







在mapper和reducer中间的一个步骤
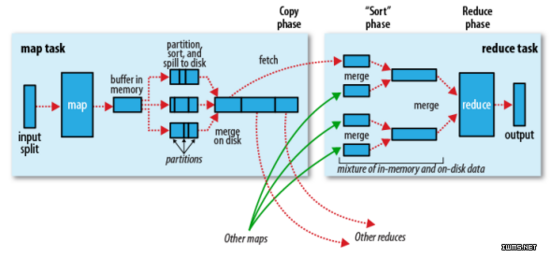
partition,把数据分成一个个区,可以通过程序自定义分区,也可以使用默认的分区,默认规则为哈希模运算,把一个整数模reduce的个数。分区是为了把map的输出数据进行负载均衡,或者解决数据倾斜的问题(节点计算的数据量不均衡,就倾斜)。默认reduce为1,数据量多的时候,reduce为多个。作用是把map的数据分区成一个个reduce区域。
完成partition,sort后,然后merge on disk,合并到磁盘上。默认的合并规则,按照哈希合并,键值相同即可合并,combiner。合并的目的是为了减少map的输出,加快网络之间的copy
reduce和map不在一台机器上,需要copy phase。只copy给需要这台主机reduce的数据。
程序可以控制的地方:分区,排序,combiner。merge不可控
每个map task都有一个内存缓冲区(默认100M),存储着map的输出结果。当缓冲区快满的时候需要将缓冲区的数据以一个临时文件的方式存放到磁盘。溢写是由单独线程来完成,不影响往缓冲区写map结果的线程(spill.percent,默认为0.8)。当溢写线程启动后,需要对这80MB空间内的数据进行排序。
假如client设置过combiner,会将有相同key的key/value的value加起来,减少溢写到磁盘的数据量
当整个map task结束后,再对磁盘中这个map task产生的所有临时文件做合并(merge),对于“”word1“”就像是这样的{“”word1“”,【5,8,2】},假如有combiner,{word1【15】}最终会产生一个文件。
reduce从tasktracker copy数据。
copy过来的数据会先放入内存缓冲区,这里的缓冲区要比map端的更为灵活,基于jvm的heap size设置
merge有三种形式,内存到内存,内存到磁盘,磁盘到磁盘。merge从不同的tasktracker上拿到数据。















 1065
1065

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









