







一、TL;DR
- InternVL3采用了一种原生的多模态预训练范式,在预训练阶段就从多样化的多模态数据和纯文本语料库中共同获取多模态和语言能力
- InternVL3引入了可变视觉位置编码(V2PE)以支持扩展的多模态上下文,采用了先进的post training技术(SFT+MPO),Test-time scaling测试和优化后的基建进行训练
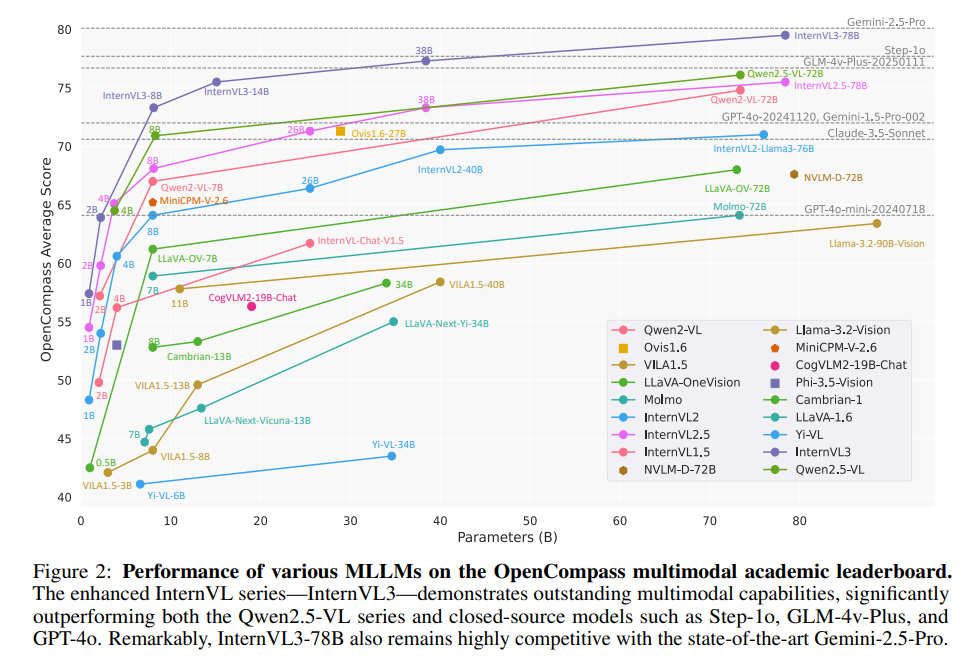
- InternVL3在多种多模态任务中表现卓越,InternVL3-78B在MMMU基准测试中获得了72.2分,与闭源商业模型相比也具备高竞争力
- 明天下载开源模型上手试试
二、引言和简介
现有的MLLMS的问题?
所有的MLLMs都是通过复杂的多阶段pipeline从纯文本的大型语言模型改编而来的,这些“post-hoc”方法是基于原始的基于文本的预训练过程构建的,因此在整合视觉等其他模态时会需要对齐;
具体来说,弥合模态之间的差距通常需要引入来自特定领域的辅助数据(例如,光学字符识别场景)以及复杂的参数冻结或多阶段SFT,以确保核心语言能力不受影响
如何解决这个问题?
InternVL3采用了原生的多模态预训练策略。在预训练阶段就通过同时接触纯文本语料库和多样化的多模态数据集来学习多模态能力。这种统一的方法使模型能够以更高效、更集成的方式同时获得语言和多模态能力,并且效果更好。
InternVL3 还通过多项创新进一步提升性能和可扩展性:
- 我们采用可变视觉位置编码(V2PE)机制来适应更长的多模态上下文。
- post-training:包括监督微调(SFT)和混合偏好优化(MPO)在内的先进后训练策略
- 测试时扩展策略 和优化的训练基础设施,显著提高了 InternVL3 的效率和性能。
取得了什么结果:
InternVL3 超越了InternVL2.5,包括:
- 多学科推理、文档理解、多图像/视频理解、现实世界理解、多模态幻觉检测、视觉定位和多语言能力。
- 通过引入扩展的特定领域数据集,InternVL3 在工具使用、图形用户界面代理、工业图像分析和空间推理方面也表现出显著改进,从而大大扩展了 InternVL 系列所涵盖的多模态场景。
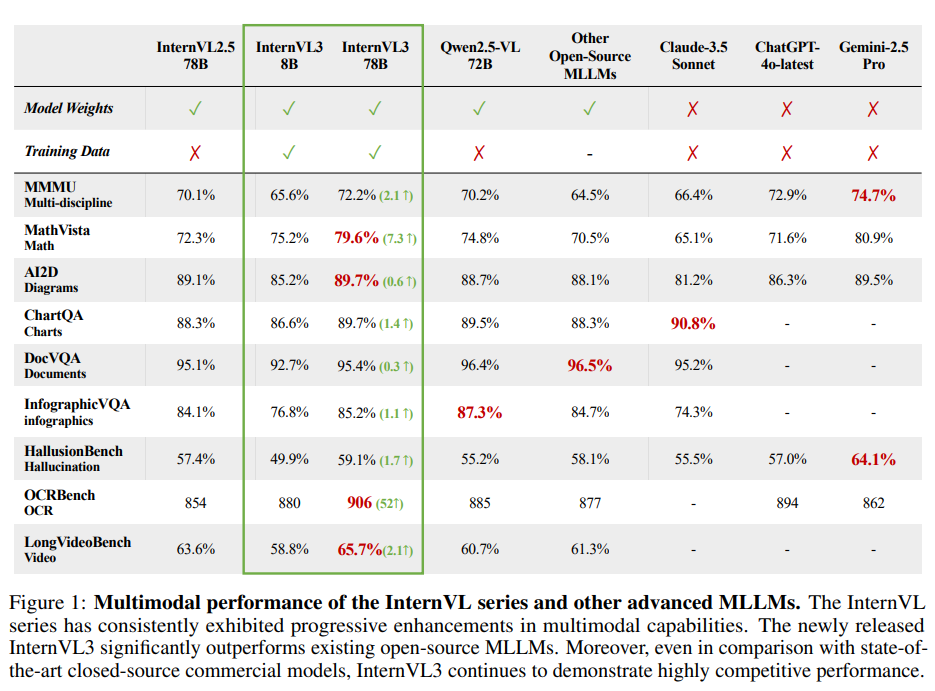
在MMMU 基准测试 中获得的 72.2 分:
- 与开源的 MLLMs(Qwen)相比具有极高的竞争力
- 与闭源模型(ChatGPT-4o 、Claude-3.5 Sonnet 、Gemini-2.5 Pro )相当。
- InternVL3 展示了与其他类似规模的先进 LLMs 相当的语言能力。
三、InternVL3.0
本节阐述 InternVL3 的核心组成部分,包括其模型架构、训练流程、测试时扩展策略以及基础设施层面的优化。
3.1 模型结构
InternVL3 的架构坚持“ViT-MLP-LLM”范式,详细配置如下表一所示:

模型结构上使用的各种手段如下所示:
- 为了降低计算成本,选择使用预训练模型权重初始化 ViT和 LLM组件:
- vision_encoder包括InternViT-300M 和 InternViT-6B
- LLM使用预训练好的 Qwen2.5 系列和 InternLM3-8B, LLM 组件仅从预训练的基础模型初始化,而不使用经过指令微调的变体;
- 模型中使用的多层感知机(MLP)是一个具有随机初始化的两层网络;
- 同时引入了pixel-shuffle的操作,将视觉token的数量减少到其原始值的四分之一,用 256 个视觉token来表示每个 448×448 的图像块
- 整合了可变视觉位置编码(V2PE),它为视觉token使用更小、更灵活的位置增量,能处理更长的多模态上下文。
3.1.1 详细说一下V2PE
每个 MLLM 的训练样本表示为:
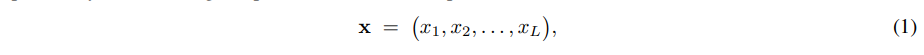
其中每个token xi 可以是文本token embedding、视觉embedding,或者是另一种模态特定表征(例如视频块embedding)。任何token xi 的位置索引 pi 可以按顺序计算如下:
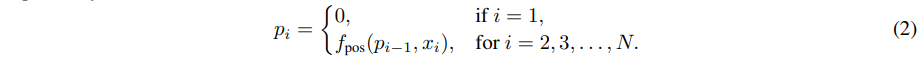
传统 MLLMs 的位置索引无论模态如何,每个token都均匀递增 1,而 V2PE 使用模态特定的递归函数来计算位置索引。这导致文本和视觉标记的位置索引分配不同
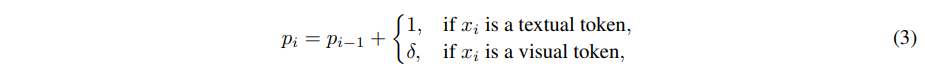
其中![]() 降低了视觉标记位置索引的增加速率。文本标记保留了标准的 1 的增量,以保持它们的位置区分。与原始 V2PE 设计一致,我们在单个图像内保持
降低了视觉标记位置索引的增加速率。文本标记保留了标准的 1 的增量,以保持它们的位置区分。与原始 V2PE 设计一致,我们在单个图像内保持 ![]() 恒定,以保持相对位置关系
恒定,以保持相对位置关系
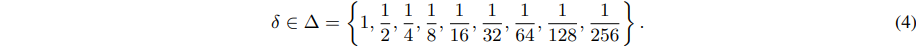
在推理期间,可以根据输入序列长度灵活选择![]() ,以在任务性能和确保位置索引保持在模型的有效上下文范围内之间取得平衡。值得注意的是,当
,以在任务性能和确保位置索引保持在模型的有效上下文范围内之间取得平衡。值得注意的是,当![]() 时,V2PE 恢复为 InternVL2.5 中使用的传统位置编码。
时,V2PE 恢复为 InternVL2.5 中使用的传统位置编码。
3.2 原生多模态预训练
我们的方法通过在预训练过程中交错使用多模态数据(例如图像-文本、视频-文本或交错的图像-文本序列)与大规模文本语料库进行集成优化。这种统一的训练方案使预训练模型能够同时学习语言和多模态能力,最终增强其处理视觉-语言任务的能力,而无需引入额外的桥接模块或后续的跨模型对齐程序。
3.2.1 多模态自回归公式
设 M 表示一个基于 Transformer 的模型,参数为 θ,能够同时处理文本、图像和视频。具体来说,对于任意训练样本 x={x1,x2,…,xL},其标记长度为 L,我们采用标准的从左到右的自回归目标:
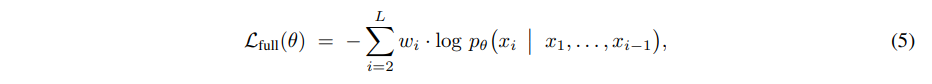
其中 wi 表示标记 i 的损失权重。尽管这种公式通过所有模态的token传播梯度,但我们仅对文本token进行损失计算,结果为:
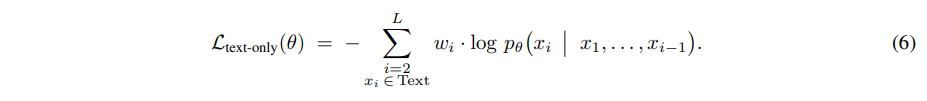
在这种选择性目标下,视觉token作为文本预测的条件上下文,而不是直接被预测。因此,模型学习以一种有利于下游语言解码任务的方式嵌入多模态信息。
关于token权重 wi 的设计选择,正如在 InternVL2.5 [18] 中讨论的那样,广泛使用的标记平均和样本平均策略可能会导致梯度分别偏向于更长和更短的响应。为了缓解这一问题,我们采用了平方平均,其定义如下:

3.2.2 联合参数优化
与传统的“仅语言训练后跟多模态适应”范式不同,我们的方法在多模态预训练期间联合更新所有模型参数。具体来说:
![]()
其中,Dmulti 是大规模纯文本语料库和多模态语料库(例如图像-文本或视频-文本对)的联合。我们通过这种方式优化一个单一模型来处理这些组合的数据源。这种多任务联合优化确保了文本表示和视觉特征同时学习,从而加强了模态之间的对齐(没看懂,就是只单独传播text,将其他模态数据当作上下文做input??)。
3.2.3 预训练数据
InternVL3 使用的预训练数据大致分为两类:
- 多模态数据和纯语言数据:包括现有数据集的综合以及新获取的真实世界数据,涵盖了图像描述、通用问答、数学、图表、光学字符识别(OCR)、知识定位、文档理解、多轮对话和医疗数据等多个领域
- 尽管总体数据规模没有增加,但通过更新 MLP 模块权重以及与 ViT 和 LLM 组件相关的权重,显著提高了该数据集的效用
- 从与图形用户界面(GUI)、工具使用、3D 场景理解和视频理解相关的任务中引入了额外的数据
语言语料库主要基于 InternLM2.5 的预训练数据构建,并进一步用各种开源文本数据集进行扩充。这种增强旨在提高模型在知识密集型任务以及数学和推理任务中的表现。
如何对异构数据源进行采样?
采用两阶段策略来确定多模态和语言数据之间的最佳采样比例:
- 分别在多模态和语言数据集上训练独立的模型,并在相应的基准测试中评估它们的性能,从而确定每种模态内的最佳采样比例
- 在固定的总训练预算下,我们将两种模态结合起来,并确定它们的相对采样比例
- 实证研究表明,语言数据与多模态数据的比例为 1:3 时,能够在单模态和多模态基准测试中取得最佳的整体表现
- 总训练token数约为 2000 亿,其中 500 亿来自语言数据,1500 亿来自多模态数据。
3.2 后训练
完成原生多模态预训练后,采用两阶段后训练策略:
- 监督微调阶段(Supervised Fine-Tuning, SFT):模型通过正向监督信号学习高质量的响应
- 混合偏好优化阶段(Mixed Preference Optimization, MPO):我们引入正负样本的额外监督,从而进一步提升模型的整体能力。
3.2.1 监督微调(SFT)
- 沿用了 InternVL2.5 中提出的随机 JPEG 压缩、平方损失重加权和多模态数据打包技术。
- 与 InternVL2.5 相比,InternVL3 在 SFT 阶段的主要改进在于使用了更高质量和更多样化的训练数据。具体来说,我们扩展了工具使用、3D 场景理解、图形用户界面(GUI)操作、长文本任务、视频理解、科学图表、创意写作和多模态推理的训练样本。
3.2.2 混合偏好优化(MPO)
为什么要引入MPO:
- 训练时模型是基于之前的真值token来预测下一个token,推理时模型是基于自身之前的输出来预测每个token
- 真值token与模型预测token之间的差异会导致分布偏移,从而削弱模型的思维链(Chain-of-Thought, CoT)推理能力
如何解决:
混合偏好优化(MPO),通过引入正负样本的额外监督,使模型的响应分布与真值分布对齐,从而提升推理性能。
详细原理:
MPO 的训练目标是偏好损失 Lp、质量损失 Lq 和生成损失 Lg 的组合,具体公式如下:
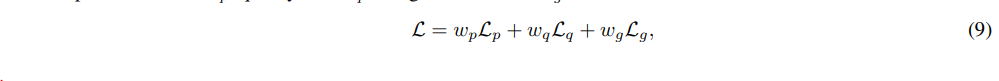
其中,w∗ 表示分配给每个损失组件的权重。具体来说,DPO 损失作为偏好损失,使模型能够学习选择和拒绝响应之间的相对偏好:
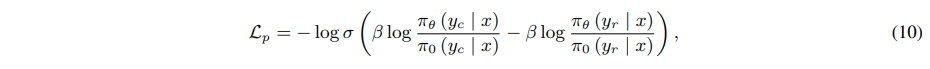
其中,β 是 KL 惩罚系数,x、yc 和 yr 分别是用户查询、选择的响应和拒绝的响应。策略模型 πθ 从模型 π0 初始化。之后,BCO 损失被用作质量损失,帮助模型理解单个响应的绝对质量:
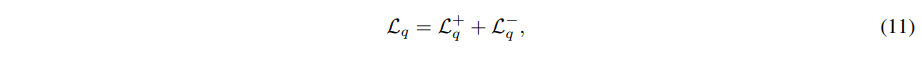
其中,Lq+ 和 Lq− 分别代表选择和拒绝响应的损失,它们独立计算,要求模型区分单个响应的绝对质量。损失项如下:
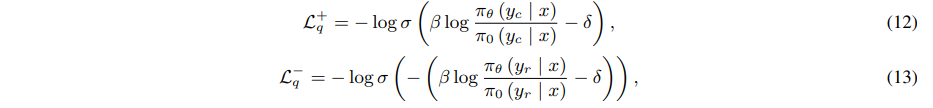 其中,δ 表示奖励偏移,通过计算先前奖励的移动平均值来稳定训练。最后,使用语言模型(LM)损失作为生成损失,帮助模型学习首选响应的生成过程,损失函数在公式(6)中定义。
其中,δ 表示奖励偏移,通过计算先前奖励的移动平均值来稳定训练。最后,使用语言模型(LM)损失作为生成损失,帮助模型学习首选响应的生成过程,损失函数在公式(6)中定义。
3.2.3 数据
对于监督微调(SFT)数据:
- 我们在 InternVL2.5 的基础上构建了训练语料库,并引入了额外的工具使用、3D 场景理解、图形用户界面(GUI)操作、科学图表、创意写作和多模态推理样本。因此,训练样本的数量从 InternVL2.5 的 1630 万增加到了 InternVL3 的 2170 万。
对于混合偏好优化(MPO)数据:
- 我们根据 MMPR v1.2 提出的数据管道和样本构建了偏好对,这些数据覆盖了广泛的领域,包括通用视觉问答(VQA)、科学、图表、数学、光学字符识别(OCR)和文档理解。我们使用 InternVL3-8B、38B 和 78B 的 SFT 版本来生成 rollout 数据。在 MPO 阶段,所有模型都在同一个数据集上进行训练,该数据集包含约 30 万个样本。
3.3 测试时扩展(Test-Time Scaling)
(这里就没怎么看了,简单摘要了下翻译,明天继续看)
采用“最佳候选选择”(Best-of-N)评估策略,并使用 VisualPRM-8B作为批评模型,用于选择推理和数学评估中的最佳响应。
视觉过程奖励模型(Visual Process Reward Model)。VisualPRM 首先为解决方案的每一步分配一个质量评分,然后计算这些评分的平均值以获得整体评分。这一过程被设计为一个多轮对话任务,以便充分利用多模态大型语言模型的生成能力。具体来说,图像 I、问题 q 以及逐步解决方案 s={s0,s1,…,sn} 的第一步 s0 被包含在第一轮中,随后的每一轮依次呈现新的步骤。在训练阶段,模型需要预测每一轮中给定步骤的正确性:
![]()
其中 ci∈{+,−} 表示第 i 步的正确性。在推理阶段,每一步的评分被定义为生成“+”的概率。
数据。我们使用 VisualPRM400K来训练 VisualPRM,该数据集基于从 MMPR v1.2收集的多模态问题构建。遵循 VisualPRM400K 的数据管道,我们进一步通过采样 InternVL3 的 8B 和 38B 版本的 rollout 来扩展 VisualPRM400K。
3.4 基础设施
问题点:
多模态大型语言模型训练的一个关键挑战是由于视觉和文本标记比例不同而导致的计算负载不平衡。这种不平衡可能会导致 ViT 或 LLM 模块过载,从而降低效率。
方法:
为了解决这一问题,将 InternEVO 框架扩展到支持 InternVL 模型的训练,我们引入了一套动态平衡各模块计算负载的技术,确保资源的高效和公平利用。
有效克服了可扩展性瓶颈,同时保持了计算效率。为了支持长达 32K 标记的序列,我们的方法结合了头部并行和序列并行技术
结果:
与 InternVL2.5 的训练相比,InternEVO 在 InternVL3 中的应用使得在相同计算预算下,同规模模型的训练速度提升了 50% 到 200%。
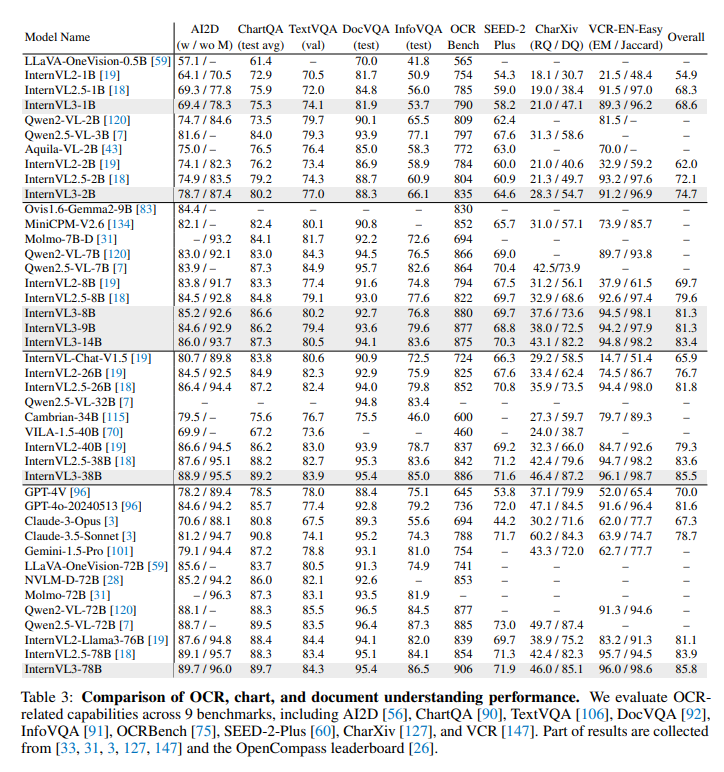
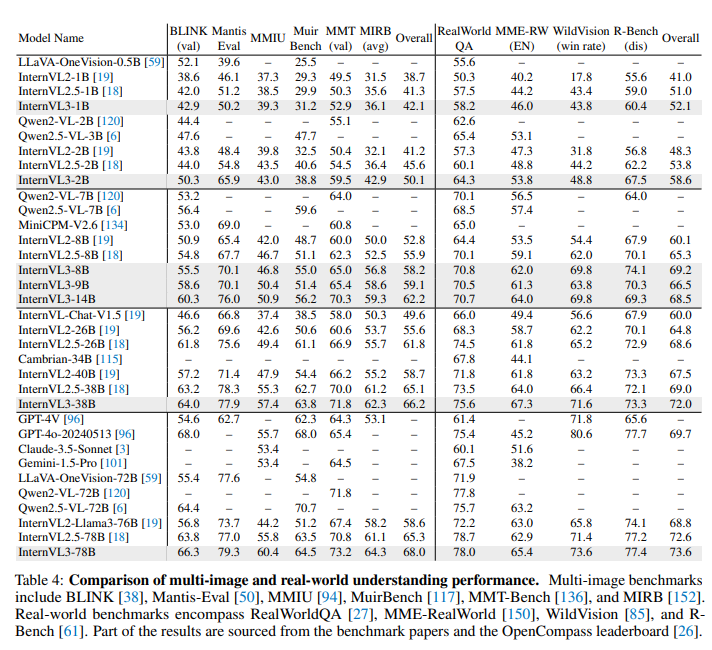
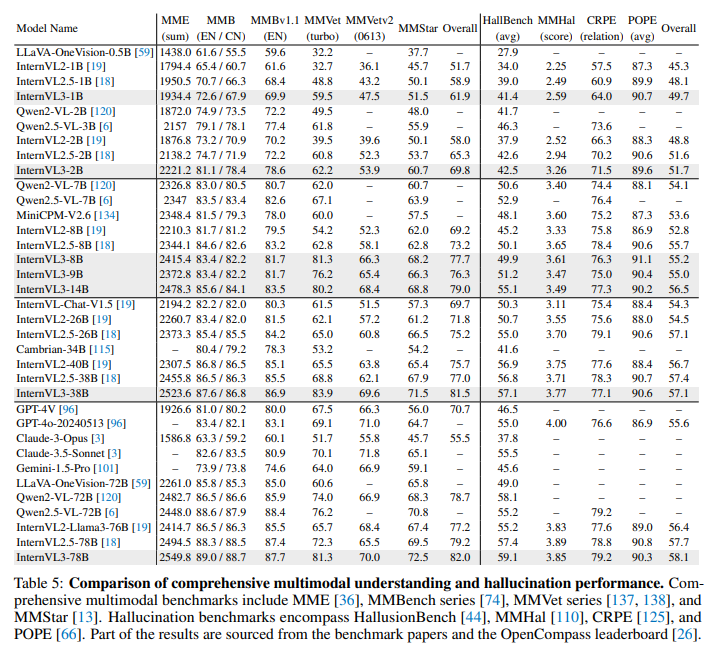
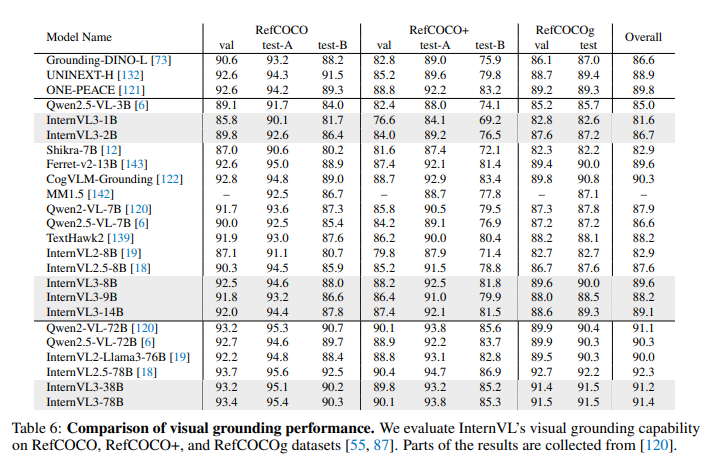
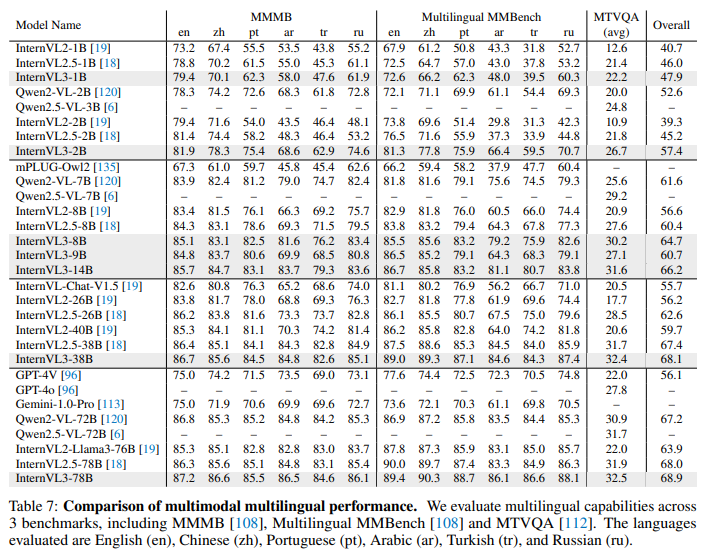
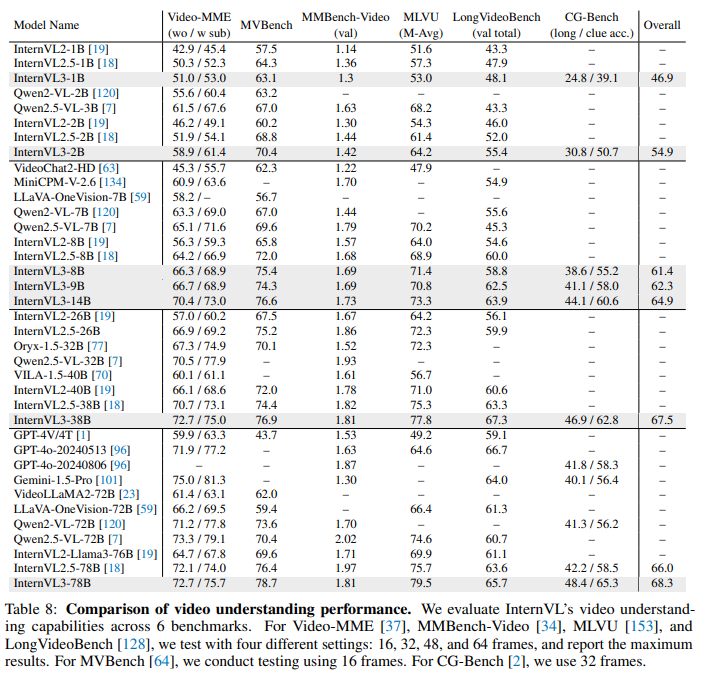
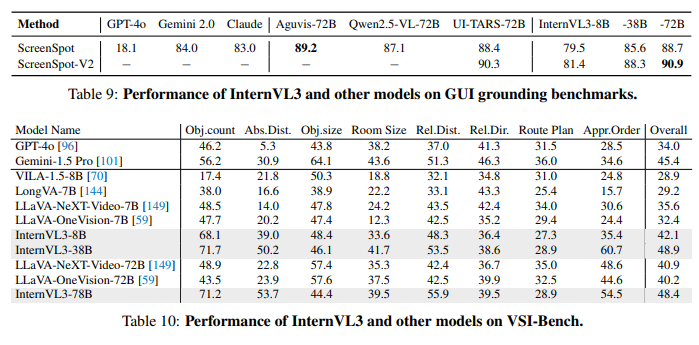
四、Experiments


















 1913
1913

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









