






目录
一、TL;DR
- 核心观点:
- 高质量的数据过滤网络与下游的表现是不一致的,下游性能好的网络可能过滤不出高质量数据,性能差的网络可能过滤出高质量数据
- 二阶段训练方法,先用高质量数据train出DFN,然后再使用DFN来filter出induced dataset,再训练induced model
- 实际数据集:DFNs与大型未过滤的图像-文本池进行filter,产出20亿高质量的图文数据集:DFN-2B(20亿)等数据集,下游指标遥遥领先同等数据量的数据集
二、Introduction
2.1 apple的结论
开局放大招,直接说明高质量数据是可以节省算力+提升性能的:

2.2 业界做法:
LAION数据集的构建方法:

很显然,上述数据的构建方法非常依赖open AI的clip模型,模型的性能会限制实际过滤出的数据的质量(我理解是某些具备高信息熵的FN会被漏掉,且FP会进来),根据我实际的数据集构建经验也确实如此,不再加一级人工逻辑数据集几乎无法直接使用,clip的判断在图像文本对的描述如果足够细节的情况下,极其容易出错,尤其是在小批量数据增加上,会给实际训练的模型带来退化;
DataComp数据集构建和评估方法:
Common Crawl包括128亿对图像-文本配对,通过使用各种数据filter技术的效果固定使用open-ai的vit-L14的训练资源来评估imagenet等38个下游任务的性能,将这个基准测试作为评估fiter网络的主要方法;
同时,datacomp的作者还发布了DataComp-1B的数据集,该数据集是通过聚类和clip的筛选2个方法来提高数据集质量,从而改进来LAION5B,但该方法依旧依赖clip的模型性能,并且引入了昂贵的聚类算法
2.3 我们的做法(Apple)
适用范围:高效的过滤达数万亿的样本,因此数据池子要求比较大,如果满足数据过滤的网络,则保留数据,如下是伪代码:

对于给定的DFN和数据池子,用于训练DFN的数据池称之为过滤数据集,用于DFN过滤后构建的数据集是诱导数据集,将DFN的性能定义为诱导模型的性能,该性能是通过标准的基准测试上评估得到的(例如DataComp上一样),则DFN的质量就是诱导数据集训练出来的模型的强度,apple是基于DataComp来构建的;
apple使用1.28亿、12.8亿、128亿三个级别的数据池子,且使用每个池子的提供的模型超参数也和DataCOmp一致,此外,通过将300亿非DataComp网络爬取的图像与DataComp超大规模池相结合,将DFN扩展到一个包含420亿图像的更大池中。然后使用DFN诱导出的数据集表示为DFN-5B,最后用它来训练一个ViT-H/14模型。
想当然的想法是使用上一次的模型去进行筛选获得新的高质量数据,最好能够递归的进行这个过程,但是apple的这篇工作却说明这样未必是work的,常见的思路都是使用当前的模型来做过滤,训练一轮以后在使用新的模型来作为过滤,如此迭代,但是下面这张图说明了模型的的过滤表现和最终Imagenet的下游性能也许是不相关的(这其实和我做的一些工作结论不太一致)

上图表示,DFN的下游任务性能哪怕差30个点(0.80-0.45-0.55),但是诱导出来的数据集的Imagenet性能还更高
2.4 如何获取好的DFN
核心理念:数据质量是训练好的过滤模型的关键,

如上图所示,横坐标是噪音数据的占比,也就是网络爬取(CC2M中的采样的1KW原始干净的数据),poison是对里面进行一定高质量数据替换成爬虫数据的比例,我们发现,被替换后10%左右,DFN的性能急剧下降,而后缓慢下降,因此说明训练DFN的数据一定是要高质量的数据,一旦引入一点低质量数据,则DFN的性能就会下降,则诱导模型的性能仅仅会比sample的好一点。
总体来说,保留图像和文本对齐后的数据是作者推荐的。
2.5 其他的方法
作者也使用了其他几种生成DFN:
- 二分类器方法
- 训练一个二分类器,将ImageNet或CC12M数据作为正样本,Common Crawl数据作为负样本
- 使用clip的模型冻结作为特征提取,然后不更新clip的的权重,只更新head
-
M3AE方法
-
使用M3AE作为DFN,在CC12M的数据上进行训练,使用reconstruction loss作为过滤标准,reconstruction loss是用于训练DFN的一个合理指标
-
优势:
-
多模态处理,能够同时处理图像和文本,可以进行综合考虑;
-
自监督模型不需要额外的标注数据训练
-
-
-
对比上述的方法:
-
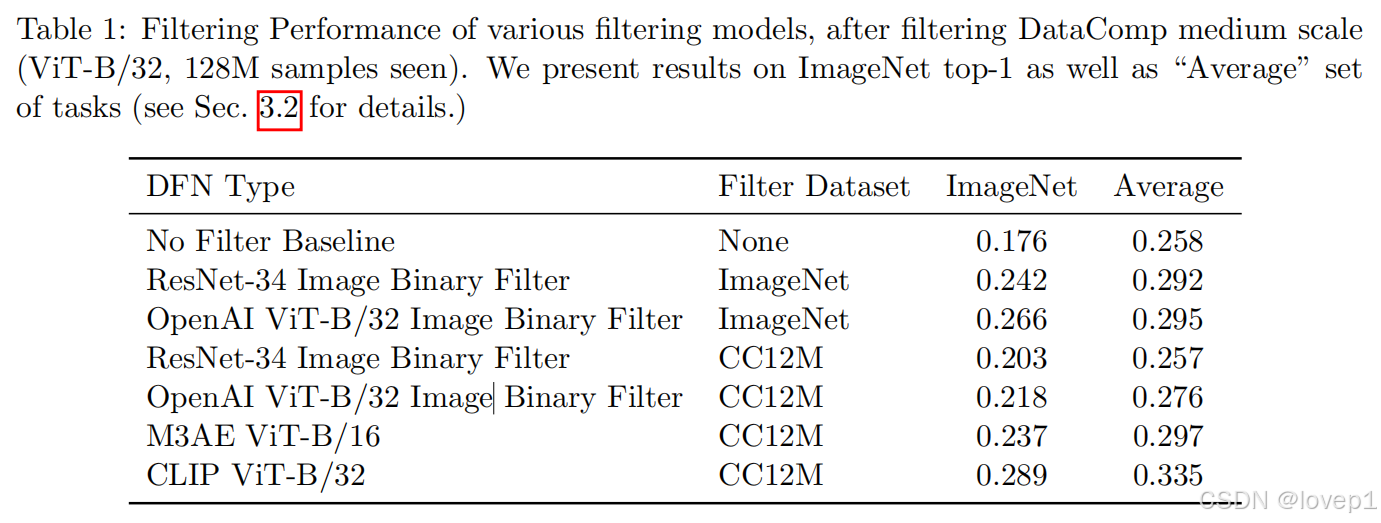
-
上述表格中也可以发现,clip还是最好的DFN方法,其次是M3AE,在imagenet上指标高,而且下游的Average的指标上也很高
-
三、如何构建更好的CLIP模型用于DFN
上文2.5节已经给出了clip是最佳方法,DFN的clip具体如何实现呢?paper认为首先在高质量数据集上训练一个CLIP模型,然后可以在后续数据集上对过滤网络进行微调,以便在这些数据集上表现得更好,另一方面,使用不同模型大小似乎收益有限,而模型集成则增加了过滤成本,却没有带来收益。与之前的DataComp-1B(DC-1B)数据集(涉及将CLIP过滤与基于聚类的启发式方法相结合)相比,DFNs将数据过滤过程简化为一个单一的流程,同时降低了计算成本。
apple先在HQTITP-350M上训练一个vit-b-32的clip模型,先用openai的clip初始化weights,在coco、flickr 30k和imagenet-1k的数据集进行finetune,通过这个DFN在DataComp的完整128亿数据集中,取top15%的数据作为DFN-2B,得到最佳的数据集
这些改进不仅提升了过滤模型的性能,还简化了数据过滤流程,降低了计算成本。DFN-2B数据集的创建展示了这种方法的有效性,为后续的机器学习任务提供了高质量的数据支持。
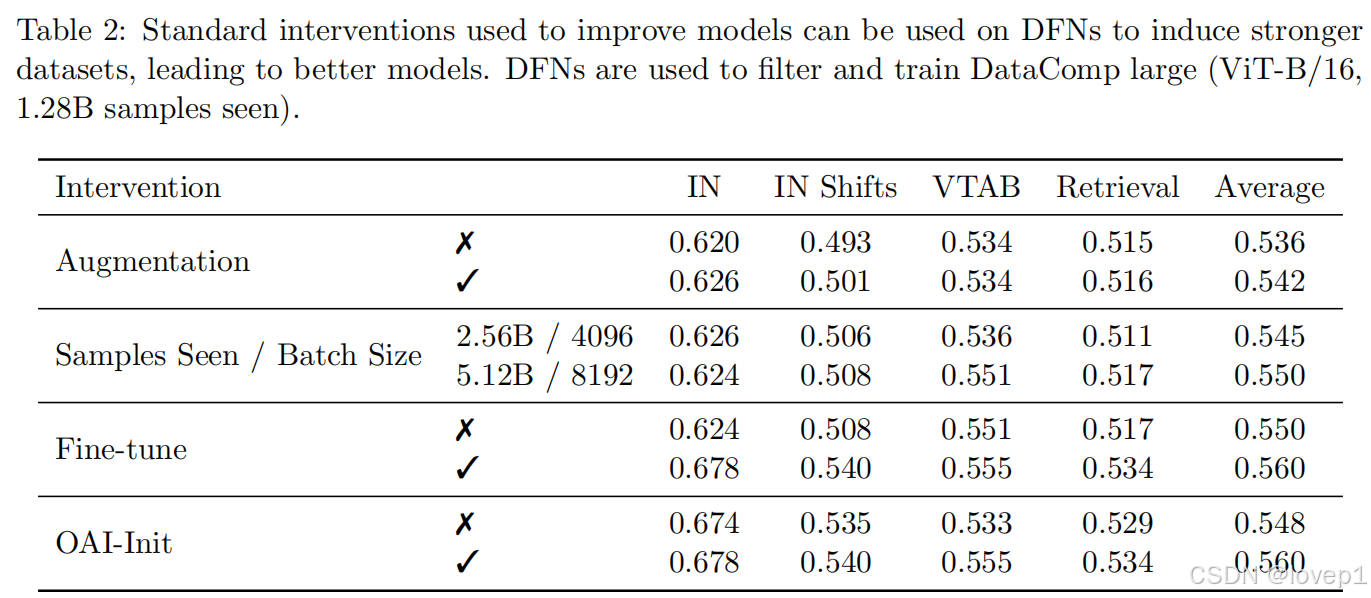
上面的图例给出来可以看到finetune的方法是最有用的,我理解这是不是代表着需要在自己的数据集上进行finetune,才能够进一步保证DFN是work的。
使用DFN给出benchmark,paper说在任何其他基础数据集上都取得sota的效果,然后给出了在DataComp上的效果:
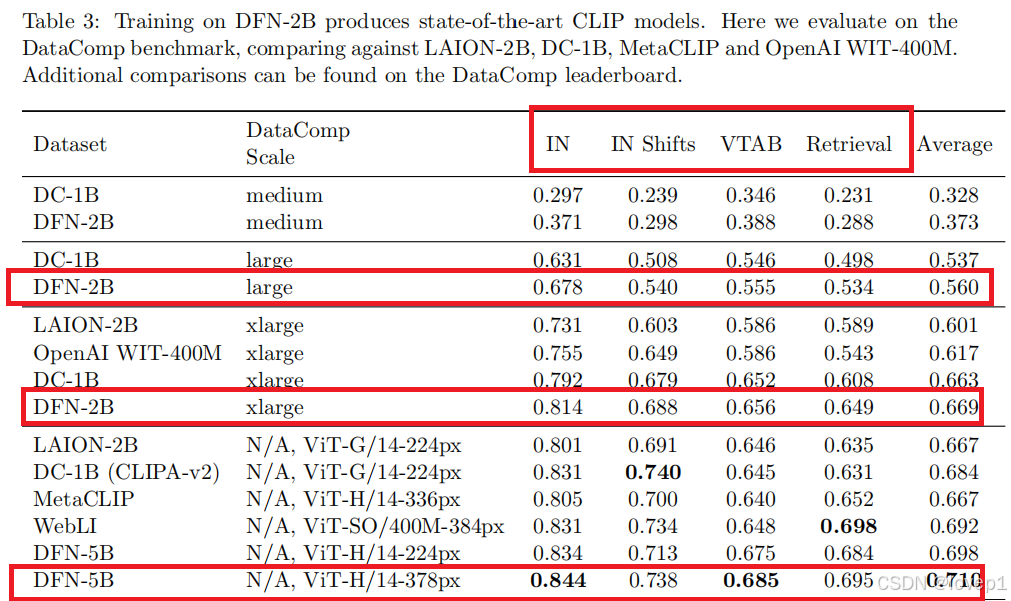 值得注意的是,上述的评测指标中,分布偏移、检索、VTAB、平均性能这几个metric需要好好看下。
值得注意的是,上述的评测指标中,分布偏移、检索、VTAB、平均性能这几个metric需要好好看下。
四、Discussion(直接翻译)
DFN流程的简单性使其成为一种可以灵活集成到现有工作流程中的工具。由于DFNs是针对单个样本进行操作的,这种方法的扩展性与候选池的大小呈线性关系,DFNs可以过滤一批原始数据,这些数据随后被用于训练,从而减少了对复杂数据预处理程序的需求。
本文仍然不知道如何直接优化数据集的质量,因此选择使用对齐等较弱的一些指标。甚至对于DFNs可以应用的其他领域(如语音、文本或视频数据),我们也不清楚该使用什么样的指标。我们希望这些开放性问题以及DFNs在建模工作和数据集工作之间搭建的桥梁能够开辟出富有成果的新研究途径。

















 355
355

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









