







下载hadoop1.2.1.tar.gz
文档:http://hadoop.apache.org/docs/r1.2.1/
Pseudo-Distributed Operation
Hadoop can also be run on a single-node in a pseudo-distributed mode where each Hadoop daemon runs in a separate Java process.
Configuration
Use the following:
conf/core-site.xml:
指定hadoop.tmp.dir默认在/tmp下,重启后会丢失
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop1.2.1</value>
</property>
</configuration>
conf/hdfs-site.xml:
指定副本数为1,因为是伪分布式,只有一个节点(一个namenode,一个datanode,一个secondaryNamenode),默认副本数为3
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
conf/mapred-site.xml:
指定jobtracker位于哪个节点
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>Setup passphraseless ssh
Now check that you can ssh to the localhost without a passphrase:
$ ssh localhostIf you cannot ssh to localhost without a passphrase, execute the following commands:
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
把公钥copy到想要免密码登陆的主机上
Execution
Format a new distributed-filesystem:
启动时格式化namenode节点,否则可能namenode启动不起来,或者找不到namenode
$ bin/hadoop namenode -formatStart the hadoop daemons:
$ bin/start-all.shstart-all启动所有,包括dfs和mr等
The hadoop daemon log output is written to the {HADOOP_LOG_DIR} directory (defaults to${HADOOP_HOME}/logs).
Browse the web interface for the NameNode and the JobTracker; by default they are available at:
NameNode - http://localhost:50070/
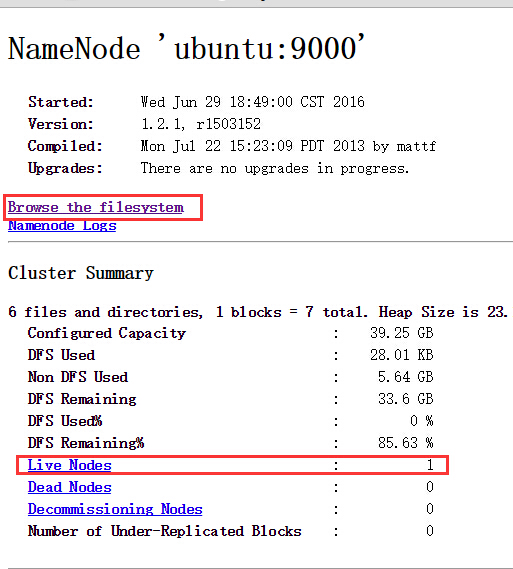
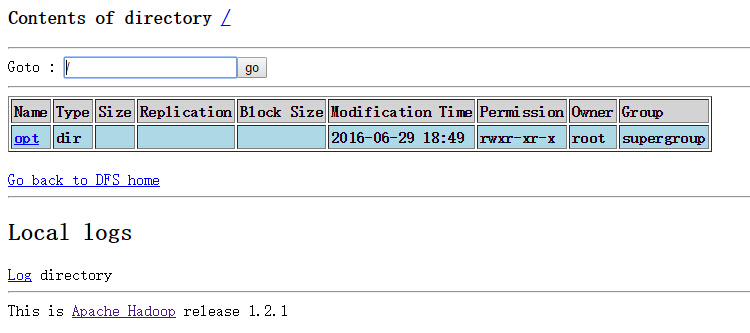
点击browse the filesystem,可以查看dfs文件系统
JobTracker - http://localhost:50030/
Copy the input files into the distributed filesystem:
$ bin/hadoop fs -put conf input
Run some of the examples provided:
$ bin/hadoop jar hadoop-examples-*.jar grep input output ‘dfs[a-z.]+’
Examine the output files:
Copy the output files from the distributed filesystem to the local filesytem and examine them:
bin/hadoopfs−getoutputoutput
cat output/*
or
View the output files on the distributed filesystem:
$ bin/hadoop fs -cat output/*
When you’re done, stop the daemons with:
$ bin/stop-all.sh
slaves配置namenode
masters配置secondaryNameNode
core-site.xml配置的namenode
secondaryNamenode不能与namenode在同一个节点上















 1655
1655











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









