






本笔记为阿里云天池龙珠计划深度学习训练营的学习内容,链接为:
https://tianchi.aliyun.com/specials/promotion/aicampdl
目录
本任务将在 MNIST 数据集上完成一个 DCGAN 的项目。
下方动画展示了当训练了 50 个epoch (全部数据集迭代50次) 时生成器所生成的一系列图片。图片从随机噪声开始,随着时间的推移越来越像手写数字。

接下来我们进⾏实践,选择 PyTorch 框架,下⾯详解具体的⼯程代码,主要包括:
- 运行环境与数据集准备
- 创建模型
- 定义损失函数与优化器
- 训练模型
- 可视化
运行环境与数据集准备
- 在加载该 NoteBook 文件时,会自动加载数据集至
./download/DCGAN_PyTorch_MNIST_DATASET文件夹下。若没有自动加载数据集,则需要手动加载,手动加载方式如下:
点击本页面左方 天池 按钮(需要在 CPU 环境下),点击 DCGAN_PyTorch_MNIST_DATASET 旁边的下载按钮,就会自动加载数据集了!

运行下面代码,对数据集进行解压
# 这个命令在GPU下无法执行,没有关系,后面加载数据时会从网络下载
!unzip DCGAN_PyTorch_MNIST_DATASET.zip -d ./DCGAN_PyTorch_MNIST_DATASET
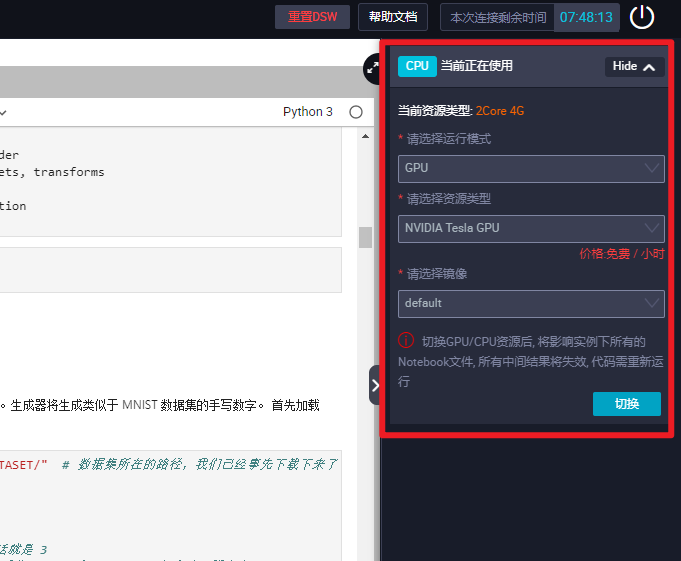
- 同时该实战需要在 GPU 环境下才能运行,GPU 环境的切换方法如下:
点击本页面右侧 < 键,会调出以下页面,然后点击切换即可切换至 GPU,切换时间会稍微长一点,请耐心等候!
import time # 导入time模块,记录系统时间import torch # 导入torch库import torch.nn as nn # 导入nn模块,构建神经网络from torch.utils.data import DataLoader # 通过DataLoader对数据集进行分批加载# datasets下载和管理公开数据集,transforms对数据集进行预处理和格式转换 from torchvision import utils, datasets, transformsimport matplotlib.pyplot as plt # 画图库import matplotlib.animation as animation # 绘制动态图from IPython.display import HTML # 在HTML中展示动画
1. 加载和准备数据集
本项目使用 MNIST 数据集来训练生成器和判别器。生成器将生成类似于 MNIST 数据集的手写数字。 首先加载数据集,并设置初始参数。
在加载该 NoteBook 文件时,会自动加载数据集至 DCGAN_PyTorch_MNIST_DATASET 文件夹下
dataroot = "./DCGAN_PyTorch_MNIST_DATASET/" # 数据集所在的路径workers = 10 # 数据加载时的进程数batch_size = 100 # 生成器输入的大小,既批量数据集大小image_size = 64 # 训练图像的大小nc = 1 # 训练图像的通道数(灰色图),彩色图像的话就是 3nz = 100 # 输入是100 维的随机噪声z,看作是100个channel,每个特征图宽高是 1*1ngf = 64 # 生成器中特征图的大小ndf = 64 # 判别器中特征图的大小num_epochs = 10 # 训练的轮次lr = 0.0002 # 学习率大小beta1 = 0.5 # Adam优化器的参数ngpu = 1 # 可用 GPU 的个数,0 代表使用 CPU# 训练集加载并进行归一化等操作train_data = datasets.MNIST(root=dataroot,train=True,transform=transforms.Compose([transforms.Resize(image_size), # 将图像调整为64*64transforms.ToTensor(), # 将图像数据格式化为张量,形状为C*W*Htransforms.Normalize((0.5, ), (0.5, )) # 按通道归一化数据,mean=0.5,std=0.5]),download=True # 从互联网下载,如果已经下载的话,就直接使用)# 测试集加载并进行归一化等操作test_data = datasets.MNIST(root=dataroot,train=False,transform=transforms.Compose([transforms.Resize(image_size),transforms.ToTensor(),transforms.Normalize((0.5, ), (0.5, ))]))# 把 MNIST 的训练集和测试集都用来做训练# train_data和test_data为MNIST数据集,dataset为ConcatDataset类型,既不是Iterator,也不可Iterable dataset = train_data + test_dataprint(f'Total Size of Dataset: {len(dataset)}')# 数据加载器,训练过程中不断产生数据dataloader = DataLoader(dataset=dataset,batch_size=batch_size,shuffle=True,num_workers=workers)# 看是否存在可用的 GPUdevice = torch.device('cuda:0' if (torch.cuda.is_available() and ngpu > 0) else 'cpu')# 权重初始化函数def weights_init(m):classname = m.__class__.__name__if classname.find('Conv') != -1:nn.init.normal_(m.weight.data, 0.0, 0.02) # 使用正态化分布随机数据初始化卷积层权重elif classname.find('BatchNorm') != -1:nn.init.normal_(m.weight.data, 1.0, 0.02)nn.init.constant_(m.bias.data, 0) # 使用0值初始化偏置Total Size of Dataset: 70000
以下的代码用做读取部分数据集进行展示,看看我们原始输入的数据是怎么样的。
inputs = next(iter(dataloader))[0] # 使用iter方法把dataloader转变为Iterator,并使用next()读入100个图像plt.figure(figsize=(10, 10)) # 定义画布大小为10*10英寸plt.title("Training Images") # 定义标题plt.axis('off') # 去掉坐标轴# inputs里的数据取值范围从[-1,1]调整为[0,1],并合成一个网格图像,每行显示10个图像
inputs = utils.make_grid(inputs[:100] * 0.5 + 0.5, nrow=10)plt.imshow(inputs.permute(1, 2, 0)) # 将inputs转换维度后画图
[3]:
<matplotlib.image.AxesImage at 0x7f9ed8c73e10>

创建模型
1. 生成器
生成器使用 torch.nn.ConvTranspose2d (上采样)层来从种子(随机噪声)中产生图片。以一个使用该种子作为输入的 Dense 层开始,然后多次上采样直到达到所期望的 64x64x1 的图片尺寸。注意除了输出层使用 tanh 之外,其他每层均使用 torch.nn.functional.relu 作为激活函数。
下面定义一个生成器的类,读者可以依照生成器网络配置理解以下代码
class Generator(nn.Module):def __init__(self, ngpu):super(Generator, self).__init__()self.ngpu = ngpu# 创建一个Sequential容器,存放各网络层
self.main = nn.Sequential(# input is Z, going into a convolutionnn.ConvTranspose2d(in_channels=nz, # 输入特征数64out_channels=ngf * 8, # 输出特征数64*8kernel_size=4, # 卷积核尺寸4*4stride=1, # 步幅1padding=0, # 不填充bias=False), # 不添加偏置nn.BatchNorm2d(ngf * 8), # 批量归一化nn.ReLU(True), # ReLU激活# 当前特征图大小 (ngf*8) x 4 x 4,转置卷积过程中产生的临时图片尺寸为:1*1,卷积核为:size:3*3,stride:1,padding:4-0-1=3nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),nn.BatchNorm2d(ngf * 4),nn.ReLU(True),# 当前特征图大小 (ngf*4) x 8 x 8nn.ConvTranspose2d(ngf * 4, ngf * 2, 4, 2, 1, bias=False),nn.BatchNorm2d(ngf * 2),nn.ReLU(True),# 当前特征图大小 (ngf*2) x 16 x 16nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 1, bias=False),nn.BatchNorm2d(ngf),nn.ReLU(True),# 当前特征图大小 (ngf) x 32 x 32nn.ConvTranspose2d(ngf, nc, 4, 2, 1, bias=False),nn.Tanh() # 输出层使用Tanh激活,将值范围从[0,1]调整为[-1,1]# 当前特征图大小 (nc) x 64 x 64,与MNIST数据集中图像的尺寸一致,取值范围也一致)def forward(self, input):return self.main(input)
2. 判别器
判别器是一个基于 CNN 的图片分类器。
class Discriminator(nn.Module):def __init__(self, ngpu):super(Discriminator, self).__init__() # 继承父类的__init__方法self.ngpu = ngpuself.main = nn.Sequential(# 输入 (nc) x 64 x 64nn.Conv2d(nc, ndf, 4, 2, 1, bias=False),nn.LeakyReLU(0.2, inplace=True), # 此处的激活函数与生成器中不同,是带有负斜率的修正线性单元# 当前特征图大小 (ndf) x 32 x 32nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),nn.BatchNorm2d(ndf * 2),nn.LeakyReLU(0.2, inplace=True),# 当前特征图大小 (ndf*2) x 16 x 16nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),nn.BatchNorm2d(ndf * 4),nn.LeakyReLU(0.2, inplace=True),# 当前特征图大小 (ndf*4) x 8 x 8nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),nn.BatchNorm2d(ndf * 8),nn.LeakyReLU(0.2, inplace=True),# 当前特征图大小 (ndf*8) x 4 x 4nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),# 当前特征图大小 (1) x 1 x 1nn.Sigmoid()) # 输出层使用Sigmoid激活def forward(self, input):return self.main(input)
3. 生成器与判别器初始化
# 创建一个生成器对象,并拷贝至GPUnetG = Generator(ngpu).to(device)# 多卡并行,如果有多卡的话if device.type == 'cuda' and ngpu > 1:netG = nn.DataParallel(netG, list(range(ngpu)))# 初始化权重 其中,mean=0, stdev=0.2. apply的作用是在netG各个网络层上运用初始化,转置卷积层使用正态分布的随机数初始化权重,无偏置;归一化层使用正态分布的随机数初始化权重,使用0初始化偏置netG.apply(weights_init)# 创建一个判别器对象netD = Discriminator(ngpu).to(device)# 多卡并行,如果有多卡的话if device.type == 'cuda' and ngpu > 1:netD = nn.DataParallel(netD, list(range(ngpu)))# 初始化权重 其中,mean=0, stdev=0.2.netD.apply(weights_init)[6]:
Discriminator( , (main): Sequential( , (0): Conv2d(1, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False) , (1): LeakyReLU(negative_slope=0.2, inplace=True) , (2): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False) , (3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) , (4): LeakyReLU(negative_slope=0.2, inplace=True) , (5): Conv2d(128, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False) , (6): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) , (7): LeakyReLU(negative_slope=0.2, inplace=True) , (8): Conv2d(256, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False) , (9): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) , (10): LeakyReLU(negative_slope=0.2, inplace=True) , (11): Conv2d(512, 1, kernel_size=(4, 4), stride=(1, 1), bias=False) , (12): Sigmoid() , ) ,)
定义损失函数和优化器
为两个模型定义损失函数和优化器。
criterion = nn.BCELoss() # 定义损失函数,适用于二分类问题# 创建一批潜在向量,我们将使用它们来可视化生成器的生成过程fixed_noise = torch.randn(100, nz, 1, 1, device=device)real_label = 1. # “真”标签fake_label = 0. # “假”标签# 为生成器和判别器定义优化器optimizerG = torch.optim.Adam(netG.parameters(), lr=lr, betas=(beta1, 0.999))optimizerD = torch.optim.Adam(netD.parameters(), lr=lr, betas=(beta1, 0.999))
训练阶段
DCGAN 的训练过程如下:
1、首先固定 Generator,训练 Discriminator
- 输入:真实数据 x,Generator 生成的数据 G(x)
- 输出:二分类概率
从噪声分布中随机采样噪声 z,经过 Generator 生成 G(z)。G(z)和 x 输入到 Discriminator 得到 D(x) 和 D(G(z)),损失函数为

这里是最大化损失函数,因此使用梯度上升法更新参数。(目的是Discriminator可以区分真实数据和假数据)
2、固定 Discriminator,训练 Generator。
- 输入:随机噪声 z
- 输出:分类概率 D(G(z)),目的是使 D(G(z))=1(既判定假数据为真)
从噪声分布中重新随机采样噪声 z,经过 Generator 生成 G(z)。G(z)输入到 Discriminator 得到 D(G(z)),损失函数为

这里是最小化损失函数,使用梯度下降法更新参数。(目的是Generator假数据接近真实数据)
# 定义一些变量,用来存储每轮的相关值img_list = []G_losses = []D_losses = []D_x_list = []D_z_list = []loss_tep = 10print("Starting Training Loop...")# 迭代for epoch in range(num_epochs):beg_time = time.time() # 每一轮开始时间# 数据加载器读取数据for i, data in enumerate(dataloader):############################# (1) Update D network: maximize log(D(x)) + log(1 - D(G(z)))############################ 用所有的真数据进行训练netD.zero_grad() # 每个批量训练开始之前,将D网络的所有参数梯度清0# Format batchreal_cpu = data[0].to(device) # data[0]为训练数据,data[1]为数据标签b_size = real_cpu.size(0)label = torch.full((b_size, ),real_label, # 标识所有训练数据的标签均为真dtype=torch.float,device=device)# 判别器推理,只输入真实数据output = netD(real_cpu).view(-1)# Calculate loss on all-real batch# 计算所有真标签的损失函数errD_real = criterion(output, label)# Calculate gradients for D in backward passerrD_real.backward() # 计算判别器网络的所有参数梯度# 此处计算梯度后不更新参数,等输入假数据后梯度累加,再更新参数
D_x = output.mean().item() # 判别器批量真数据上输出的均值# 生成假数据并进行训练noise = torch.randn(b_size, nz, 1, 1, device=device) # (100, 100, 1, 1)# 用生成器生成假图像fake = netG(noise)label.fill_(fake_label) # 标签值全0# Classify all fake batch with Doutput = netD(fake.detach()).view(-1) # fake.detach()的作用是不对G网络的参数求梯度和更新参数# 计算判别器在假数据上的损失errD_fake = criterion(output, label)errD_fake.backward() # 计算D网络的所有参数梯度D_G_z1 = output.mean().item() # D网络在批量假数据上输出的均值# Add the gradients from the all-real and all-fake batcheserrD = errD_real + errD_fake# Update DoptimizerD.step() # 更新D网络的参数############################# (2) Update G network: maximize log(D(G(z)))###########################netG.zero_grad() # 将G网络所有参数的梯度置0label.fill_(real_label) # fake labels are real for generator cost# Since we just updated D, perform another forward pass of all-fake batch through Doutput = netD(fake).view(-1) # 因为要更新G网络的参数,所以要计算G网络的梯度# Calculate G's loss based on this outputerrG = criterion(output, label)# Calculate gradients for GerrG.backward() # 同时计算G网络和D网络参数的梯度D_G_z2 = output.mean().item()# Update GoptimizerG.step() # 更新G网络的参数# Output training statsend_time = time.time()run_time = round(end_time - beg_time)print(f'Epoch: [{epoch+1:0>{len(str(num_epochs))}}/{num_epochs}]',f'Step: [{i+1:0>{len(str(len(dataloader)))}}/{len(dataloader)}]',f'Loss-D: {errD.item():.4f}',f'Loss-G: {errG.item():.4f}',f'D(x): {D_x:.4f}',f'D(G(z)): [{D_G_z1:.4f}/{D_G_z2:.4f}]',f'Time: {run_time}s',end='\r')# Save Losses for plotting laterG_losses.append(errG.item())D_losses.append(errD.item())# Save D(X) and D(G(z)) for plotting laterD_x_list.append(D_x) # 输入真实数据时D网络的输出D_z_list.append(D_G_z2) # 输入假数据时D网络的输出# 保存最好的模型if errG < loss_tep:torch.save(netG.state_dict(), 'model.pt')temp = errG# Check how the generator is doing by saving G's output on fixed_noisewith torch.no_grad(): # 上下文中生成的张量不需要计算梯度fake = netG(fixed_noise).detach().cpu() # detach确保G网络的参数不被更新img_list.append(utils.make_grid(fake * 0.5 + 0.5, nrow=10)) # fake*0.5+0.5是为了将图像像素值从范围[-1, 1]调整为[0,1]print()Starting Training Loop... Epoch: [01/10] Step: [700/700] Loss-D: 0.4350 Loss-G: 2.9547 D(x): 0.7841 D(G(z)): [0.1346/0.0773] Time: 108s Epoch: [02/10] Step: [700/700] Loss-D: 0.4743 Loss-G: 0.9218 D(x): 0.6646 D(G(z)): [0.0194/0.4482] Time: 112s Epoch: [03/10] Step: [700/700] Loss-D: 0.0687 Loss-G: 3.8681 D(x): 0.9497 D(G(z)): [0.0155/0.0298] Time: 112s Epoch: [04/10] Step: [700/700] Loss-D: 0.3206 Loss-G: 3.1840 D(x): 0.8709 D(G(z)): [0.1496/0.0575] Time: 112s Epoch: [05/10] Step: [700/700] Loss-D: 0.0596 Loss-G: 4.5093 D(x): 0.9767 D(G(z)): [0.0343/0.0166] Time: 110s Epoch: [06/10] Step: [700/700] Loss-D: 0.2968 Loss-G: 2.6771 D(x): 0.9515 D(G(z)): [0.2015/0.0979] Time: 110s Epoch: [07/10] Step: [700/700] Loss-D: 0.5452 Loss-G: 1.7598 D(x): 0.7117 D(G(z)): [0.1462/0.2073] Time: 109s Epoch: [08/10] Step: [700/700] Loss-D: 0.1074 Loss-G: 3.9390 D(x): 0.9226 D(G(z)): [0.0230/0.0279] Time: 112s Epoch: [09/10] Step: [700/700] Loss-D: 1.0417 Loss-G: 4.9647 D(x): 0.9736 D(G(z)): [0.5448/0.0107] Time: 115s Epoch: [10/10] Step: [700/700] Loss-D: 0.0346 Loss-G: 4.9161 D(x): 0.9926 D(G(z)): [0.0263/0.0111] Time: 117s
模型训练完毕后,会保存成一个 model.pt 文件
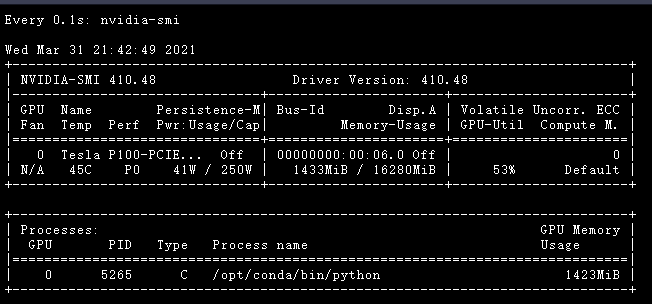
在运行过程中,可以打开终端,查看 GPU 运行情况
然后在终端运行以下命令!
watch -n 0.1 nvidia-smi
可视化
1. 生成器与判别器损失函数曲线
plt.title("Generator and Discriminator Loss During Training")plt.plot(G_losses[::100], label="G")plt.plot(D_losses[::100], label="D")plt.xlabel("iterations")plt.ylabel("Loss")plt.axhline(y=0, label="0", c="g") # asymptote,水平参考线plt.legend()[9]:
<matplotlib.legend.Legend at 0x7f9ed3870438>

2. 训练过程展示
fig = plt.figure(figsize=(10, 10)) # 创建一个画布对象,设置图像尺寸为10*10尺寸plt.axis("off") # 取消坐标轴# 调整存储在img_list中图像维度的顺序为H*W*C,plt才可以正确显示
ims = [[plt.imshow(item.permute(1, 2, 0), animated=True)] for item in img_list]ani = animation.ArtistAnimation(fig,ims,interval=1000,repeat_delay=1000,blit=True)HTML(ani.to_jshtml()) # 将动画对象转换为html格式,并使用html展示[10]:
, , , , , ,, ,, ,
, , , , , , , , , , , , , , , , ,
,
, , Once , , Loop , , Reflect ,
,,, , ,

3. 真(训练集中的)——假(网络生成的)图片对比
# Size of the Figureplt.figure(figsize=(20, 10))# Plot the real imagesplt.subplot(1, 2, 1) # 在第一个子图中展示真实数据图像plt.axis("off")plt.title("Real Images")real = next(iter(dataloader))plt.imshow(utils.make_grid(real[0][:100] * 0.5 + 0.5, nrow=10).permute(1, 2, 0))# Load the Best Generative ModelnetG = Generator(0) # 使用CPUnetG.load_state_dict(torch.load('model.pt', map_location=torch.device('cpu')))netG.eval() # 将G网络设置为评估模型,既不进行梯度计算# Generate the Fake Imageswith torch.no_grad():fake = netG(fixed_noise.cpu())# Plot the fake imagesplt.subplot(1, 2, 2) # 在第二个子图中展示生成数据图像plt.axis("off")plt.title("Fake Images")fake = utils.make_grid(fake * 0.5 + 0.5, nrow=10)plt.imshow(fake.permute(1, 2, 0))# Save the comparation resultplt.savefig('result.jpg', bbox_inches='tight')

-- By:有三AI 团队
聚焦于让大家能够系统性地完成AI各个领域所需的专业知识的学习,实现三人行必有AI,三人行必有我师的愿景。














 1804
1804











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









