







Python中如何将多个dataframe表连接、合并成一个dataframe详解示例(如何将两个表合并行、合并列)--pandas中merge、join、concat、append的区别、用法梳理
我们在对Pandas中的DataFrame对象进行,表的连接、合并的时候,好像merge可以join也可以,哪到底他们有什么区别呢?我们使用的时候,该怎么选择哪个函数进行操作呢?本文就对merge、join、concat、append的使用方法进行梳理。文章的结构是,先说明各个函数的主要作用,最后用详细的代码,举例子演示,从而清晰的明白各个函数的功能定位。最后将各个函数的所有参数进行罗列,起到一个参考的作用。
操作的分类:包含pandas对象的数据可以通过多种方式是连接在一起,主要分为两类:
1)第一类:将两个pandas表根据一个或者多个键(列)值进行连接。这种操作类似关系数据库中sql语句的连接操作。这一类操作在使用pandas的merge、join操作来实现。
2)第二类:将两个pandas表在轴向上(水平、或者垂直方向上)进行粘合或者堆叠。这一类操作在使用pandas的concat、append操作来实现。
一、merge操作
merge函数实现sql数据库类似的各种join(连接)操作,例如内连接、外连接、左右连接等。
举例,创建两个dataframe变量df1,df2:
df1 = pd.DataFrame({'key': ['a', 'b', 'c', 'a', 'b'],
'data1': range(5)})
df2 = pd.DataFrame({'key': ['a', 'b', 'd'],
'data2': range(3)})
df3 = pd.merge(df1,df2)进行merge操作:df3 = pd.merge(df1, df2)。结果如下:
df1为: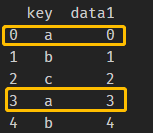 ,df2为:
,df2为: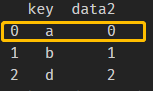 ,输出结果
,输出结果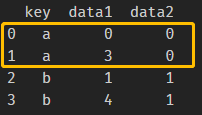
注意的是:
1)如果我们没有指定df1和df2使用哪个列进行连接。当这个时候发生的时候,merge会用两个对象中都存在的列名作为连接列。当然,最好还是清楚指定比较好,上述连接语句等效为:df3 = pd.merge(df1, df2, on='key')。这也是进行merge操作最常用的使用方式。
2)连接的方式。可以仔细看一下df3的输出结果,在结果中并没有c和d。因为merge默认是inner join(内连接)。也就是这个语句等效为:df3 = pd.merge(df1,df2,on='key',how='inner')。‘inner'连接方式,表示结果中的key是交集的结果,也就是两个表格中都有的集合。这里还有其他一些可选项,比如left, right, outer。outer join(外连接)取key的合集,其实就是left join和right join同时应用的效果。先分别看一下left、right、outer具体的输出:
left连接方式:df3 = pd.merge(df1,df2,on='key',how='left')的输出,如下:
df1为:,df2为:,left模式输出: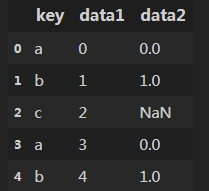 。
。
总结:left 连接模式的时候,所有在df1的key中的值,都能在结果中找到。只在df2的key中,没有在df1的key中的值,不会再结果中出现。
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------
right连接方式:df3 = pd.merge(df1,df2,on='key',how='right')的输出,如下:
df1为:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4760
4760

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









