







paper:https://arxiv.org/pdf/2308.12032
code:https://github.com/MingLiiii/Cherry_LLM
一、TL;DR
- 在大型语言模型(LLMs)的领域中,指令数据的质量与数量之间的平衡是一个关键点。
- 提出了一种自我引导的方法,使LLMs能够自主识别并从开源数据集中选择最佳样本,从而有效减少人工策划和对LLMs指令微调的潜在成本。
- 指令遵循难度(IFD)指标成为识别模型预期响应与其内在生成能力之间差异的关键指标。
- 通过应用IFD,在Alpaca和WizardLM等数据集上模型仅使用原始数据5%-10%的樱桃数据就可以达到全量数据微调的效果
二、方法介绍
指令微调的作用:
指令微调是一种通过在模型训练阶段提供特定指导或指令来优化LLMs性能的方法。它通过向LLMs提供明确的训练指令,使其生成的输出更符合期望的结果。精心设计的指令或提示提供了必要的上下文信息,增强了模型生成相关和特定任务输出的能力
谁决定指令微调的性能?
此前,指令微调被认为依赖于积累庞大的数据集(Khashabi 等人,2020;Ye 等人,2021;Wei 等人,2022;Wang 等人,2022)。然而,LIMA(Zhou 等人,2023)认为决定模型性能的不是数据量,而是数据质量。LIMA的研究结果强调,即使是少量手工策划的高质量数据,也能提升模型遵循指令的能力。尽管它强调了数据质量的重要性,但如何从海量可用数据集中自动识别高质量数据的问题仍在研究之中。
我们的研究如何做?
我们提出了一种新方法,用于从广泛的开源数据集中自动识别最具影响力的训练样本,我们称之为““cherry data”:
- 我们假设的核心观点是,LLMs通过最初使用少量指令数据进行训练,可以内在地学会识别和遵循指令,从而估计指令数据的难度。
- 我们的方法涉及一个自我引导的过程:
- 该过程从“从简短经验中学习”阶段开始,让模型熟悉数据集的一个小子集。
- 随后是“基于经验的评估”阶段,在该阶段,我们引入了指令遵循难度(IFD)评分。这一指标通过比较模型在有无指令上下文时的响应损失,评估指令对相应响应生成的帮助程度。IFD评分越高,表明指令帮助越少,意味着指令难度越大。相反,IFD评分越低,则表示即使没有进一步训练,给定的指令也能直接极大地惠及语言模型,表明指令的简单性和必要性。
- 最终的“从自我引导经验中重新训练”阶段,我们使用IFD评分相对较高的数据作为精选数据来训练我们的模型,从而得到我们所说的“cherry model”。这一强调数据质量而非数量的方法论
将我们的方法应用于Alpaca和WizardLM指令微调数据集时,我们的模型仅使用大约5%的数据就超越了官方的Alpaca模型,仅使用大约10%的数据就超越了重新实现的WizardLM模型。
三、详细方法
如图1所示,我们的方法分为三个核心阶段:
- 从简短经验中学习:初始阶段着重于赋予模型基本的指令遵循能力
- 基于经验评估:提了新的指标,用于根据之前训练过的预体验模型来评估每个样本的指令遵循难度分数
- 从自我引导经验中重新训练:在获得目标数据集中的难度分数后,选择精选样本(cherry samples)来训练我们的最终模型,我们称之为精选模型(cherry models)。
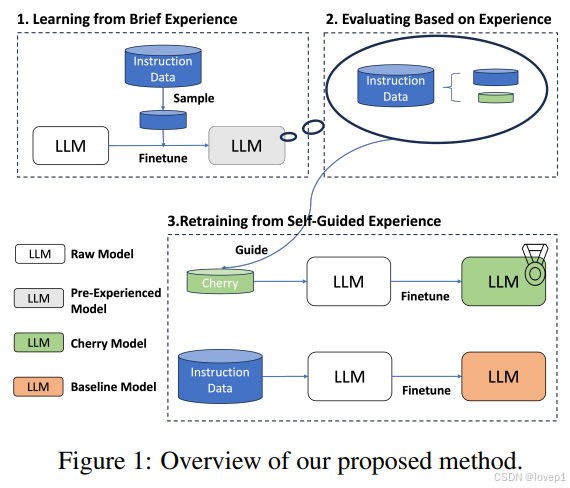
3.1 从简短经验中学习
这一阶段旨在通过迫使模型首先体验目标数据集的一个子集,赋予初始模型基本的指令遵循能力。具体来说,
- 初始数据集D0,其中包含 n 个三元组 x=(Instruction,[Input],Answer),
- 完整指令:字符串 Question=map(Instruction,[Input]) 。映射函数与原始目标数据集保持一致。我们将 Question(Q) 和 Answer(A) 中的每个词分别记为 xiQ 和 xiA。
- LLMθ :使用的大型语言模型,θ 表示 LLM 的权重,其中 θ0 表示预训练的基础 LLM 模型。然后,通过以下公式获得每个样本 xj 的指令embedding(就是对指令提取embedding,并且是对单条指令的所有token求了一个均值):
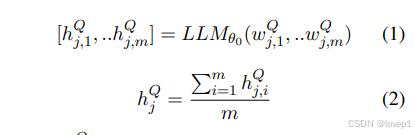
其中,wj,iQ 表示样本 j 的 Question 字符串中的第 i 个词,hj,iQ 表示其对应的最后隐藏状态。
具体如何操作?
对这些指令embedding上使用了基本的聚类技术 KMeans(保证指令具有多样性)。受 LIMA 研究成果的启发,我们在指令embeding上生成了 100 个聚类,并在每个聚类中采样了 10 个实例。然后,我们仅使用这些样本对初始模型进行 1 个周期的训练,以获得我们的简短预体验模型。
3.2 基于经验评估
引入指令遵循难度(Instruction-Following Difficulty,IFD)分数来评估每个指令样本所呈现的难度:
- 利用阶段一的init模型可以对数据集中所有样本进行预测,通过指令内容预测答案内容,并可以获取预测答案与真实答案直接的差异值(利用交叉熵),即条件回答分数
在指令微调过程中,样本对 (Q,A) 的损失通过持续预测给定指令 Q 及其后续词的下一个词来计算:
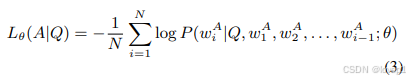
其中,N 是真实答案 A 的词数。我们将这种平均交叉熵损失记为条件答案分数 sθ(A∣Q)=Lθ(A∣Q)。这一指标评估模型根据提供的指令生成适当响应的能力。它衡量模型的输出与指令和相应的正确答案的一致程度。
然而,较高的 sθ(A∣Q) 并不意味着指令更难遵循,但也可能收到模型生成答案A的难易程度的影响(就是说本身某些答案就比较难生成),进一步引入了直接答案分数 sθ(A):
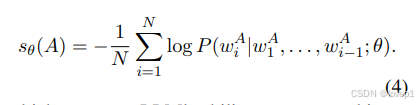
它衡量 LLM 单独生成这个答案的能力。它评估答案本身在没有其对应指令的上下文指导下的固有难度或挑战。较高的直接答案分数可能表明答案本身对于模型来说更具有挑战性或更复杂。
进一步分析样本的固有挑战与模型遵循指令的能力之间的平衡,有助于揭示估计给定样本指令难度的复杂性。具体来说,我们试图通过计算直接答案分数与条件答案分数的比值来估计给定 (Q,A) 对的指令遵循难度(IFD)分数 IFDθ(Q,A):
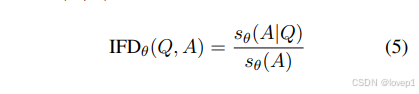
为了进一步筛选出指令与其响应不匹配的样本,我们设定了一个阈值 1。
- 通常,由于下一个词预测的固有性质,条件答案分数总是小于直接答案分数:在给定上下文的情况下,对后续词的预测应该更容易。
- 因此,如果 IFD 分数大于 1,条件答案分数甚至大于直接答案分数,这意味着给定的指令对响应的预测没有提供有用的上下文。在这种情况下,我们认为指令与相应的响应之间存在不匹配,难度和信息量更大,对模型调优更有利。
尽管我们的实验表明,从简短经验中学习很重要,但它使整个流程变得复杂且效率低下。然而,Superfiltering(Li 等人,2024b)扩展了 IFD 分数的使用,并表明:(1)良好的prompt可以减轻训练预体验模型的负担;(2)弱语言模型计算出的 IFD 分数与强模型一致,这使得可以利用小型模型进行筛选,进一步推动了指令微调数据筛选的效率。
四、Experiments
4.1 主要结果
主要结果:
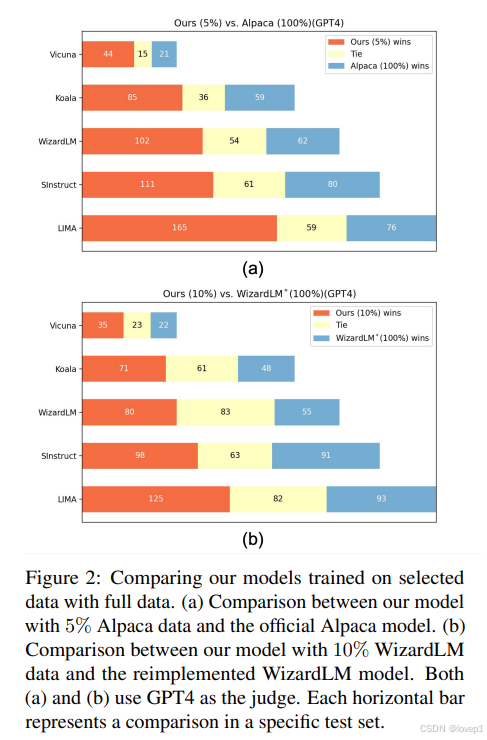
- 模型仅使用大约 5% 的原始 Alpaca 数据就击败了使用完整数据训练的 Alpaca 模型。
- 模型仅使用大约 10% 的原始 WizardLM 数据就击败了在相同训练配置下重新实现的 WizardLM 模型,该配置在实现细节部分有所描述。
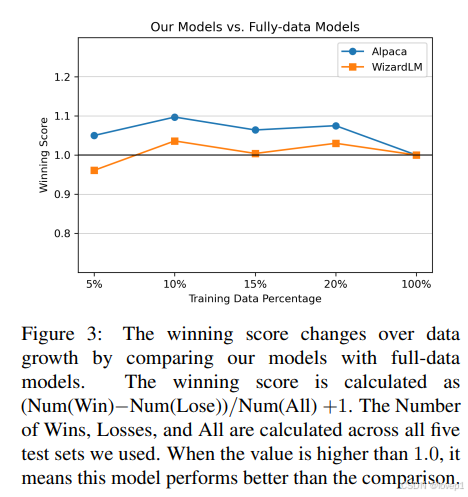
此外,我们制作了包含训练数据集的前 5%、10%、15% 和 20% 的子集来训练模型,使我们能够研究性能的变化,结论:仅使用 10% 精选数据,我们的模型就超过了使用完整数据集训练的模型的结果
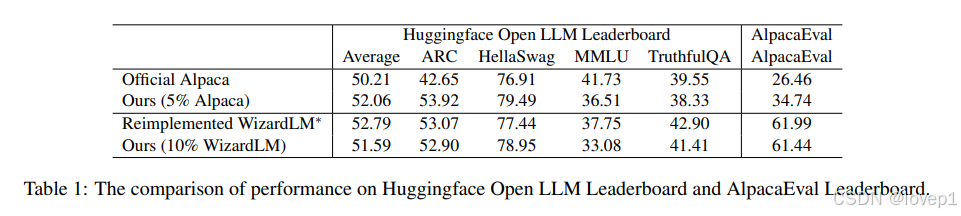
在表 1 中展示了我们的樱桃模型与基线模型在 Huggingface Open LLM Leaderboard 和 AlpacaEval Leaderboard 上的比较结果, 5% Alpaca 数据的樱桃模型在两个基准测试上都超过了官方的 Alpaca 模型,我们的使用 10% WizardLM 数据的樱桃模型与我们重新实现的 WizardLM 模型的性能相当接近。这些结果进一步展示了我们自动选择数据的有效性。
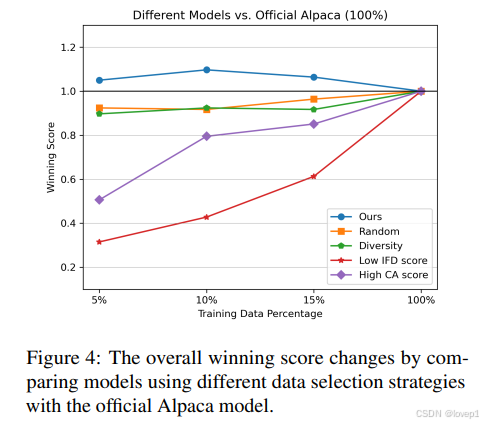
4.2 数据选择机制的消融研究
对比random、IFD采样、IFD低分采样、CAS采样四种方法对模型指令微调的影响,发现IFD采样在不同数据比例下,均高于全量数据微调效果,但其他采样方法均低于全量数据微调方法。
- 图中也给出,仅通过多样性来过滤数据对于指令调整是不够的(kmeans)。
- 较高的分数始终能产生更好的结果,而较低的分数则会降低模型的内在性能。这个实验直接展示了性能与 IFD 分数值之间的一致关系。
- 高 CA 分数在衡量指令遵循的复杂细微差别方面无作用
当抽样样本做实验时,初始模型的样本数量在100样本时,模型训练并没有作用,当样本增加到300时,模型具有了一定的指令遵循能力,IFD是有效的。

五、cherry-data的特点
提取的embedding进行tsne降维以后,如下所示:

樱桃数据并不是均匀分布的。相反,在高难度样本和低难度样本之间存在明显的边界,意味着指令数据并不是最大化多样性就是最好的。
为了进一步探究指令嵌入分布的复杂性,分析TSNE聚类后的簇:
- 以低 IFD 分数样本为主的簇充满了诸如标点符号、单词或句子编辑等基础任务。
- 高 IFD 分数簇则以更深入、更复杂的任务为特征,例如讲故事或解释现象。
以Alpaca 数据为例进行分析:
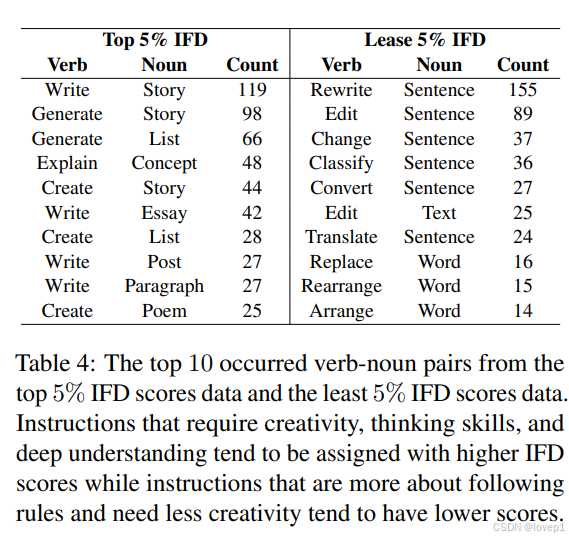
- 高 IFD 数据主要涉及诸如“写故事”“生成列表”和“解释概念”等富有创造力且复杂的指令,这些指令需要大量的创造力、思维能力和深刻的理解。
- 相反,低 IFD 数据更多地涉及遵循规则,需要的创造力较少,显示出不同任务对语言模型的思维和创造力需求存在很大差异。
因此,IFD 作为数据筛选的有效指标的原因可以归结为其能够找到需要更多创造力和深刻理解的指令。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









