







知识蒸馏论文翻译(1)——CONFIDENCE-AWARE MULTI-TEACHER KNOWLEDGE DISTILLATION(多教师知识提炼)
文章目录
摘要
基于置信度的多教师知识提取(CA-MKD),该方法在地面真值标签的帮助下,自适应地为每个教师预测分配样本可靠度,并为那些接近一个热标签的教师预测分配较大的权重。此外,CA-MKD还结合了中间层的特征,以稳定知识转移过程。
代码链接:https://github.com/Rorozhl/CA-MKD
一、介绍
知识提取(KD)通过从预先训练过的笨重教师模型中提取知识来提高轻量级学生模型的准确性[4]。转移的知识最初被形式化为教师模型[4]的softmax输出(软目标),而后者扩展到中级教师层,以实现更高的绩效[5、6、7]。
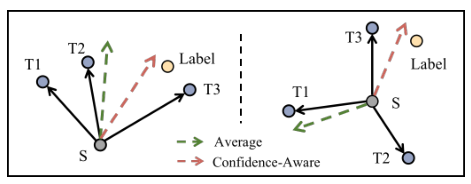
多教师知识提炼(MKD)方法,并已被证明是有益的[8,9,10,11,12]。基本上,他们将来自多个教师的预测与固定权重分配[8,9,10]或其他各种无标签方案相结合,例如基于优化问题或熵准则[11,12]计算权重。然而,固定权重无法区分高质量教师和低质量教师[8,9,10],而其他计划可能会在低质量的教师预测面前误导学生[11,12]。图1提供了一个关于这个问题的直观说明,一旦大多数教师的预测有偏差,使用平均权重策略训练的学生可能会偏离正确的方向。
真实值标签可以量化教师预测的准确度,然后过滤掉低质量的预测,以便更好地培训学生。为此,我们提出了基于置信度的多教师知识提取(CA-MKD),通过考虑教师的预测置信度来学习样本权重,实现自适应知识整合。置信度是基于预测分布和地面真值标签之间的交叉熵损失得到的。与之前的无标签加权策略相比,我们的技术使学生能够从相对正确的方向学习。
我们的自信感知机制不仅能够根据不同教师的样本信心自适应地加权预测,而且还可以扩展到中间层的学生-教师特征对。借助生成的灵活有效的权重,可以避免那些主导知识转移过程的糟糕的教师预测,并显著提高学生在8种师生架构组合上的表现(如表1和表3所示)。

二、相关工作
知识提炼Knowledge Distillation。Vanilla KD旨在将知识从复杂的网络(教师)转移到简单的网络(学生),使其软化输出之间的KL差异最小化[13,4]。后者提出从中间层模仿教师的表征,以探索更多的知识形式[5,6,14,15,7]。与这些需要对教师进行预培训的方法相比,一些工作同时培训多名学生,并鼓励他们相互学习[16,17]。我们的技术不同于这些在线KD方法,因为我们试图从多个经过预培训的教师那里提取知识。
多教师知识提炼Multi-teacher Knowledge Distillation。MKD没有雇佣一位老师,而是通过整合多位老师的预测来提高蒸馏的有效性。提出了一系列方法,例如简单地为不同的教师分配平均权重或其他固定权重[8,9,10],并基于熵[12]、潜在因子[18]或梯度空间中的多目标优化[11]计算权重。然而,这些无标签策略可能会在低质量预测的情况下误导学生培训。例如,基于熵的策略更倾向于盲目相信的模型,因为它有利于低方差的预测[12];基于优化的策略有利于大多数人的意见,并且容易被嘈杂的数据误导[11]。相比之下,我们的CA-MKD量化了基于TruthLabel的教师预测,并进一步提高了学生的表现。
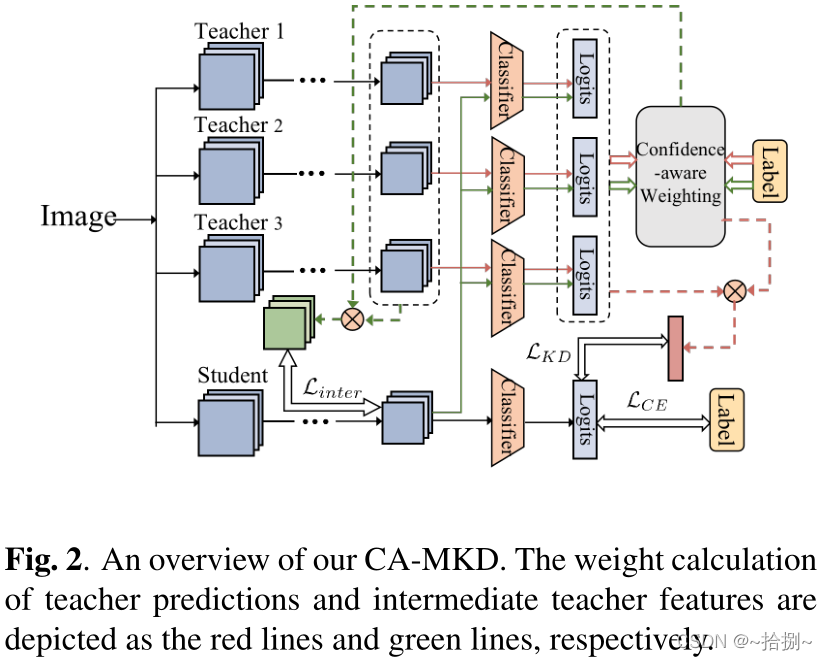
三、方法
我们将
D
=
{
x
i
,
y
i
}
D=\{x_i,y_i\}
D={xi,yi}表示为一个标记的训练集,N是样本数,K是教师数。
F
∈
R
h
×
w
×
c
F\in\reals^{h\times w\times c}
F∈Rh×w×c是最后一个网络块的输出。我们将
z
=
[
z
1
,
.
.
.
,
z
C
]
z=[z^1,...,z^C]
z=[z1,...,zC]表示为logits输出,其中C是类别号。最终的模型预测由温度为τ的softmax函数
σ
(
z
c
)
=
e
x
p
(
z
c
/
τ
)
e
x
p
(
z
j
/
τ
)
\sigma (z^c)=\tfrac{exp(z^c/\tau)}{exp(z^j/\tau)}
σ(zc)=exp(zj/τ)exp(zc/τ)得到。在以下部分中,我们将详细介绍我们的CA-MKD。

3.1 教师预测的损失
为了有效地聚合多个教师的预测分布,我们通过计算教师预测和基本真理标签之间的交叉熵损失来分配不同的权重,以反映其样本置信度
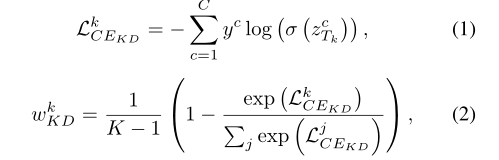
其中
T
k
T_k
Tk表示第k位老师。
L
C
E
K
D
k
L^k_{CE_{KD}}
LCEKDk越小,对应于
w
K
D
k
w^k_{KD}
wKDk越大。然后将教师的总体预测与计算出的权重相加。

根据上述公式,预测更接近真实值标签的教师将被分配更大的权重 w K D k w^k_{KD} wKDk,因为它有足够的信心做出正确的判断,以便正确引导。相比之下,如果我们只是通过计算教师预测的熵来获得权重[12],那么当输出分布尖锐时,无论最高概率类别是否正确,权重都会变大。在这种情况下,这些有偏见的目标可能会误导学生的训练,并进一步损害其蒸馏性能。
3.2 中级教师特征的缺失
除了受FitNets[5]启发的KD Loss外,我们认为中间层也有利于学习结构知识,因此我们将方法扩展到中间层,以挖掘更多信息。中间特征匹配的计算如下所示
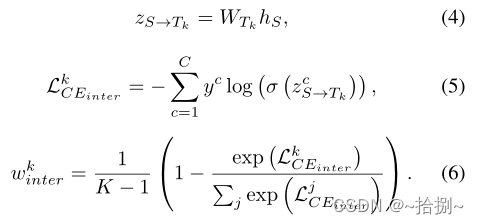
其中
W
T
k
W_{T_k}
WTk是第k个教师的最终分类器。
h
s
∈
R
c
h_s\in\reals^c
hs∈Rc是最后一个学生特征向量,即
h
S
=
A
v
g
P
o
o
l
i
n
g
(
F
S
)
h_S=AvgPooling(F_S)
hS=AvgPooling(FS)。
L
C
E
i
n
t
e
r
k
L^k_{CE_{inter}}
LCEinterk是通过将
h
S
h_S
hS传递给每个教师分类器而获得的。
w
i
n
t
e
r
k
w^k_{inter}
winterk的计算与
w
K
D
k
w^k_{KD}
wKDk的计算类似。
为了稳定知识转移过程,我们将学生设计成更专注于模仿具有相似特征空间的教师,而
w
i
n
t
e
r
k
w^k_{inter}
winterk实际上是一个相似性度量,表示教师分类器在学生特征空间中的可辨别性。研究还表明,利用
w
i
n
t
e
r
k
w^k_{inter}
winterk而不是
w
K
D
k
w^k_{KD}
wKDk在中间层进行知识聚合更有效。
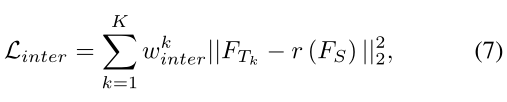
其中
r
(
⋅
)
r(\cdot)
r(⋅)是一个用于对齐学生和教师特征尺寸的函数。
ℓ
2
\ell_2
ℓ2loss函数用作中间特征的距离度量。最后,特征对之间的整体训练损失将通过
w
i
n
t
e
r
k
w^k_{inter}
winterk进行汇总。在我们的工作中,只采用最后一个块的输出特性,以避免产生太多的计算开销。
3.3 总损失函数
除了上述两种损失,还计算了与真实值标签的规则交叉熵。
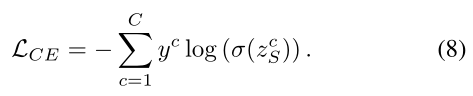
CA-MKD的总体损失函数总结如下:
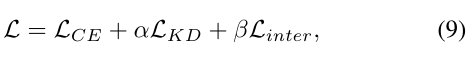
其中,α和β是超参数,用于平衡知识提取和标准交叉熵损失的影响
四、实验
在本节中,我们在CIFAR100数据集[19]上进行了大量实验,以验证我们提出的CA-MKD的有效性。基于流行的神经网络结构,我们采用了八种不同的师生组合。除特殊声明外,所有比较多教师知识提炼(MKD)方法均使用三名教师。
比较方法。除了naıve AVER[8]之外,我们在多教师上重新实现了一种基于单个教师的方法FitNet[5],并将其表示为FitNet MKD。FitNet MKD将利用来自平均中级教师功能的额外信息。我们还在我们的图像分类任务中重新实现了一种基于熵的MKD方法[12],该方法在声学实验中取得了显著的结果,我们将其称为EBKD。至于AEKD,我们采用基于logits的版本,代码由作者提供[11]。
超参数。所有神经网络均采用动量为0.9的随机梯度下降法进行优化,重量衰减0.0001。批量大小设置为64。与之前的工作[15,7]一样,初始学习率设置为0.1,除MobileNetV2外,ShuffleNetV1和ShuffleNetV2均设置为0.05。在第150个、180个和210个训练周期时学习率乘以0.1,其中一共有240个训练周期。为了公平起见,在所有方法中,温度τ设置为4,α设置为1。此外,在整个实验过程中,我们将CA-MKD的β设置为50。所有结果均以平均值和标准差的形式在不同随机种子的3次运行中报告。
4.1 相同教师架构的结果
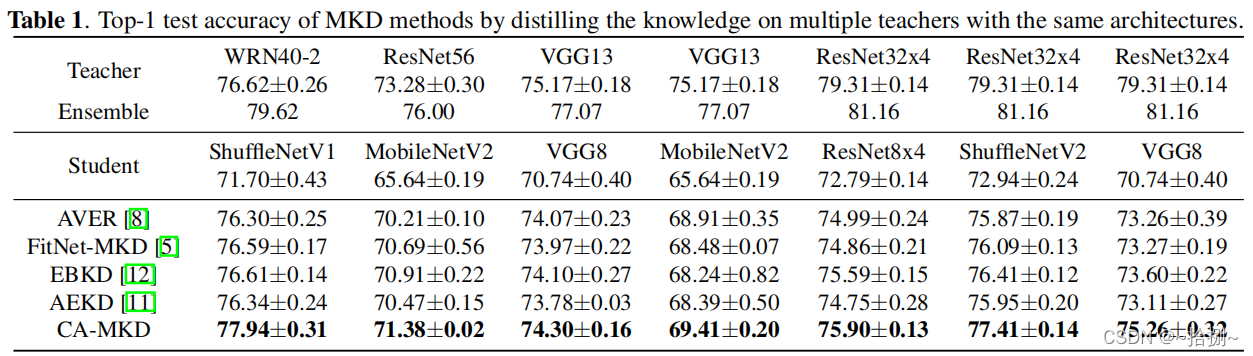
表1显示了CIFAR-100上的顶级精度比较。我们还包括了教师团队和多数投票策略的结果。我们可以发现,CA-MKD在各种体系结构中都超过了所有竞争对手。
具体而言,与第二好方法(EBKD)相比,CA-MKD的性能平均提高了0.81%,在最佳情况下,绝对准确度提高1.66%。
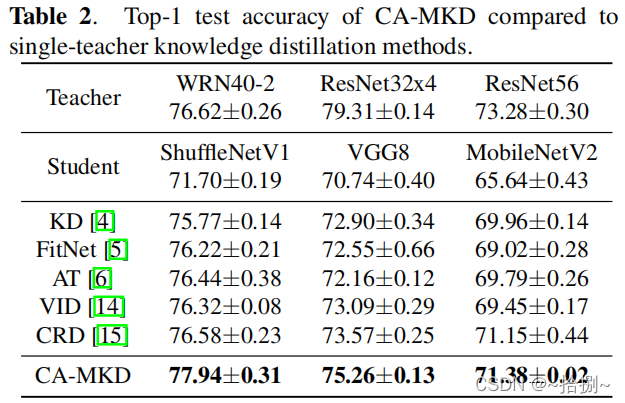
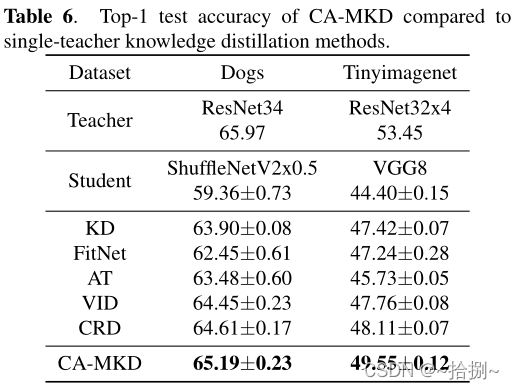
为了验证多个教师带来的不同信息的益处,我们将CA-MKD与一些优秀的基于单个教师的方法进行了比较。表6的结果显示,学生确实有潜力从多个老师那里学习知识,与单一老师的方法相比,其准确性在一定程度上进一步提高。
4.2 不同教师结构的结果
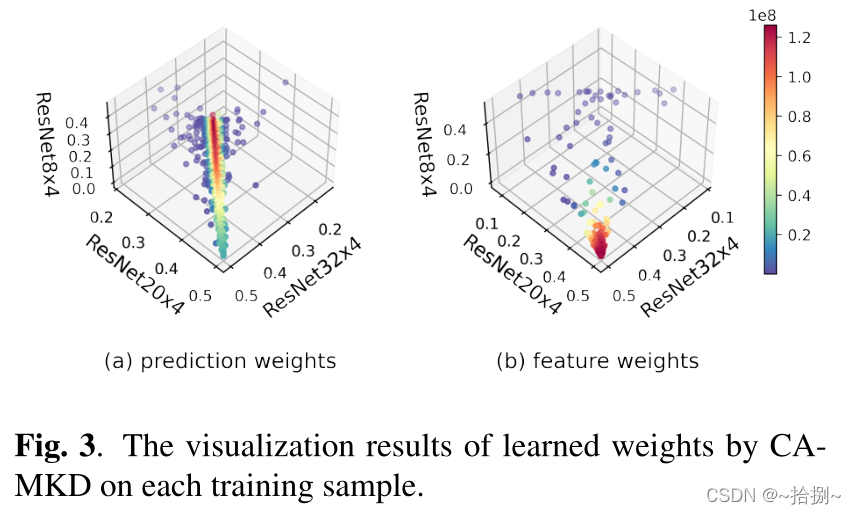
表3显示了使用三种不同教师体系结构(即ResNet8x4、ResNet20x4和ResNet32x4)对学生(VGG8)进行培训的结果。我们发现,学生的准确率甚至比三名ResNet32x4教师的培训更高,这可能是因为不同架构中的知识多样性有所扩大
由于ResNet20x4/ResNet32x4的性能优于ResNet8x4,我们可以合理地相信,对于大多数训练样本,学生将对前两个而不是后一个的预测施加更大的权重,这在图3中得到了验证。此外,我们的CA-MKD可以捕获通过ResNet8x4预测更可靠的样本,并为它们分配动态权重,以帮助学生模型获得更好的性能。
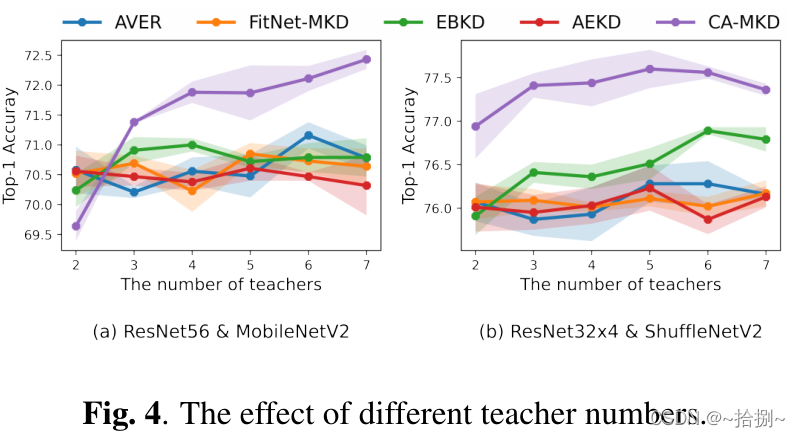
4.3 教师人数的影响
如图4所示,使用CAMKD训练的学生模型通常会获得令人满意的结果。例如,在“ResNet56& MobileNetV2”设置下,CA-MKD的准确性随着教师人数的增加而不断提高,超过了有三名教师的竞争对手,即使这些竞争对手接受了更多教师的培训。
4.4 消融研究
我们将表4中的观察结果总结如下:
- 平均重量。简单地平均多个教师会导致1.67%的准确率下降,这证实了根据不同教师的具体素质对待他们的必要性。
- w/o L i n t e r L_{inter} Linter。当我们去掉方程式(7)时,精确度会显著降低,这表明中间层包含有用的蒸馏信息。
- w/o w i n t e r k w^k_{inter} winterk我们直接使用从最后一层获得的 w K D k w^k_{KD} wKDk来集成中间特征。较低的结果表明,为中间层设计单独的权重计算方法的好处。
总结
在这篇文章中,我们在多教师知识提炼的预测和中间特征上引入了信心感知机制。教师的信心是基于他们的预测或特征与每个训练样本的可靠性识别的基本真理标签之间的接近度来计算的。在标签的指导下,我们的技术有效地整合了来自多个教师的各种知识,用于学生培训。大量的实证结果表明,我们的方法在各种师生结构中都优于所有竞争对手。
附录
1. w i n t e r k w^k_{inter} winterk的详细描述
为了稳定知识转移过程,我们将学生设计成更专注于模仿具有相似特征空间的教师,而
w
i
n
t
e
r
k
w^k_{inter}
winterk实际上是一个相似性度量,表示教师分类器在学生特征空间中的可辨别性。
下面几段将进行更详细的讨论。如图5所示,属于1类和2类的样本分别被描绘为圆形和三角形。尽管教师1(图5(b)和教师2(图5(c)的决策面在各自的特征空间中正确地对这些样本进行了分类,但它们在学生特征空间中的可分辨性不同(图5(a))。
为了稳定整个知识传递过程,我们希望学生更加注意模仿具有相似特征空间的老师。从这个意义上说,我们得出结论,教师1更适合学生,因为其决策面在学生特征空间中的表现优于教师2,如图5(a)所示。
假设A、B、C点分别是学生、教师1和教师2特征空间中同一样本的提取特征。如果我们将学生特征(A点)从教师-1(B点)移向特征,学生自己的分类器将正确地对A点进行分类,只需轻微调整,甚至不需要调整。但如果我们将学生特征(A点)从教师2(C点)移向特征,学生将更难正确分类,这可能会中断学生分类器的训练,并减慢模型收敛速度。

图5. 教师1和教师2量词的比较
2.额外的数据集实验
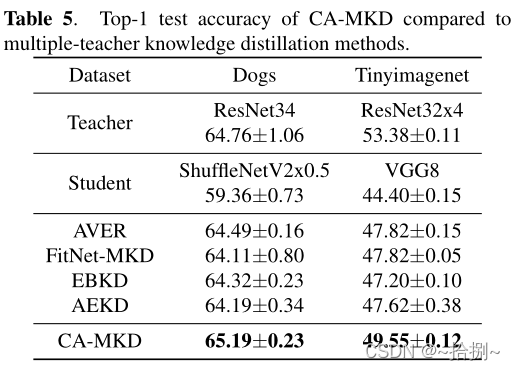
我们在狗和Tinyimagenet数据集上添加了更多实验,以进一步验证我们提出的CA-MKD的有效性。表5和表6显示,我们的CA-MKD能够在两个更具挑战性的数据集上持续超越所有竞争对手。
Tinyimagenet数据集的超参数与我们提交的CIFAR-100完全相同。另一个数据集(Dogs)包含高分辨率的细粒度图像,这需要不同的训练过程。我们遵循之前作品的背景[20]。















 748
748











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









