噪声被添加到mindspore张量中,而不是Pillow图像。我们将首先定义图像转换,允许我们从PIL图像转换到mindspore张量(我们可以在其上添加噪声),反之亦然。
这些转换相当简单:我们首先通过除以255255来标准化图像(使它们在 [0,1][0,1] 范围内),然后确保它们在 [−1,1][−1,1] 范围内
from mindspore.dataset import ImageFolderDataset
image_size = 128
transforms = [
Resize(image_size, Inter.BILINEAR),
CenterCrop(image_size),
ToTensor(),
lambda t: (t * 2) - 1
]
path = './image_cat'
dataset = ImageFolderDataset(dataset_dir=path, num_parallel_workers=cpu_count(),
extensions=['.jpg', '.jpeg', '.png', '.tiff'],
num_shards=1, shard_id=0, shuffle=False, decode=True)
dataset = dataset.project('image')
transforms.insert(1, RandomHorizontalFlip())
dataset_1 = dataset.map(transforms, 'image')
dataset_2 = dataset_1.batch(1, drop_remainder=True)
x_start = next(dataset_2.create_tuple_iterator())[0]
print(x_start.shape)复制![]()
我们还定义了反向变换,它接收一个包含 [−1,1][−1,1] 中的张量,并将它们转回 PIL 图像:
import numpy as np
reverse_transform = [
lambda t: (t + 1) / 2,
lambda t: ops.permute(t, (1, 2, 0)), # CHW to HWC
lambda t: t * 255.,
lambda t: t.asnumpy().astype(np.uint8),
ToPIL()
]
def compose(transform, x):
for d in transform:
x = d(x)
return x
复制让我们验证一下:
reverse_image = compose(reverse_transform, x_start[0])
reverse_image.show()
复制
我们现在可以定义前向扩散过程,如本文所示:
def q_sample(x_start, t, noise=None):
if noise is None:
noise = randn_like(x_start)
return (extract(sqrt_alphas_cumprod, t, x_start.shape) * x_start +
extract(sqrt_one_minus_alphas_cumprod, t, x_start.shape) * noise)
复制让我们在特定的时间步长上测试它:
def get_noisy_image(x_start, t):
# 添加噪音
x_noisy = q_sample(x_start, t=t)
# 转换为 PIL 图像
noisy_image = compose(reverse_transform, x_noisy[0])
return noisy_image
# 设置 time step
t = Tensor([40])
noisy_image = get_noisy_image(x_start, t)
print(noisy_image)
noisy_image.show()
复制![]()

我们现在可以定义给定模型的损失函数,如下所示:
def p_losses(unet_model, x_start, t, noise=None):
if noise is None:
noise = randn_like(x_start)
x_noisy = q_sample(x_start=x_start, t=t, noise=noise)
predicted_noise = unet_model(x_noisy, t)
loss = nn.SmoothL1Loss()(noise, predicted_noise)# todo
loss = loss.reshape(loss.shape[0], -1)
loss = loss * extract(p2_loss_weight, t, loss.shape)
return loss.mean()
复制denoise_model将是我们上面定义的U-Net。我们将在真实噪声和预测噪声之间使用Huber损失。
数据准备与处理
在这里我们定义一个正则数据集。数据集可以来自简单的真实数据集的图像组成,如Fashion-MNIST、CIFAR-10或ImageNet,其中线性缩放为 [−1,1][−1,1] 。
每个图像的大小都会调整为相同的大小。有趣的是,图像也是随机水平翻转的。根据论文内容:我们在CIFAR10的训练中使用了随机水平翻转;我们尝试了有翻转和没有翻转的训练,并发现翻转可以稍微提高样本质量。
本实验我们选用Fashion_MNIST数据集,我们使用download下载并解压Fashion_MNIST数据集到指定路径。此数据集由已经具有相同分辨率的图像组成,即28x28。

训练过程
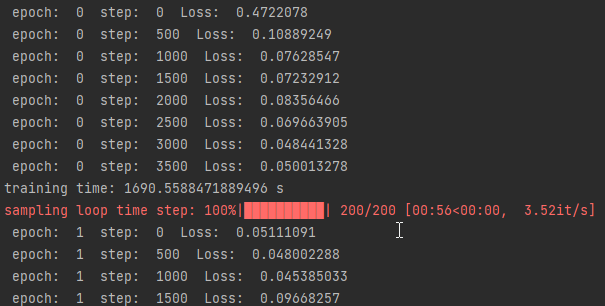
推理过程(从模型中采样)
要从模型中采样,我们可以只使用上面定义的采样函数:
# 采样64个图片
unet_model.set_train(False)
samples = sample(unet_model, image_size=image_size, batch_size=64, channels=channels)
# 展示一个随机效果
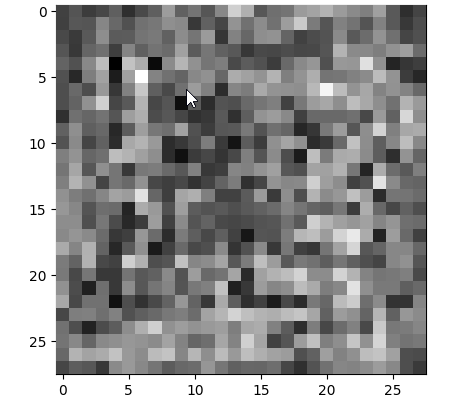
random_index = 5
plt.imshow(samples[-1][random_index].reshape(image_size, image_size, channels), cmap="gray")
复制
可以看到这个模型能产生一个不知道是什么的图像,按理应该是一件衣服。
loss 稍微高了一点。
请注意,我们训练的数据集分辨率相当低(28x28)。
我们还可以创建去噪过程的gif:















 7494
7494











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









