






AVX-512
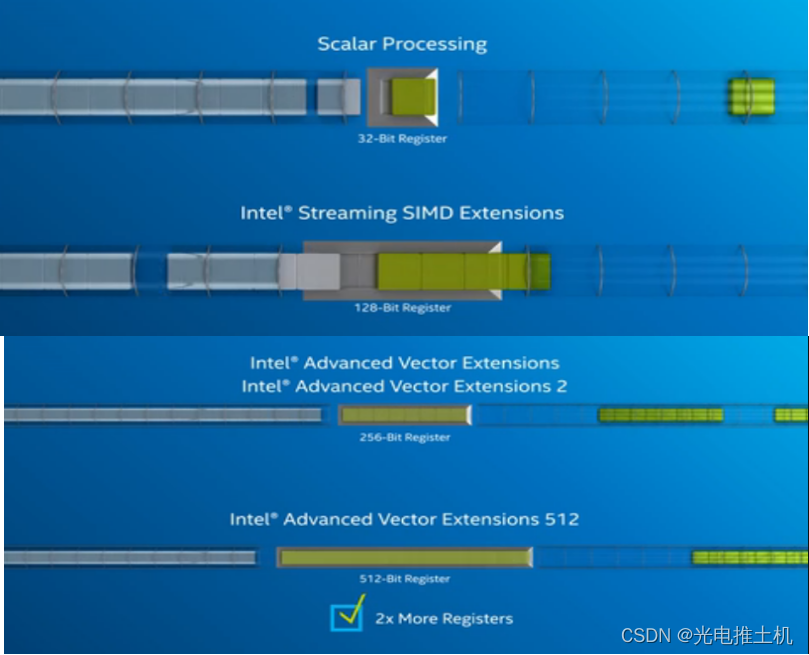
• 可用于Skylake server CPUs
• 32 512-bit registers: ZMM0 to ZMM31
• can be interpreted as
I 64 8-bit integers
I 32 16-bit integers
I 16 32-bit integers
I 8 64-bit integers
I 16 32-bit floats
I 8 64-bit floats

• extensive and fairly orthogonal set of operations
• Skylake server CPUs have 2 AVX-512 processing units and can therefore process 128 bytes
per cycle
• important subsets: AVX-512F (foundation), AVX-512BW (byte, word), AVX-512DQ
(doubleword and quadword instructions), AVX-512CD (lzcnt and conflict detection)
ZMM registers are represented as special data types:
I __m512i (all integer types, width is specified by operations)
I __m512 (32-bit floats)
I __m512d (64-bit floats)
Getting Data To/From Registers
• aligned load (memory location has to be 64-byte aligned):
__m512i _mm512_load_si512 (void const* mem_addr)
• unaligned load (slightly slower):
__m512i _mm512_loadu_si512 (void const* mem_addr)
• broadcast a single value (available for different widths):
__m512i _mm512_set1_epi32 (int a)
• there is no instruction for loading a 64-byte constant into a register (must happen through
memory); however, there is a convenient (but slow) intrinsic for that:
__m512i _mm512_set_epi32(int e15, …, int e0)
(arguments can also be specified in reverse: setr)
• store:
void _mm512_store_epi32 (void* mem_addr, __m512i a)
Arithmetic Operations
• addition/subtraction: add, sub
• multiplication (truncated): mullo (16, 32, or 64 bit input, output size same as input)
• saturated addition/subtraction: adds, subs (stays at extremum instead of wrapping, only 8
and 16 bits)
• absolute value: abs
• extrema: min/max
• multiplication (full precision): mul (only 32 bit input, produces 64 bit output)
• some of these are also available as unsigned variants (epu suffix)
• no integer division/modulo1
• no overflow detection
Logical and Bitwise Operations
• logical: and, andnot, or, xor
• rotate left (right) by same value: rol (ror)
• rotate left (right) by different values: rolv (rorv)
• shift2
left (right) by same value: slli (srli)
• shift left (right) by different values: sllv (srlv)
• convert different sizes (zero/sign-extend, truncate): cvt
• count leading zeros: lzcnt
Comparisons
• compare 32-bit integers:
__mmask16 _mm512_cmpOP_epi32_mask (__m512i a, __m512i b)
• OP is one of (eq, ge, gt, le, lt, neq)
• comparisons may also take a mask as input, which is equivalent to performing AND on the
masks
• assumes signed integers3
• result is a bitmap stored in a special “opmask” register (K1-K7) and is available as special
data type (__mmask8 to __mmask64)
Operations on Masks
• operations on masks: kand, knand, knot, kor, kxnor, kxor
• __mmask16 _kand (__mmask16 a, __mmask16 b)
• masks are automatically converted to integers
• to count number of bit set to 1: __builtin_popcount(mask)
Zero Masking
• selectively ignore some of the SIMD lanes (using a bitmap)
• almost all operations support masking
• add elements, but set thos not selected by mask to zero:
__m512i _mm512_maskz_add_epi32 (__mmask16 k, __m512i a, __m512i b)
Masking with Merging/Blending
• blend new result with previous result (“merge”):
__m512i _mm512_mask_add_epi32 (__m512i src, __mmask16 k, __m512i a,
__m512i b)
• there are also blending only instructions:
__m512i _mm512_mask_blend_epi32 (__mmask16 k, __m512i a, __m512i b)
参考:
https://db.in.tum.de/teaching/ws1718/dataprocessing/chapter2.pdf
















 8015
8015











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









