








前言
在以前的文章中,我们介绍了支持向量机的基本表达式,那是基于硬间隔线性支持向量机的,即是假设数据是完全线性可分的,在数据是近似线性可分的时候,我们不能继续使用硬间隔SVM了,而是需要采用软间隔SVM,在这里我们简单介绍下软间隔线性支持向量机。本人无专业的数学学习背景,只能在直观的角度上解释这个问题,如果有数学专业的朋友,还望不吝赐教。 如有误,请联系指正。转载请注明出处。
∇ \nabla ∇ 联系方式:
e-mail: FesianXu@gmail.com
QQ: 973926198
github: https://github.com/FesianXu
知乎专栏: 计算机视觉/计算机图形理论与应用
微信公众号:

软间隔最大化
在文章《SVM的拉格朗日函数表示以及其对偶问题》和《SVM支持向量机的目的和起源》中,我们推导了SVM的基本公式,那时的基本假设之一就是数据是完全线性可分的,即是总是存在一个超平面 W T X + b W^TX+b WTX+b可以将数据完美的分开,但是正如我们在《SVM的拉格朗日函数表示以及其对偶问题》中最后结尾所说的:
但是,在现实生活中的数据往往是或本身就是非线性可分但是近似线性可分的,或是线性可分但是具有噪声的,以上两种情况都会导致在现实应用中,硬间隔线性支持向量机变得不再实用
因此,我们引入了软间隔线性支持向量机这个概念,硬间隔和软间隔的区别如下图所示:
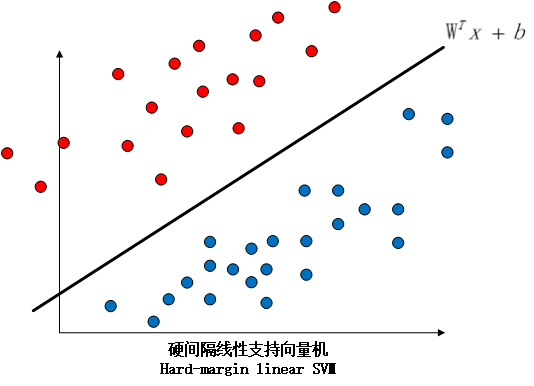
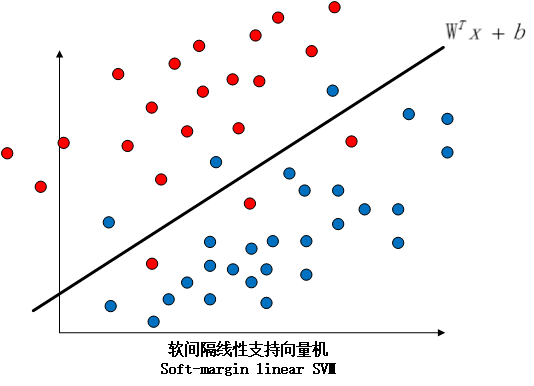
我们的解决方案很简单,就是在软间隔SVM中,我们的分类超平面既要能够尽可能地将数据类别分对,又要使得支持向量到超平面的间隔尽可能地大。具体来说,因为线性不可分意味着某些样本点不能满足函数间隔大于等于1的条件,即是
∃
i
,
1
−
y
i
(
W
T
x
i
+
b
)
>
0
\exists i, 1-y_i(W^Tx_i+b) > 0
∃i,1−yi(WTxi+b)>0。解决方案就是通过对每一个样本点
(
x
i
,
y
i
)
(x_i, y_i)
(xi,yi)引入一个松弛变量
ξ
i
≥
0
\xi_i \geq 0
ξi≥0,对于那些不满足约束条件的样本点,使得函数间隔加上松弛变量之后大于等于1,于是我们的约束条件就变为了:
y
i
(
W
T
x
i
+
b
)
+
ξ
i
≥
1
=
y
i
(
W
T
x
i
+
b
)
≥
1
−
ξ
i
(1.1)
y_i(W^T x_i+b)+\xi_i \geq 1 \\ = y_i(W^T x_i+b) \geq 1-\xi_i \tag{1.1}
yi(WTxi+b)+ξi≥1=yi(WTxi+b)≥1−ξi(1.1)
图像表示如:
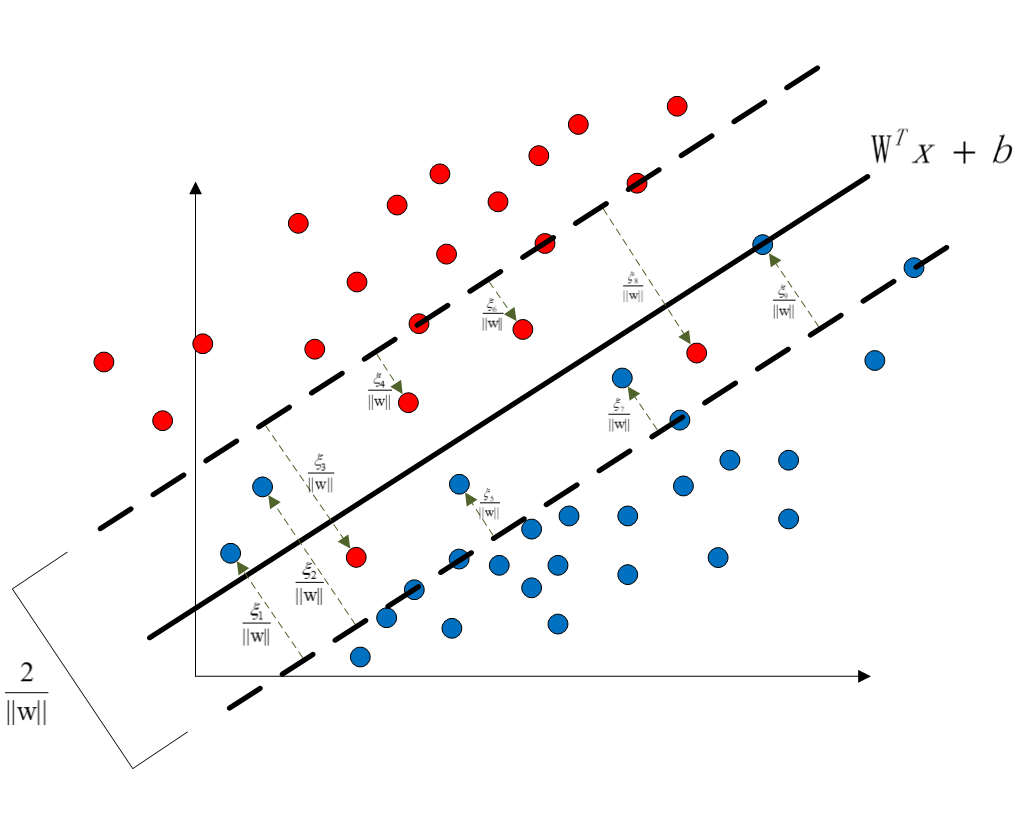
超平面两侧对称的虚线为支持向量,支持向量到超平面的间隔为1。在硬间隔SVM中本应该是在虚线内侧没有任何的样本点的,而在软间隔SVM中,因为不是完全的线性可分,所以虚线内侧存在有样本点,通过向每一个在虚线内侧的样本点添加松弛变量
ξ
i
\xi_i
ξi,将这些样本点搬移到支持向量虚线上。而本身就是在虚线外的样本点的松弛变量则可以设为0。
于是,给每一个松弛变量赋予一个代价
ξ
i
\xi_i
ξi,我们的目标函数就变成了:
f
(
W
,
ξ
)
=
1
2
∣
∣
W
∣
∣
2
+
C
∑
i
=
1
N
ξ
i
i
=
1
,
2
,
⋯
,
N
(1.2)
f(W, \xi) = \frac{1}{2}||W||^2+C \sum_{i=1}^N\xi_i \\ i = 1,2, \cdots,N \tag{1.2}
f(W,ξ)=21∣∣W∣∣2+Ci=1∑Nξii=1,2,⋯,N(1.2)
其中
C
>
0
C > 0
C>0称为惩罚参数,C值大的时候对误分类的惩罚增大,C值小的时候对误分类的惩罚减小,
(
1.2
)
(1.2)
(1.2)有两层含义:使得
1
2
∣
∣
W
∣
∣
2
\frac{1}{2}||W||^2
21∣∣W∣∣2尽量小即是间隔尽可能大,同时使得误分类的数量尽量小,C是调和两者的系数,是一个超参数。
于是我们的软间隔SVM的问题可以描述为:
min
W
,
b
,
ξ
1
2
∣
∣
W
∣
∣
2
+
C
∑
i
=
1
N
ξ
i
s
.
t
.
y
i
(
W
T
x
i
+
b
)
≥
1
−
ξ
i
ξ
i
≥
0
i
=
1
,
2
,
⋯
,
N
(1.3)
\min_{W,b,\xi} \frac{1}{2}||W||^2+C \sum_{i=1}^N\xi_i \\ s.t. y_i(W^T x_i+b) \geq 1-\xi_i \\ \xi_i \geq 0 \\ i = 1,2, \cdots, N \tag{1.3}
W,b,ξmin21∣∣W∣∣2+Ci=1∑Nξis.t. yi(WTxi+b)≥1−ξiξi≥0i=1,2,⋯,N(1.3)
表述为标准形式:
min
W
,
b
,
ξ
1
2
∣
∣
W
∣
∣
2
+
C
∑
i
=
1
N
ξ
i
s
.
t
.
1
−
ξ
i
−
y
i
(
W
T
x
i
+
b
)
≤
0
−
ξ
i
≤
0
i
=
1
,
2
,
⋯
,
N
(1.4)
\min_{W,b,\xi} \frac{1}{2}||W||^2+C \sum_{i=1}^N\xi_i \\ s.t. 1-\xi_i-y_i(W^T x_i+b) \leq 0 \\ -\xi_i \leq 0 \\ i = 1,2, \cdots, N \tag{1.4}
W,b,ξmin21∣∣W∣∣2+Ci=1∑Nξis.t. 1−ξi−yi(WTxi+b)≤0−ξi≤0i=1,2,⋯,N(1.4)
软间隔SVM的拉格朗日函数表述和对偶问题
我们采用《SVM的拉格朗日函数表示以及其对偶问题》中介绍过的相似的方法,将
(
1.4
)
(1.4)
(1.4)得到其对偶问题。过程如下:
将
(
1.4
)
(1.4)
(1.4)转换为其拉格朗日函数形式:
L
(
W
,
b
,
ξ
,
α
,
β
)
=
1
2
∣
∣
W
∣
∣
2
+
C
∑
i
=
1
N
ξ
i
+
∑
i
=
1
N
α
i
(
1
−
ξ
i
−
y
i
(
W
T
x
i
+
b
)
)
−
∑
i
=
1
N
β
i
ξ
i
=
1
2
∣
∣
W
∣
∣
2
+
C
∑
i
=
1
N
ξ
i
+
∑
i
=
1
N
α
i
−
∑
i
=
1
N
α
i
ξ
i
−
∑
i
=
1
N
α
i
y
i
(
W
T
x
i
+
b
)
−
∑
i
=
1
N
β
i
ξ
i
(2.1)
L(W, b, \xi, \alpha, \beta) = \frac{1}{2}||W||^2+C \sum_{i=1}^N\xi_i+\sum_{i=1}^N \alpha_i(1-\xi_i-y_i(W^T x_i+b))- \sum_{i=1}^N \beta_i \xi_i \\ = \frac{1}{2}||W||^2+C \sum_{i=1}^N\xi_i+ \sum_{i=1}^N \alpha_i - \sum_{i=1}^N \alpha_i \xi_i - \sum_{i=1}^N \alpha_i y_i(W^T x_i+b) - \sum_{i=1}^N \beta_i \xi_i \\ \tag{2.1}
L(W,b,ξ,α,β)=21∣∣W∣∣2+Ci=1∑Nξi+i=1∑Nαi(1−ξi−yi(WTxi+b))−i=1∑Nβiξi=21∣∣W∣∣2+Ci=1∑Nξi+i=1∑Nαi−i=1∑Nαiξi−i=1∑Nαiyi(WTxi+b)−i=1∑Nβiξi(2.1)
原问题可以表述为(具体移步《最优化问题的对偶问题》):
min
W
,
b
,
ξ
max
α
,
β
L
(
W
,
b
,
ξ
,
α
,
β
)
(2.2)
\min_{W,b,\xi} \max_{\alpha, \beta} L(W, b, \xi, \alpha, \beta) \tag{2.2}
W,b,ξminα,βmaxL(W,b,ξ,α,β)(2.2)
得到其对偶问题为:
max
α
,
β
min
W
,
b
,
ξ
L
(
W
,
b
,
ξ
,
α
,
β
)
(2.3)
\max_{\alpha, \beta} \min_{W, b, \xi} L(W, b, \xi, \alpha, \beta) \tag{2.3}
α,βmaxW,b,ξminL(W,b,ξ,α,β)(2.3)
我们先求对偶问题
θ
D
(
α
,
β
)
=
min
W
,
b
,
ξ
L
(
W
,
b
,
ξ
,
α
,
β
)
\theta_D(\alpha, \beta) = \min_{W, b, \xi} L(W, b, \xi, \alpha, \beta)
θD(α,β)=minW,b,ξL(W,b,ξ,α,β),根据KKT条件(具体移步《拉格朗日乘数法和KKT条件的直观解释》),我们有:
∇
W
L
(
W
,
b
,
ξ
,
α
,
β
)
=
W
−
∑
i
=
1
N
α
i
y
i
x
i
=
0
(2.4)
\nabla_{W} L(W, b, \xi, \alpha, \beta) = W-\sum_{i=1}^N\alpha_i y_i x_i = 0 \tag{2.4}
∇WL(W,b,ξ,α,β)=W−i=1∑Nαiyixi=0(2.4)
∇
b
L
(
W
,
b
,
ξ
,
α
,
β
)
=
∑
i
=
1
N
α
i
y
i
=
0
(2.5)
\nabla_{b} L(W, b, \xi, \alpha, \beta) = \sum_{i=1}^N \alpha_i y_i = 0 \tag{2.5}
∇bL(W,b,ξ,α,β)=i=1∑Nαiyi=0(2.5)
∇
ξ
i
L
(
W
,
b
,
ξ
,
α
,
β
)
=
C
−
α
i
−
β
i
=
0
(2.6)
\nabla_{\xi_i} L(W, b, \xi, \alpha, \beta) = C-\alpha_i-\beta_i = 0 \tag{2.6}
∇ξiL(W,b,ξ,α,β)=C−αi−βi=0(2.6)
α
i
≥
0
,
β
i
≥
0
(2.7)
\alpha_i \geq 0, \beta_i \geq 0 \tag{2.7}
αi≥0,βi≥0(2.7)
整理得到:
W
=
∑
i
=
1
N
α
i
y
i
x
i
∑
i
=
1
N
α
i
y
i
=
0
C
=
α
i
+
β
i
(2.8)
W = \sum_{i=1}^N\alpha_i y_i x_i \\ \sum_{i=1}^N \alpha_i y_i = 0 \\ C = \alpha_i+\beta_i \tag{2.8}
W=i=1∑Nαiyixii=1∑Nαiyi=0C=αi+βi(2.8)
将
(
2.8
)
(2.8)
(2.8)代入
(
2.1
)
(2.1)
(2.1),有:
L
(
W
,
b
,
ξ
,
α
,
β
)
=
1
2
∑
i
=
1
N
α
i
y
i
x
i
∑
j
=
1
N
α
j
y
j
x
j
+
(
α
i
+
β
i
)
∑
i
=
1
N
ξ
i
+
∑
i
=
1
N
α
i
−
∑
i
=
1
N
α
i
ξ
i
−
∑
i
=
1
N
β
i
ξ
i
−
∑
i
=
1
N
α
i
y
i
(
∑
j
=
1
N
α
j
y
j
x
j
⋅
x
i
+
b
)
=
−
1
2
∑
i
=
1
N
∑
j
=
1
N
α
i
α
j
y
i
y
j
(
x
i
⋅
x
j
)
+
∑
i
=
1
N
α
i
(2.9)
L(W, b, \xi, \alpha, \beta) = \frac{1}{2} \sum_{i=1}^N\alpha_i y_i x_i \sum_{j=1}^N\alpha_j y_j x_j+(\alpha_i+\beta_i)\sum_{i=1}^N \xi_i+\sum_{i=1}^N \alpha_i - \sum_{i=1}^N \alpha_i \xi_i - \sum_{i=1}^N \beta_i \xi_i - \sum_{i=1}^N \alpha_iy_i(\sum_{j=1}^N\alpha_j y_j x_j \cdot x_i +b) \\ = -\frac{1}{2} \sum_{i=1}^N\sum_{j=1}^N \alpha_i \alpha_j y_i y_j (x_i \cdot x_j)+\sum_{i=1}^N \alpha_i \tag{2.9}
L(W,b,ξ,α,β)=21i=1∑Nαiyixij=1∑Nαjyjxj+(αi+βi)i=1∑Nξi+i=1∑Nαi−i=1∑Nαiξi−i=1∑Nβiξi−i=1∑Nαiyi(j=1∑Nαjyjxj⋅xi+b)=−21i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)+i=1∑Nαi(2.9)
所以问题变为:
max
α
,
β
θ
D
(
α
,
β
)
=
max
α
−
1
2
∑
i
=
1
N
∑
j
=
1
N
α
i
α
j
y
i
y
j
(
x
i
⋅
x
j
)
+
∑
i
=
1
N
α
i
(2.10)
\max_{\alpha, \beta} \theta_D(\alpha, \beta) = \max_{\alpha} -\frac{1}{2} \sum_{i=1}^N\sum_{j=1}^N \alpha_i \alpha_j y_i y_j (x_i \cdot x_j)+\sum_{i=1}^N \alpha_i \tag{2.10}
α,βmaxθD(α,β)=αmax−21i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)+i=1∑Nαi(2.10)
表述为最小化问题:
min
α
1
2
∑
i
=
1
N
∑
j
=
1
N
α
i
α
j
y
i
y
j
(
x
i
⋅
x
j
)
−
∑
i
=
1
N
α
i
s
.
t
.
∑
i
=
1
N
α
i
y
i
=
0
α
i
≥
0
β
i
≥
0
C
=
α
i
+
β
i
(2.11)
\min_{\alpha} \frac{1}{2} \sum_{i=1}^N\sum_{j=1}^N \alpha_i \alpha_j y_i y_j (x_i \cdot x_j)-\sum_{i=1}^N \alpha_i \\ s.t. \sum_{i=1}^N \alpha_i y_i = 0 \\ \alpha_i \geq 0 \\ \beta_i \geq 0 \\ C = \alpha_i+\beta_i \tag{2.11}
αmin21i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)−i=1∑Nαis.t. i=1∑Nαiyi=0αi≥0βi≥0C=αi+βi(2.11)
通过将
β
i
=
C
−
α
i
\beta_i = C-\alpha_i
βi=C−αi,
(
2.11
)
(2.11)
(2.11)可以化为:
min
α
1
2
∑
i
=
1
N
∑
j
=
1
N
α
i
α
j
y
i
y
j
(
x
i
⋅
x
j
)
−
∑
i
=
1
N
α
i
s
.
t
.
∑
i
=
1
N
α
i
y
i
=
0
0
≤
α
i
≤
C
(2.12)
\min_{\alpha} \frac{1}{2} \sum_{i=1}^N\sum_{j=1}^N \alpha_i \alpha_j y_i y_j (x_i \cdot x_j)-\sum_{i=1}^N \alpha_i \\ s.t. \sum_{i=1}^N \alpha_i y_i = 0 \\ 0 \leq \alpha_i \leq C \tag{2.12}
αmin21i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)−i=1∑Nαis.t. i=1∑Nαiyi=00≤αi≤C(2.12)
对比文章《SVM的拉格朗日函数表示以及其对偶问题》中的硬间隔SVM的最终的表达式:
min
α
1
2
∑
i
=
1
N
∑
j
=
1
N
α
i
α
j
y
i
y
j
(
x
i
⋅
x
j
)
−
∑
i
=
1
N
α
i
\min_{\alpha} \frac{1}{2}\sum_{i=1}^N \sum_{j=1}^N \alpha_i \alpha_jy_iy_j(x_i \cdot x_j)- \sum_{i=1}^N\alpha_i
αmin21i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)−i=1∑Nαi
s
.
t
.
∑
i
=
1
N
α
i
y
i
=
0
s.t. \ \sum_{i=1}^N\alpha_iy_i=0
s.t. i=1∑Nαiyi=0
α
i
≥
0
,
i
=
1
,
⋯
,
N
(2.13)
\alpha_i \geq0,i=1,\cdots,N \tag{2.13}
αi≥0,i=1,⋯,N(2.13)
不难发现软间隔SVM只是在对拉格朗日乘子
α
i
\alpha_i
αi的约束上加上了一个上界
C
C
C。
我们以后都会利用
(
2.12
)
(2.12)
(2.12)求解,接下来我们在SMO算法中,也将对式子
(
2.12
)
(2.12)
(2.12)进行求解。
















 3390
3390











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











