






论文阅读:OpenVLA: An Open-Source Vision-Language-Action Model
背景
一些问题:
- 可学习的策略,无法泛化到训练数据之外。虽然现有的一些训练单体技能或者语言指令的策略可以将一些行为如物体位置或者“点亮”等外推到新的初始条件,但是缺乏对场景干扰的鲁棒性并且难以执行看不见的任务指令。(不过CLIP、SigLip、Llama2可以进行这方面的泛化)
- 在机器人中重现这种量级的预训练依然是挑战,因为最大的robot manipulation数据集也只有100k-1M的case。
- 已有的一些工作利用开源视觉-语言基础模型的预训练,直接在vlm上finetune来生成机器人控制动作(PaLI),RT-2 [7] 等 VLA 有着鲁棒性以及泛化到新对象和任务的能力。目前的VLA基本是闭源的且硬件部署条件不足。
贡献:
- OpenVLA由一个预先训练的视觉条件语言模型主干组成,该模型在多个尺度上捕获视觉特征,在Open-X Embodiment[1]数据集中的970k机器人操作轨迹的大型数据集上进行微调。
- 研究了 VLA 的有效微调策略,这是先前工作中没有探索的新贡献,跨越 7 个不同的操作任务。微调的 OpenVLA 策略明显优于微调的预训练策略,例如 Octo [5]。与具有扩散策略的从头开始模仿学习[3]相比,在多目标、多任务场景下有按照语言执行行为的显著进展。
- 证明利用低秩适应 [LoRA; 26 ] 和模型量化 [27] 计算高效微调方法的有效性,以促进部署。
相关工作:
Visually-Conditioned Language Models
目前新的开源工作收敛到“patch-as-token”的模式,把来自预训练的视觉transformer的补丁(patch)当作token,然后映射到语言模型的输入空间。我们使用来自Karamcheti等人[44]的VLM作为我们的预训练主干,因为它们是从多分辨率视觉特征训练的,融合了来自Dinov2[25]的低级空间信息和来自SigLIP[9]的高级语义,以帮助视觉泛化。
Generalist Robot Policies
像 Octo [5]这样的先前工作通常组成预训练的组件,例如语言嵌入或视觉编码器,并具有从头开始初始化的附加模型组件 [2, 5, 6],在策略训练期间学习将它们“缝合”。而OpenVLA采用一种端到端的方式,直接微调vlm并且把它们作为语言模型中的词典中的token,来生成机器人的动作。
Vision-Language-Action Models
直接将VLM集成到端到端视觉运动操作策略[14,15]中,但将显著结构纳入策略体系结构中或需要标定相机,这限制了它们的适用性。直接微调大型预训练的VLM来预测机器人动作[1,7,17,18,72]。这些模型通常被称为视觉语言动作模型 (VLA),因为它们直接将机器人控制动作融合到 VLM 主干中。比起RT-2-X [1],主要本文探索了微调策略
The OpenVLA Model
1. VLM
一般由visual encoder -> projector -> llm组成,本文的backbone是一个600M参数量的encoder(两部分视觉编码器SigLIP[77] 和 DinoV2 [25] ), 两层的MLP,7B-parameter Llama 2构成
Prismatic 使用两部分视觉编码器,由预训练的 SigLIP[77] 和 DinoV2 [25] 模型组成。输入图像块分别通过编码器传递,得到的特征向量按通道连接。与更常见的视觉编码器(如CLIP-[78]或仅SigLIP编码器)相比,DinoV2特征的添加已被证明有助于提高空间推理[44],这对机器人控制特别有帮助。
SigLIP / DinoV2 和 Llama 2 都没有发布有关其训练数据的详细信息,这可能分别由数万亿个互联网源图像-文本和纯文本数据的标记组成。Prismatic VLM 使用 LLAVA 1.5 数据混合 [43] 在这些组件之上进行了微调,该数据集包含来自开源数据集的大约 1M 图像文本和纯文本数据样本 [29, 42, 779-81]。

2、训练流程
为了使vlm语言模型backbone预测机器人行动,通过语言模型的tokenizer将连续的机器人动作映射为离散的tokens,从而在llm的输出空间中表达机器人行动。
参照Brohan et al. [7]的工作,把机器人actions分成256bins中。对每个action维度,设置bin的宽度均匀划分actions的第1到第99分位(每个分位当中的数据量相同,如二分、百分位)。使用分位数而不是最小-最大边界允许我们忽略数据中的异常值动作,否则可能会极大地扩展离散化间隔并减少我们的动作离散化的有效粒度。
由于Llama tokenizer [10] 使用的分词器仅对微调期间新引入的标记保留 100 个“special tokens”,这对于256个离散化动作标记来说太少了。所以用我们的action tokens覆盖Llama tokenizer 词典中最少使用的256个tokens(最后的256个)。
一旦动作被编码为一系列tokens,OpenVLA用标准的预测下一个token的目标进行训练,仅仅评估预测的action tokens的交叉熵loss。
3、训练数据
数据源于open x-embodiment dataset (openx),两个限制:
(1)训练数据是仅包含至少一个第三人称的相机、使用单臂末端执行器进行控制的数据集
(2)最终训练混合中实施例、任务和场景的平衡混合。使用octo的数据混合权重进行过滤。
4、OpenVLA Design Decisions
VLM backbon: Prismatic [44], IDEFICS-1 [ 82 ] and LLaVA [83 ] 最后使用prismatic,能够更好的融合SigLIP-DinoV2 backbones,提升了空间归因能力。
Image Resolution: 使用224
×
\times
× 224px作为图像输入,对于vla来说,提高分辨率没有增加太多性能。
Fine-Tuning Vision Encoder: 一般大家会冻住视觉编码器得到来自预训练的更鲁棒的feature,也有更好的效果。但是vla进行微调有更好的效果,我们假设预训练的视觉主干可能无法捕获关于场景重要部分足够的细粒度空间细节,以实现精确的机器人控制。
Training Epochs: 一般是训练1~2个epochs,但是vla训了27epochs
Learning Rate: 用固定的2e-5,没有使用warmup策略
实验
测试 OpenVLA 作为开箱即用的强大多机器人控制策略的能力以及微调新机器人任务的良好初始化。RT-1-X [1]、RT-2-X [1] 和 Octo [5]、RT-1-X(35M 参数)和 Octo(93M 参数是在 OpenX 数据集的子集上从头开始训练的transformer策略;RT-2-X明显优于RT-1-X和Octo,展示了大型预训练VLM对机器人的好处。
结合动作分块和时间平滑,如扩散策略中实现的,可能有助于OpenVLA获得相同的灵活性水平,可能是未来工作的一个有前途的方向(有关当前限制的详细讨论,请参见第6节)。
5.3 fine-tuning
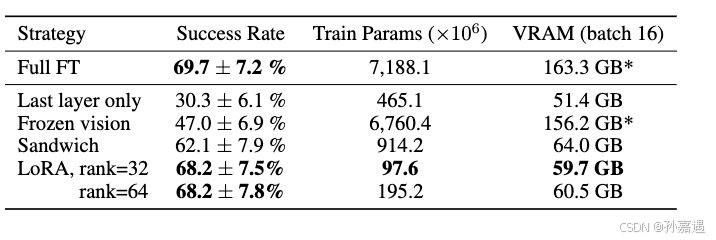
总结
就是把几个模块拼接起来,然后加载模块的预训练参数,调试一下看哪些层需要finetune;再加上为了训练以及推理搞了量化。。。

















 1820
1820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









