










Neural Style开辟了计算机与艺术的道路,可以将照片风格化为名家大师的画风。然而这种方法即使使用GPU也要花上几十分钟。Fast Neural Style则启用另外一种思路来快速构建风格化图像,在笔记本CPU上十几秒就可以风格化一张图片。我们来看看这是什么原理。
传统的Neural Style基于VGG构建了一个最优化模型。它将待风格化图片和风格化样本图放入VGG中进行前向运算。其中待风格化图像提取relu4特征图,风格化样本图提取relu1,relu2,relu3,relu4,relu5的特征图。我们要把一个随机噪声初始化的图像变成目标风格化图像,将其放到VGG中计算得到特征图,然后分别计算内容损失和风格损失。内容损失函数为:
有了上面两个损失函数,就可以构建感知损失函数:
Fast Neural Style则可以在普通笔记本电脑中十几秒运算出一个风格化图像。在一些科普文中是这样解释:Neural Style每次风格化都重新训练了一次生成过程,把这个过程提前做好,就可以加速风格化。我觉得这个说法有点奇怪,来看看原文流程图:
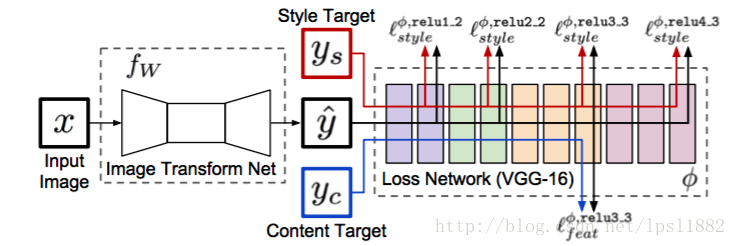
这个模型有两个部分,后面一个loss network就是普通Neural Style的VGG网络,这里只当做计算loss的网络,不进行训练;前面一个Image Transform Network一般是一个deep residual CNN,即喜闻乐见的深度残差网络,要训练这个网络。然而,深度残差网络的结构跟VGG是不同,训练深度残差网络不等于提前做好VGG生成过程。这里的思想,我认为是一种生成-判别模型,有生成对抗网络GAN的影子:深度残差网络-》生成模型,VGG-》判别模型。
下面的代码来自国人大神 hzy46,我将预测部分的代码已经升级迁移到python3 tensorflow 1.0正式版:
def resize_conv2d(x, input_filters, output_filters, kernel, strides, training):
'''
An alternative to transposed convolution where we first resize, then convolve.
See http://distill.pub/2016/deconv-checkerboard/
For some reason the shape needs to be statically known for gradient propagation
through tf.image.resize_images, but we only know that for fixed image size, so we
plumb through a "training" argument
'''
with tf.variable_scope('conv_transpose') as scope:
height = x.get_shape()[1].value if training else tf.shape(x)[1]
width = x.get_shape()[2].value if training else tf.shape(x)[2]
new_height = height * strides * 2
new_width = width * strides * 2
x_resized = tf.image.resize_images(x, [new_height, new_width], tf.image.ResizeMethod.NEAREST_NEIGHBOR)
return conv2d(x_resized, input_filters, output_filters, kernel, strides)
def residual(x, filters, kernel, strides):
with tf.variable_scope('residual') as scope:
conv1 = conv2d(x, filters, filters, kernel, strides)
conv2 = conv2d(tf.nn.relu(conv1), filters, filters, kernel, strides)
residual = x + conv2
return residual
def instance_norm(x):
epsilon = 1e-9
mean, var = tf.nn.moments(x, [1, 2], keep_dims=True)
return tf.div(tf.subtract(x, mean), tf.sqrt(tf.add(var, epsilon)))
with tf.variable_scope('conv1'):
conv1 = tf.nn.relu(instance_norm(conv2d(image, 3, 32, 9, 1)))
with tf.variable_scope('conv2'):
conv2 = tf.nn.relu(instance_norm(conv2d(conv1, 32, 64, 3, 2)))
with tf.variable_scope('conv3'):
conv3 = tf.nn.relu(instance_norm(conv2d(conv2, 64, 128, 3, 2)))
with tf.variable_scope('res1'):
res1 = residual(conv3, 128, 3, 1)
with tf.variable_scope('res2'):
res2 = residual(res1, 128, 3, 1)
with tf.variable_scope('res3'):
res3 = residual(res2, 128, 3, 1)
with tf.variable_scope('res4'):
res4 = residual(res3, 128, 3, 1)
with tf.variable_scope('res5'):
res5 = residual(res4, 128, 3, 1)
with tf.variable_scope('deconv1'):
deconv1 = tf.nn.relu(instance_norm(resize_conv2d(res5, 128, 64, 3, 2, training)))
with tf.variable_scope('deconv2'):
deconv2 = tf.nn.relu(instance_norm(resize_conv2d(deconv1, 64, 32, 3, 2, training)))
with tf.variable_scope('deconv3'):
deconv3 = tf.nn.tanh(instance_norm(conv2d(deconv2, 32, 3, 9, 1)))
y = (deconv3 + 1) * 127.5明显可以看到这里用了反转卷积conv2d_transpose,可以用resize_conv2d代替,也就是先放大图像然后卷积,数学意义相同,工程效果比直接conv2d_transpose要好,这是生成模型的标配啊!整个模型中,深度残差网络不断从原图生成目标风格化图像,然后VGG不断反馈深度残差网络存在的问题,从而不断优化生成网络,直到生成网络生成标准的风格化图像。最后要投入使用的时候,后面VGG判别网络根本不需要,只需要前面的深度残差生成网络,就像GAN一样。
Fast Neural Style的优点有:
- 生成速度快。
- 训练好的模型文件不大,载入简单。不需要VGG网络,那个tensorflow model有500MB。
缺点有:
- 训练速度很慢。官方推荐用coco数据集训练深度残差网络,这个数据集小的也有13GB,运行要几十个小时。
- 一个生成网络只能生成一种风格化图像。我们训练生成网络,使用的风格化图像只能用一种。
由于训练的太慢,我就直接用hzy46大神的训练好的model。经过训练后的图像:
INFO:tensorflow:Elapsed time: 1.455744s
你们看,2015 macbook pro低配版上只要1.5秒钟就完成了这个252x252的图像的风格化。
https://github.com/artzers/MachineLearning/tree/master/Tensorflow/fast-neural-style















 1764
1764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









