







从这一章开始进入正式的算法学习。
首先我们学习经典而有效的分类算法:决策树分类算法。
1、决策树算法
决策树用树形结构对样本的属性进行分类,是最直观的分类算法,而且也可以用于回归。不过对于一些特殊的逻辑分类会有困难。典型的如异或(XOR)逻辑,决策树并不擅长解决此类问题。
决策树的构建不是唯一的,遗憾的是最优决策树的构建属于NP问题。因此如何构建一棵好的决策树是研究的重点。
J. Ross Quinlan在1975提出将信息熵的概念引入决策树的构建,这就是鼎鼎大名的ID3算法。后续的C4.5, C5.0, CART等都是该方法的改进。
熵就是“无序,混乱”的程度。刚接触这个概念可能会有些迷惑。想快速了解如何用信息熵增益划分属性,可以参考这位兄弟的文章:http://blog.csdn.net/alvine008/article/details/37760639
如果还不理解,请看下面这个例子。
假设要构建这么一个自动选好苹果的决策树,简单起见,我只让他学习下面这4个样本:
样本 红 大 好苹果
0 1 1 1
1 1 0 1
2 0 1 0
3 0 0 0那么这个样本在分类前的信息熵就是S = -(1/2 * log(1/2) + 1/2 * log(1/2)) = 1。
信息熵为1表示当前处于最混乱,最无序的状态。
本例仅2个属性。那么很自然一共就只可能有2棵决策树,如下图所示:
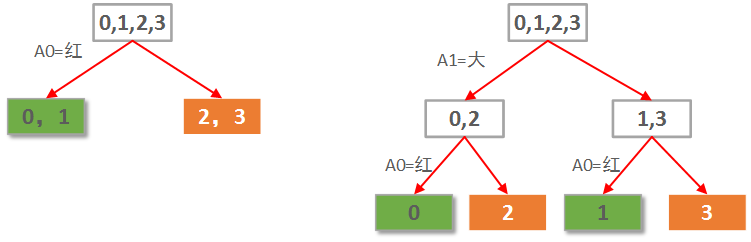
显然左边先使用A0(红色)做划分依据的决策树要优于右边用A1(大小)做划分依据的决策树。
当然这是直觉的认知。定量的考察,则需要计算每种划分情况的信息熵增益。
先选A0作划分,各子节点信息熵计算如下:
0,1叶子节点有2个正例,0个负例。信息熵为:e1 = -(2/2 * log(2/2) + 0/2 * log(0/2)) = 0。
2,3叶子节点有0个正例,2个负例。信息熵为:e2 = -(0/2 * log(0/2) + 2/2 * log(2/2)) = 0。
因此选择A0划分后的信息熵为每个子节点的信息熵所占比重的加权和:E = e1*2/4 + e2*2/4 = 0。
选择A0做划分的信息熵增益G(S, A0)=S - E = 1 - 0 = 1.
事实上,决策树叶子节点表示已经都属于相同类别,因此信息熵一定为0。
同样的,如果先选A1作划分,各子节点信息熵计算如下:
0,2子节点有1个正例,1个负例。信息熵为:e1 = -(1/2 * log(1/2) + 1/2 * log(1/2)) = 1。
1,3子节点有1个正例,1个负例。信息熵为:e2 = -(1/2 * log(1/2) + 1/2 * log(1/2)) = 1。
因此选择A1划分后的信息熵为每个子节点的信息熵所占比重的加权和:E = e1*2/4 + e2*2/4 = 1。也就是说分了跟没分一样!
选择A1做划分的信息熵增益G(S, A1)=S - E = 1 - 1 = 0.
因此,每次划分之前,我们只需要计算出信息熵增益最大的那种划分即可。
2、数据集
为方便讲解与理解,我们使用如下一个极其简单的测试数据集:
1.5 50 thin
1.5 60 fat
1.6 40 thin
1.6 60 fat
1.7 60 thin
1.7 80 fat
1.8 60 thin
1.8 90 fat
1.9 70 thin
1.9 80 fat我们的任务就是训练一个决策树分类器,输入身高和体重,分类器能给出这个人是胖子还是瘦子。
(数据是作者主观臆断,具有一定逻辑性,但请无视其合理性)
决策树对于“是非”的二值逻辑的分枝相当自然。而在本数据集中,身高与体重是连续值怎么办呢?
虽然麻烦一点,不过这也不是问题,只需要找到将这些连续值划分为不同区间的中间点,就转换成了二值逻辑问题。
本例决策树的任务是找到身高、体重中的一些临界值,按照大于或者小于这些临界值的逻辑将其样本两两分类,自顶向下构建决策树。
使用python的机器学习库,实现起来相当简单和优雅。
3、Python实现
Python代码实现如下:
# -*- coding: utf-8 -*-
import numpy as np
import scipy as sp
from sklearn import tree
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import classification_report
from sklearn.cross_validation import train_test_split
''' 数据读入 '''
data = []
labels = []
with open("data\\1.txt") as ifile:
for line in ifile:
tokens = line.strip().split(' ')
data.append([float(tk) for tk in tokens[:-1]])
labels.append(tokens[-1])
x = np.array(data)
labels = np.array(labels)
y = np.zeros(labels.shape)
''' 标签转换为0/1 '''
y[labels=='fat']=1
''' 拆分训练数据与测试数据 '''
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2)
''' 使用信息熵作为划分标准,对决策树进行训练 '''
clf = tree.DecisionTreeClassifier(criterion='entropy')
print(clf)
clf.fit(x_train, y_train)
''' 把决策树结构写入文件 '''
with open("tree.dot", 'w') as f:
f = tree.export_graphviz(clf, out_file=f)
''' 系数反映每个特征的影响力。越大表示该特征在分类中起到的作用越大 '''
print(clf.feature_importances_)
'''测试结果的打印'''
answer = clf.predict(x_train)
print(x_train)
print(answer)
print(y_train)
print(np.mean( answer == y_train))
'''准确率与召回率'''
precision, recall, thresholds = precision_recall_curve(y_train, clf.predict(x_train))
answer = clf.predict_proba(x)[:,1]
print(classification_report(y, answer, target_names = ['thin', 'fat']))
输出结果类似如下所示:
[ 0.2488562 0.7511438]
array([[ 1.6, 60. ],
[ 1.7, 60. ],
[ 1.9, 80. ],
[ 1.5, 50. ],
[ 1.6, 40. ],
[ 1.7, 80. ],
[ 1.8, 90. ],
[ 1.5, 60. ]])
array([ 1., 0., 1., 0., 0., 1., 1., 1.])
array([ 1., 0., 1., 0., 0., 1., 1., 1.])
1.0
thin 0.83 1.00 0.91 5
fat 1.00 0.80 0.89 5
avg / total 1.00 1.00 1.00 8
array([ 0., 1., 0., 1., 0., 1., 0., 1., 0., 0.])
array([ 0., 1., 0., 1., 0., 1., 0., 1., 0., 1.])
可以看到,对训练过的数据做测试,准确率是100%。但是最后将所有数据进行测试,会出现1个测试样本分类错误。
说明本例的决策树对训练集的规则吸收的很好,但是预测性稍微差点。
这里有3点需要说明,这在以后的机器学习中都会用到。
1、拆分训练数据与测试数据。
这样做是为了方便做交叉检验。交叉检验是为了充分测试分类器的稳定性。
代码中的0.2表示随机取20%的数据作为测试用。其余80%用于训练决策树。
也就是说10个样本中随机取8个训练。本文数据集小,这里的目的是可以看到由于取的训练数据随机,每次构建的决策树都不一样。
2、特征的不同影响因子。
样本的不同特征对分类的影响权重差异会很大。分类结束后看看每个样本对分类的影响度也是很重要的。
在本例中,身高的权重为0.25,体重为0.75,可以看到重量的重要性远远高于身高。对于胖瘦的判定而言,这也是相当符合逻辑的。
3、准确率与召回率。
这2个值是评判分类准确率的一个重要标准。比如代码的最后将所有10个样本输入分类器进行测试的结果:
测试结果:array([ 0., 1., 0., 1., 0., 1., 0., 1., 0., 0.])
真实结果:array([ 0., 1., 0., 1., 0., 1., 0., 1., 0., 1.])
分为thin的准确率为0.83。是因为分类器分出了6个thin,其中正确的有5个,因此分为thin的准确率为5/6=0.83。
分为thin的召回率为1.00。是因为数据集中共有5个thin,而分类器把他们都分对了(虽然把一个fat分成了thin!),召回率5/5=1。
分为fat的准确率为1.00。不再赘述。
分为fat的召回率为0.80。是因为数据集中共有5个fat,而分类器只分出了4个(把一个fat分成了thin!),召回率4/5=0.80。
很多时候,尤其是数据分类难度较大的情况,准确率与召回率往往是矛盾的。你可能需要根据你的需要找到最佳的一个平衡点。
比如本例中,你的目标是尽可能保证找出来的胖子是真胖子(准确率),还是保证尽可能找到更多的胖子(召回率)。
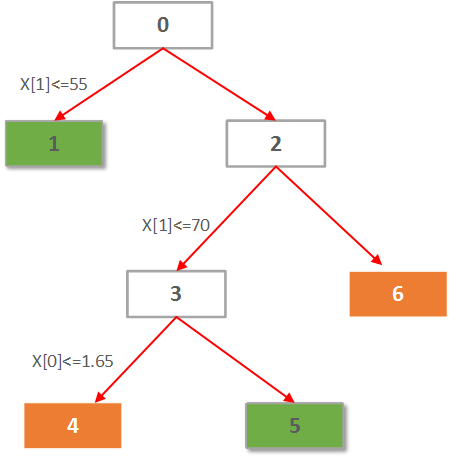
代码还把决策树的结构写入了tree.dot中。打开该文件,很容易画出决策树,还可以看到决策树的更多分类信息。
本文的tree.dot如下所示:
digraph Tree {
0 [label="X[1] <= 55.0000\nentropy = 0.954434002925\nsamples = 8", shape="box"] ;
1 [label="entropy = 0.0000\nsamples = 2\nvalue = [ 2. 0.]", shape="box"] ;
0 -> 1 ;
2 [label="X[1] <= 70.0000\nentropy = 0.650022421648\nsamples = 6", shape="box"] ;
0 -> 2 ;
3 [label="X[0] <= 1.6500\nentropy = 0.918295834054\nsamples = 3", shape="box"] ;
2 -> 3 ;
4 [label="entropy = 0.0000\nsamples = 2\nvalue = [ 0. 2.]", shape="box"] ;
3 -> 4 ;
5 [label="entropy = 0.0000\nsamples = 1\nvalue = [ 1. 0.]", shape="box"] ;
3 -> 5 ;
6 [label="entropy = 0.0000\nsamples = 3\nvalue = [ 0. 3.]", shape="box"] ;
2 -> 6 ;
}















 1131
1131

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









