







机器人领域VLA模型科普
2025年刚进入3月,机器人领域好不热闹,除了人形机器人跳舞、翻跟头、鲤鱼打挺等各种酷炫的Demo,具身智能公司也动作频频,Pi发布HI Robot,Figure发布Helix,Google发布Gemini Robotics,智元发布GO-1,英伟达GTC发布Groot N1。随之而来的是各种搞不清楚的概念。这些所谓的"VLA"模型到底是什么?各种VLA模型之间的区别是什么?VLA和模仿学习有什么关系?真机数据的重要性体现在哪里?
在Robot Foundation Model断更几个月后(RFM EP01:Pi和π0具身基础模型,RFM EP02:Octo,RFM EP03:清华RDT及具身大模型框架对比),终于在公众号后台粉丝的催更下,隆重推出机器人基座模型第四期。
我整理了目前几个主要VLA模型的模型结构,以及对一些概念的理解。这篇文章的成文,在我自己对几个VLA模型结构的梳理基础上,在模型结构理解和概念确认方面采访了智元启元大模型(Genie Operator-1,简称GO-1)的共一刘迟明。希望这篇文章可以成为中文互联网上最容易理解的VLA科普文章。
刘迟明目前就职于智元机器人负责基座大模型架构和研发,是AgiBot World Colosseo文章共一,主导研发GO-1基座模型。他曾就职于阿里巴巴和腾讯担任技术专家岗位,负责大规模互联网系统机器学习和深度学习技术研发;曾开发和训练千亿参数LLM,相关工作发表于顶会和头部期刊;参与过很多开源社区项目建设,贡献代码给如huggingface/transformers等头部项目。
1. 什么是VLA
VLA 是一种整合视觉(Vision)、语言(Language)和动作(Action)的多模态模型,用于推动机器人更自然地理解和执行任务。它的目标是让机器人像人一样,通过"看图 + 听指令"来"做事情"。
在传统控制系统中,视觉、语言和动作模块往往是独立处理的,而 VLA 模型尝试构建一个统一的架构,让模型从感知(图像)、理解(语言)到执行(动作)之间具备连贯性和一致性。VLA 模型通常包括以下几个部分:
-
第一部分:视觉编码器(Vision Encoder):输入图像、视频等视觉信号,将其编码为特征向量。通常使用 ViT(Vision Transformer)、ResNet 或更高级的图像模型。
-
第二部分:语言编码器(Language Encoder):输入自然语言指令,将其转换为语言嵌入(text embedding)。使用如 BERT、T5、GPT、CLIP Text Encoder 等。
-
第三部分:多模态融合模块(Cross-modal Fusion):将图像和文本信息进行对齐,学习视觉和语言之间的关系。可以是 cross-attention 机制、多模态 transformer 或 CLIP-style 对比学习。
-
第四部分:动作生成器(Action Decoder / Policy Head):根据融合后的视觉和语言特征,生成动作指令(可以是连续控制向量,也可以是离散 token)。动作可能通过 Diffusion、Flow Matching、RL policy head 等生成。
如果对应到核心能力来源,第一到第三部分核心能力都来自于以OpenAI和Google为代表的大模型公司的视觉语言模型(VLM),第四部分的核心能力来自于以Pi0为代表的具身智能公司。
根据具象的解释,可以把 VLA 模型想象成一个训练有素的机器人助理:它"看到"一张图,比如一张厨房桌子,桌上有盘子、叉子、鸡蛋。你对它说:"把鸡蛋翻个面。“它"理解"你的语言,与它看到的图像一起思考:鸡蛋在哪里?手该怎么动?用什么工具?然后它"动起来”,做出一系列精确的动作,比如拿起锅铲、翻转鸡蛋。这个过程中,它就是把视觉感知、语言理解和动作控制三个过程无缝结合起来了。
2. Pi0 VLA模型结构
在RFM(Robot Foundation Model)系列,我们根据Sergey的几个Talk整理了一篇关于Pi0的科普(RFM EP01:Pi和π0具身基础模型)。根据PI的官方披露信息,PI的通用机器人策略采用了一个预训练的视觉-语言模型(VLM)作为基础骨干,并使用了一个跨形态、多样化的操控任务数据集。为了适配机器人控制,我们在模型中加入了一个独立的动作专家模块,通过流匹配(flow matching)生成连续动作,从而实现精确且流畅的操控能力。该模型既可以通过提示实现零样本控制(zero-shot control),也可以在高质量数据上进行微调,从而完成复杂的多阶段任务,例如折叠多件衣物或组装一个盒子。
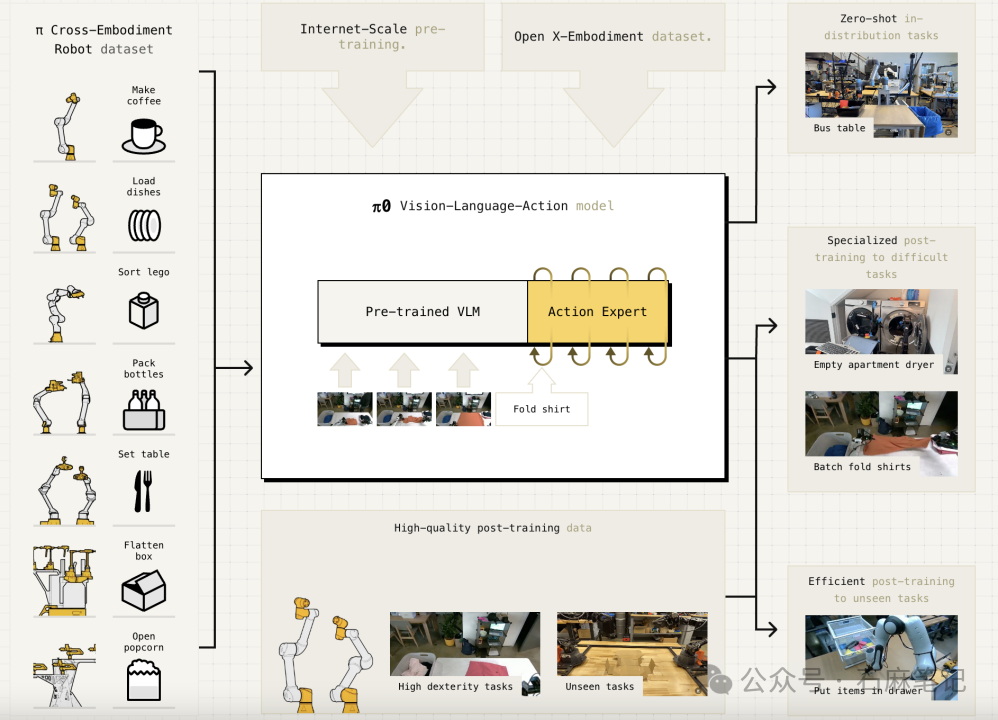
这段文字,在理解了模型框架的基础上看其实非常精准,但在不理解的基础上,一些概念就不会很清晰。结合我自己的理解以及被访者的交流,我将Pi0模型结构的理解进行来拆分。
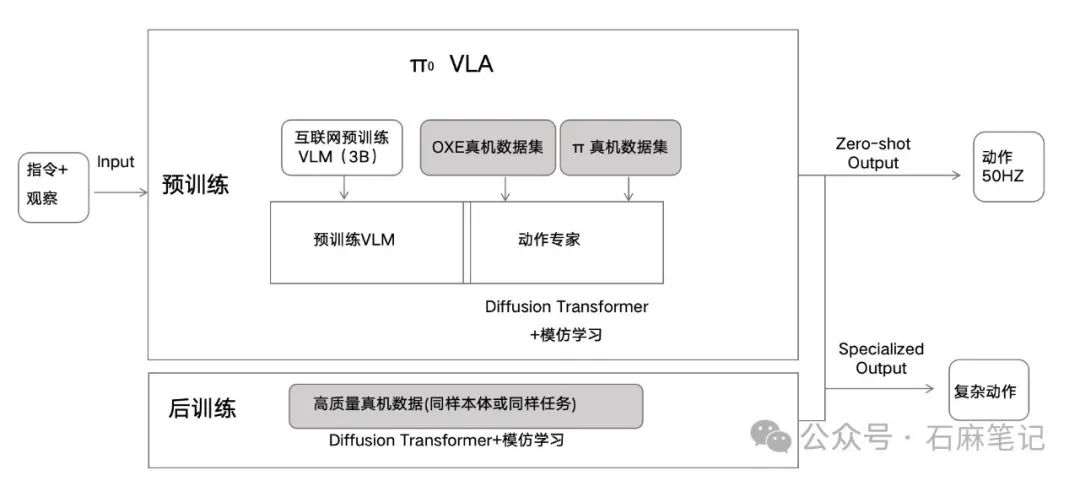
整个Pi0的模型架构用我自己的话来理解:Pi0是一个机器人收到人类指令和结合观察直接输出动作的端到端VLA模型,这个模型训练分两个阶段,第一阶段预训练,在基于大模型公司开发的VLM对文本和语言对有理解的基础上,通过模仿学习的框架用真实机器人数据作为监督信号训练出机器人动作生成策略;在后训练阶段,针对特定任务,用模仿学习框架进一步训练提高特定任务的成功率。
VLA及其输入和输出
结合Pi0的公开资料以及访谈,我们将Pi0 VLA的模型结构做了进一步理解,如上图。整个模型的输入是机器人接收到的图像观察(Vision)和语言(Language)指令,即模型最左侧的Input部分;整个模型的输出是机器人动作(Action),即模型最右侧的Output部分。简单理解VLA就是,一个机器人在收到指令的情况下(Language),结合对周围环境的视觉输入(Vision),去完成指令要求的任务对应的动作输出(Action),整个过程在一个大的神经网络里闭环完成,也就是所谓的"端到端"。
Pi0 VLA模型结构
模型的训练分两个阶段,第一大阶段是预训练,第二阶段是后训练;两个阶段的区别在于训练规模和对输出质量的要求不同。预训练模型的入参与 VLM 类似,都包括图像和文本数据,但同时还额外加入了机器人本体的关节角度数据作为输入信息。
预训练阶段
预训练阶段有两个主要部分构成,依靠三类数据来源。预训练的第一个组成部分是一个依靠互联网规模的数据预训练的VLM,这个VLM通常是个由大模型公司训练好的开源模型或API。在Pi0的工作中他们选择了Google的PaliGemma 3B模型权重,这个部分和PI的团队没什么关系,他们仅仅是选择了一个适合他们的由别的公司开发的VLM。
预训练的第二个组成部分是一个由两组真实机器人数据集(开源真机数据集OXE和PI自己收集的高质量遥操真机数据)训练的Action Expert(动作专家),这个Action Expert通过模仿学习的框架对比与真机数据损失函数最小来获得最优解,用到了类似Diffusion Model这样的结构(Flow Matching)将Token denoise成连续的动作输出。
预训练VLM
Pi0模型预训练阶段的 pretrained VLM,实际上就是指谷歌的PaliGemma那套开源模型,即之前Google的VLM团队利用互联网规模(Internet-scale)的图文数据所训练出来的一组3B规模的模型权重。这里需要说明一下,现在"pretrain"这个词在不同业务领域里可能各有不同的具体含义,即便我们说的是一个VLM(视觉语言模型)领域的pretrain,它的含义也可能有所不同。
比如刚提到的PaliGemma,其实是基于 Gemma 模型构建的。Gemma 本身是Google推出的一个语言模型,而PaliGemma则是在这个语言模型基础上,额外加入了视觉编码器(Vision Encoder),通过进一步训练后,形成了一个视觉语言模型(VLM)。这样就实现了文本与视觉之间的对齐(text-vision alignment)。
实际上,Physical Intelligence(PI)团队并没有从头开始用互联网规模的图文数据训练VLM模型,而是直接使用了Google团队的开源 VLM PaliGemma的预训练权重。在这个基础之上,他们进一步利用约10万小时的机器人数据集,对模型进行了训练,最终得到了他们自己的Pi0模型。
动作专家(Action Expert)
Action expert 本质上是一种 flow matching,可以简单理解成一种diffusion model,但其损失函数与其他 diffusion model 不同。它从 VLM 获取的是每一层 Transformer 输出的 hidden state,即每个 token 的隐藏向量(hidden vectors)。LLM和VLM都是基于 Transformer 架构的,它们以 token 为基本载体,将图像和文本统一切分成一系列 tokens。这些 tokens 在网络中每一层 Transformer 前向传播时都会产生相应的隐藏状态(hidden states),即 tokens 对应的特征向量(vectors)。每层 Transformer 产生的这些特征向量会被传递给 action expert,后者再通过类似diffusion model的方法对这些信息进行去噪(denoise),从而生成相应的控制指令。
Zero-shot能力
预训练阶段的VLA具备一定的零样本(Zero-Shot)输出能力,图中所描述的情况一般适用于训练中已经见过的任务(即 in-distribution tasks),但实际上,基于 VLM 训练出来的策略通常具备一定的泛化能力,可以推广到训练过程中未见过的物体,体现出一定的 zero-shot 能力。
后训练阶段
Pi0的VLA大模型第二个训练阶段是后训练,后训练阶段仅仅依靠PI自己收集的高质量真机数据集,通过模仿学习框架,进一步提高模型在特定任务上的成功率。后训练过程类似于将一个通用模型(generalist)进一步训练为成功率更高的专用模型(specialist),即实现从通用到专用(from generalist to specialist)的转变。
这里面提到的真机数据其实是一类机器人数据的获取方式,通常是由人类"遥控"操作机器人所获得的机器人数据。遥控方式有多种,包括同构遥操例如Mobile Aloha,头显遥操例如Open Television等。
怎么理解VLA是个端到端模仿学习的框架?
整体来说,这套称为 VLA 的方法其实就是一种端到端的模仿学习。这里的模仿学习具体体现在,它的监督信号来源于人遥操机器人产生的动作数据。具体来说,模型中的 action expert 会通过去噪(denoise)输出动作信号,而这些动作信号需要计算损失才能进行梯度回传优化。计算损失时,模型输出的动作信号与真实动作进行比较,而真实动作就是人遥操机器人过程中机器人的动作数据,这就构成了模仿学习的监督信号。
端到端模仿学习仅在action expert部分吗?
他整个模型在训练时用到的仅仅是模仿学习的损失,没有采用其他类型的损失函数。比如,训练 VLM 时通常会计算 token 与 token 之间的交叉熵(cross entropy,action expert部分提到)损失,但在这个模型中并没有使用这种 token-level 的损失,而只用到了模仿学习中的动作监督信号作为唯一的损失进行训练。
怎么理解Diffusion Transformer?
这里使用的模型架构其实不应该称作 DIT(DiT),因为 DiT 一般特指的是 Meta 提出的那个特定的 Transformer 架构,这里的模型虽然也是基于 Transformer 架构的 diffusion 模型,但与 DiT 并不相同。可以称它为 diffusion transformer 会更合适一些,但最好不要直接使用 DiT 这个名称,以免造成混淆。
后训练和预训练的区别
Pi0后训练和预训练中的Action Expert部分,都是采用同一个 diffusion transformer架构,二者唯一的差别在于训练时所使用的数据不同。后训练使用更高质量和更有针对性的机器人真机数据来提高任务成功率,比如使用同样的机器人本体,或者在复杂任务上进行有针对性的训练。
3. Figure-Helix VLA模型
根据Figure披露的官方信息,Helix 是首个结合 “System 1 / System 2” 架构的 VLA(视觉-语言-动作)模型,专为高频率、灵巧控制整个人形机器人上半身而设计。
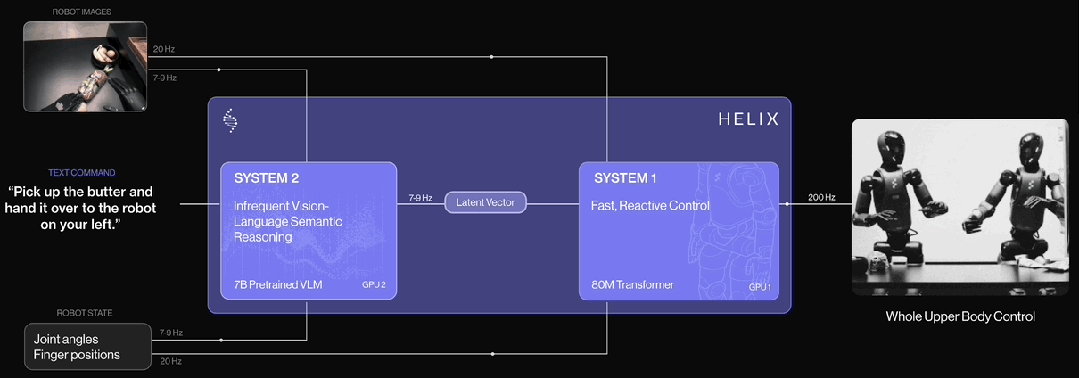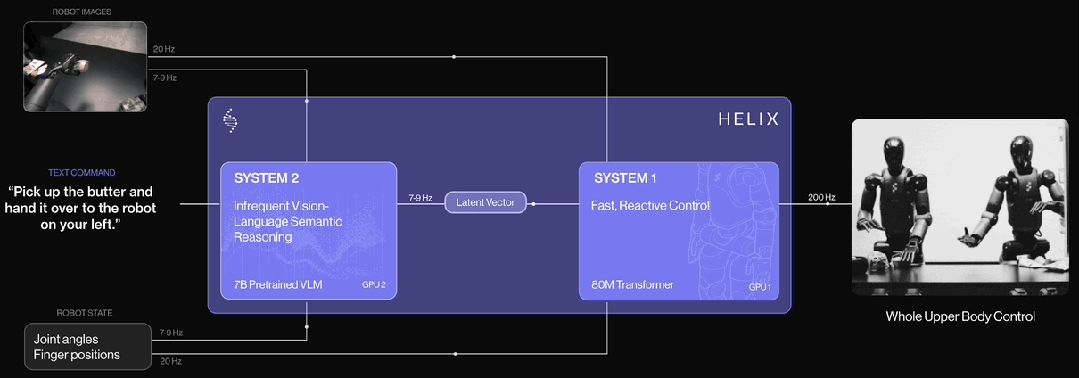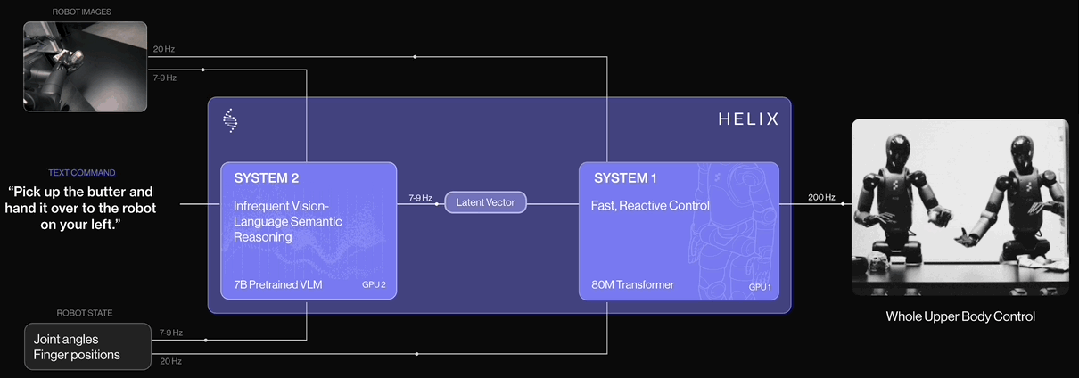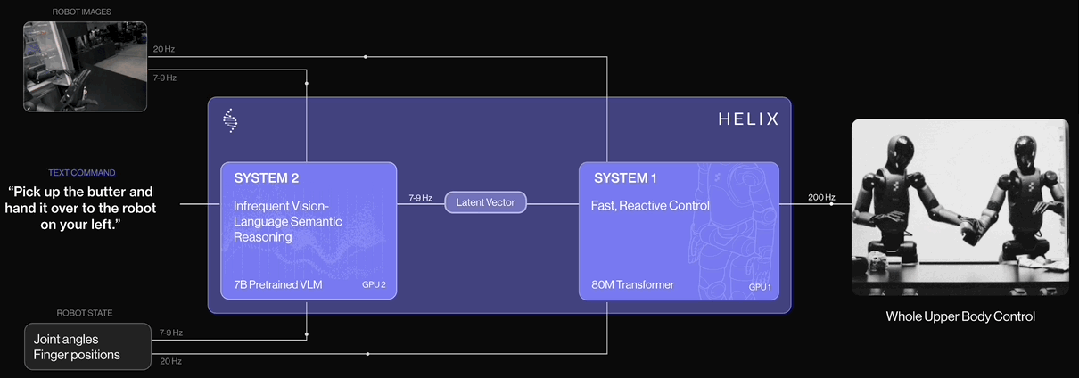
以往的方法面临一个根本性的权衡问题:视觉-语言模型(VLM)作为骨干网络具有广泛的泛化能力,但运行速度较慢;而传统的机器人视觉-运动策略速度很快,但泛化能力弱。Helix 通过两个互补的系统解决了这一矛盾,这两个系统是端到端训练,并能高效通信的:
System 2(S2):一个部署在机器人上的、基于互联网预训练的视觉-语言模型,运行频率为 7-9 Hz,负责场景理解和语言理解,使机器人具备对物体和语境的广泛泛化能力。
System 1(S1):一个快速响应的视觉-运动策略网络,将 S2 生成的潜在语义表示转化为 200 Hz 的精确连续动作,实现高速、实时的控制。
这种解耦的架构使两个系统能在各自最适合的时间尺度上运行:S2 负责"慢思考",处理高层语义和目标规划;S1 负责"快反应",实时执行和调整动作。例如,在协作行为场景中,S1 能快速适应伙伴机器人动作的变化,同时保持对 S2 所设定语义目标的执行。

结合上述信息,Helix最大的特色在于引入了快慢思考的概念,他的结构看上去和Pi0不一样,但实际上是类似的。Pi0里的动作专家(Action Expert)可以看成是Helix里的S1,Action Expert 的输入其实就是 VLM 中每个 token 的 hidden vector,这个 hidden vector就相当于是Helix中的Latent Vector。Helix的S2和S1就可以对分别应到Pi0预训练框架中的Pretrained VLM和Action Expert两个部分。
怎么理解Helix双系统的频率差别
从频率的角度来看,Figure Helix中提到的 s2 是 7 到 9 赫兹,s1 是 200 赫兹,两者频率差别非常大。如果没有双系统架构,可能整体架构就只有单一频率运行,比如Pi0目前的控制频率是 50 赫兹。
Pi0和 Gemini Robotics 目前都采用了同步架构,没有使用双系统异步架构。因为同步架构的响应速度对于绝大多数任务来说已经足够快,也更流畅了。异步架构真正带来的好处到底是什么?比如,让 S1 更快、更高频,这种提升在实际应用中能带来多少收益?这些问题还需要进一步了解。
在Figure发布Helix之前,智元曾在24年10月份,发了一篇RoboDual的双系统异步架构文章,比Helix早了5个月。而最近智元发布的GO-1的架构(本文第4部分会详细介绍)则采用了单系统同步架构,也是暂时认为在操作大模型上串行架构在5-10hz的模型推理频率上已经有比较好的效果。2025英伟达GTC上发布的Groot N1也采用了和Figure Helix类似的S1和S2双系统。所以从单双系统的选择上,不同公司在不同时期都会有不同的尝试,目前尚未有定论。
关于频率和运行时间的换算关系,我自己之前也搞不太清楚,为了便于后文的理解,这里将频率和时间的换算关系做一个解释:频率与周期互为倒数
频率(f):单位时间内周期性事件重复的次数,单位为赫兹(赫兹 = 1/s)。
周期(T):完成一次完整周期性事件所需的时间,单位为秒(s)。
如果周期为1秒一次,那么频率就是1赫兹,如果周期为每20毫秒(0.02秒)完成一次,那么频率就是50赫兹。
具体到Pi0架构,它每推理一次的时间约为 80 到 100 毫秒,也就是模型整体的执行频率大约是 10 赫兹(1/0.1=10)。这实际上与Helix中提到的 s2 频率(7-9赫兹)是相近的,谷歌的Gemini Robotics 端到端模型的推理时间是 200 毫秒,即 5 赫兹。这几个模型(Pi0、Gemini Robotics 和 Figure Heliex 中的 s2)整体推理频率量级都差不多。
虽然这些模型推理频率在 5-10 赫兹左右,但它们的 s2 都能够输出更高频率(如 50 赫兹)的控制信号。这是因为,尽管模型推理一次可能需要较长时间(比如 200 毫秒),但每次推理可以预测未来一段时间(例如未来两秒)的控制信号,因此可以实现高频控制输出。
既然这些模型的大脑部分本身就能达到 50 赫兹的控制信号输出,那么再额外增加一个频率更高的 s1 系统到底是为了解决什么样的问题?也许 Helix 看到了某些特别的问题,但他在论文里并未清晰说明。
怎么理解它的推理速度?为什么它的推理速度慢,但控制信号输出的频率却可以这么高?
因为每次推理的时候预测的是未来两秒钟的动作轨迹。每秒钟可以推理五次(每200毫秒推理1次,1秒=5*200毫秒,模型推理频率5赫兹),每次都可以推理出未来两秒的轨迹,相当于每次推理。模型虽然只有5赫兹的推理速度,但可以执行50赫兹的控制频率。
模型推理频率:模型推理一次是200ms(0.2s)的话,它连续推理可以做到1/0.2s = 5hz的频率。动作控制频率:模型推理一次,推理出的action,是一个有50个frames的chunk(假设对应预测未来1秒本体的运动)。 这50个frames,按间隔20ms(0.02s)发送给本体,进行本体动作控制。1/0.02s= 50Hz。模型预测的action频率是50hz,可以大概理解为模型一次推理50个未来的动作控制信号。这50个控制信号在1秒内执行完。
这里涉及到一个技术概念叫做Action Chunk:Action Chunk(动作块)是近年来在机器人学习和强化学习中提出来的一个概念,它的本质是将一段连续时间内的动作序列作为一个整体进行处理,而不是逐帧、逐步地预测动作。在传统的机器人控制中,模型每一步都会输出一个瞬时动作(例如每 20ms 控制一次电机),这叫做 step-wise control。而 Action Chunking 的想法是:一次性输出多个时间步的动作序列,把这几个时间步的动作合成一个"chunk"(块),可以看作是短时段的运动计划。
一个 Action Chunk 通常是指一段固定长度的连续动作向量,比如:模型每次输出一个 chunk,包含未来2秒的动作,每秒50帧,那么一个 chunk 就是 100 帧动作。这些动作可以是连续值(如关节角度),也可以是离散的 token(如 index 到一个动作字典中)。
总结来说,模型推理频率并不高,但由于每次推理都预测未来一段时间内的大量动作(如两秒内100帧),所以它可以支撑较高频率(如50赫兹)的控制输出。而实际上50赫兹的控制频率已经足够满足使用需求了。至于把控制频率从50赫兹提高到200赫兹,看起来可能更丝滑一些,但并非必要,这一点可能还有一些未被公开分享的额外观察。
怎么理解Helix的S1频率更快?
Pi0的S1和S2是串行执行的,也就是说Pi0的S2执行完后再执行S1,S1执行完之后再等待下一次S2的执行。而Helix的S1和S2是串并行的,S1是一个更小的模型(80兆),它独立执行,有更高的推理速度(200赫兹)。串并行的意思是它既可以是串行的,也可以是并行的。它有串行的部分,S1依赖于S2给它的信息。并行的部分就是S1可以单独去执行,不需要等待S2的推理结果。因为S1是独立执行的模型,他的模型结构可以做的更小,大概是80M大小,也就是8000万参数量的小模型,所以运行效率更高。这种结构使得它的S1动作输出频率达到200赫兹,而Pi0的动作输出频率是50赫兹。
S1本质上也是一个action expert,但它额外引入了一个叫做Latent Conditional Visual Motor Transformer的结构,即它额外增加了视觉信息(图像)作为输入,这意味着它不仅仅是直接从latent vector进入diffusion过程去denoise出一个action,而是额外加入图像信息后再进行denoise动作的过程。它额外引入图像输入的作用,主要是为了实现闭环控制,因为S1模型是独立执行的。
4. 智元ViLLA
根据智元官方的资料,为了有效利用高质量的AgiBot World数据集以及互联网大规模异构视频数据,增强策略的泛化能力,智元提出了 Vision-Language-Latent-Action (ViLLA) 这一创新性架构。GO-1这个通用具身基座大模型基于ViLLA构建,与VLA架构相比,ViLLA 通过预测Latent Action Tokens(隐式动作标记),弥合图像-文本输入与机器人执行动作之间的鸿沟。在真实世界的灵巧操作和长时任务方面表现卓越,远远超过了已有的开源SOTA模型。
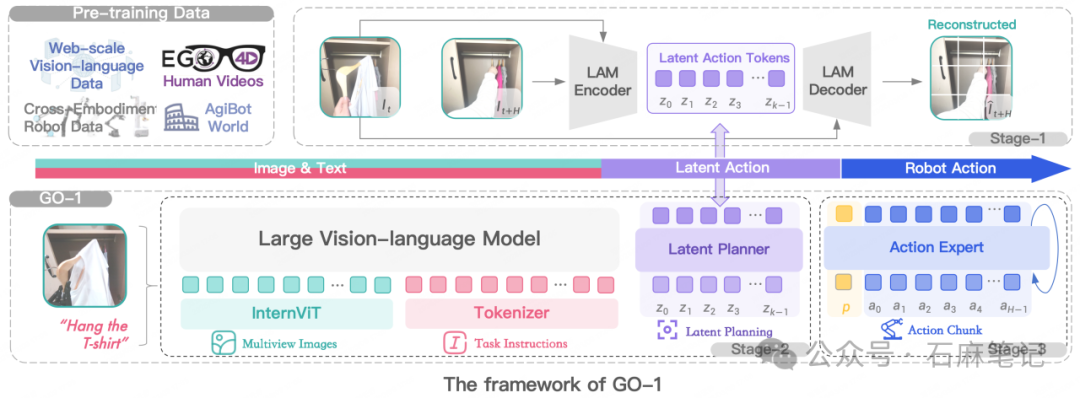
ViLLA架构是由VLM(多模态大模型) + MoE(混合专家)组成,VLM 采用InternVL2.5-2B,接收多视角视觉图片、力觉信号、语言输入等多模态信息,进行通用的场景感知和指令理解;Latent Planner是MoE中的一组专家,基于VLM的中间层输出预测Latent Action Tokens作为CoP(Chain of Planning,规划链),进行通用的动作理解和规划;Action Expert是MoE中的另外一组专家,基于VLM的中间层输出以及Latent Action Tokens,生成最终的精细动作序列;在推理时,VLM、Latent Planner和Action Expert三者协同工作。
潜在动作模型(LAM) 从大规模视频数据(如 Ego4D 中的人类视频)学习通用动作表示,并将其量化为离散的潜在动作 token。潜在规划器 通过预测潜在动作进行时间推理,在图像-文本输入与动作专家生成的机器人动作之间建立桥梁。
值得一提的是,最近GTC大会上,英伟达的NVIDIA Isaac GR00T N1和GO-1一样用的是三阶段(中间有一阶段是Latent Action)的预训练范式。而且真机数据中80%是用的是智元开源的AgiBot World百万真机数据。
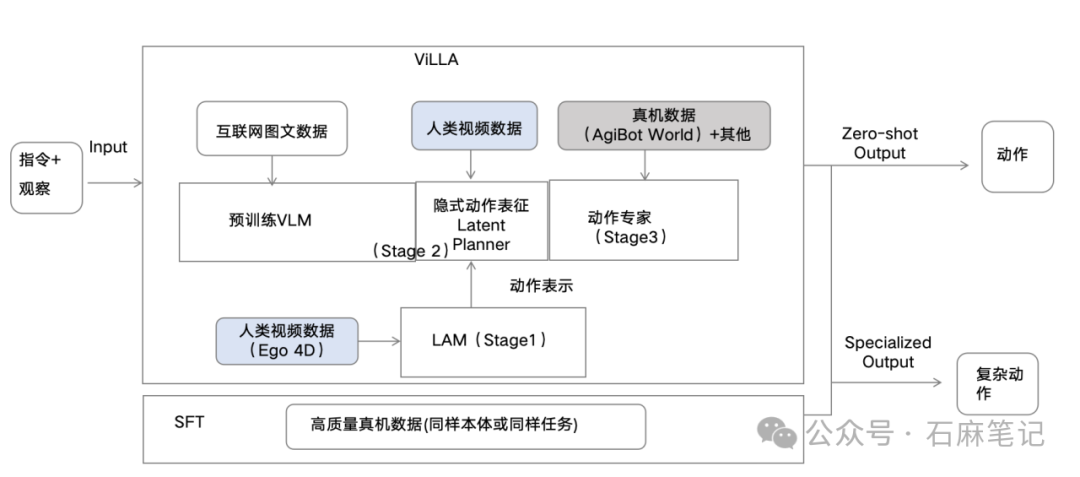
为了和Pi0的模型结构做直观的对比,我将ViLLA的模型结构抽象成上图。ViLLA如果只看Stage2和Stage3,它与Pi0的主要区别就在于中间的latent planner。为了训练这个latent planner,才有了Stage1的LAM模型。
为什么要在中间加一个LAM,因为现在机器人的数据太少了,尤其是模仿学习的真机数据极其有限,我们考虑如何利用人类视频数据来某种程度的解决机器人真机数据稀缺的问题。在模仿学习训练之前,引入人类操作物体的一些数据,让模型直接预测视频的未来帧。
假如我们要训练机器人去翻锅里的鸡蛋,这个动作和人类的操作——伸手拿铲子翻鸡蛋——在动作空间上是非常类似的。所以,我们先用人的数据,即人的视频数据,让模型学会预测。例如,看到人准备翻鸡蛋,就能预测未来鸡蛋是如何被翻过来的,把这种隐含的 latent action 预测能力先让模型学习到。
当模型再去训练机器人的模仿学习时,它就有更强的能力,可以更快理解机器人在翻鸡蛋时应该如何行动。这样在隐空间上的动作规划方向就更清晰,从而加速机器人的学习过程。
这些动作上的语义被压缩成 latent action tokens,然后模型去预测这些 latent action tokens,这就相当于模型具备了预测动作趋势的能力。而重建部分是由 LAM 的 decoder 负责完成的。
在ViLLA这个模型里,为了让它在一些具体任务上有更高的成功率,GO-1也有做一个后训练的部分。在文章里面,我们把这个过程叫做 SFT(Supervised fine-tuning),这个部分和Pi0里的后训练部分是类似的作用。
GO-1在自主推理的表现可以参看以下视频:AgiBotWorld,赞10
5. 关于通用操作路线的一些想法
通用操作路线至少有四五条,以Pi0为代表的这种大规模端到端模仿学习路线,分层路线(对话李昀烛:通用操作新解法——基于学习的动力学模型和VoxPoser & ReKep:从任务表征的角度探究机器人的零样本任务泛化),还有世界模型和仿真+Sim2Real相关的路线。也非常期待后续会有更多创业公司,在端到端模仿学习以外的路线上,做出成果。
前段时间和一个移动互联网公司的大佬午饭交流,他说的一句话可能是这几年我会一直会铭记的:未来会赢的那些人大概率已经下场了。在一个足够长的赛道,撇去喧嚣,沉下心来,跟进一些人,跟进一些事,积累认知,一切准备为了遇到那个最终会赢的人。
References:
Pi0
https://www.physicalintelligence.company/blog/pi0
Helix
https://www.figure.ai/news/helix
GO-1
https://agibot-world.com/blog/agibot_go1.pdf
RoboDual
https://arxiv.org/pdf/2410.08001

















 1766
1766

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









