








博文配套视频课程:24小时实现从零到AI人工智能
K-近邻算法介绍
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别
三维空间两点a(x1,y1,z1)与b(x2,y2,z2)间的欧氏距离, 欧式举例的本质就是如果两个样本之间的特征值越相邻,则值越小(距离越短)
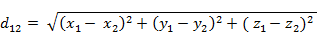
K近邻数据样本分析

K-近邻快速入门
通过此案例,理解训练集与测试集的使用,了解K-近邻API常用功能,并且掌握K超参数的意义
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import pandas as pd
# KNN 近邻 可以解决多分类问题 (逻辑回归是解决二分类问题)
# 思想简单,效果强大。
# 1: 数据获取 (爬虫,数据库,csv)
data = pd.read_csv('../data/movie.csv')
data.info()
# 2: 数据清理:缺省值、异常点、重复项
# 3: 特征工程 (删除无关特征, 数据标准化)
y = data['type']
X = data.drop(['type','name'],axis=1)
# 4: 获取训练集与数据集,指定random_state可以每次生成相同的值
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=1)
# 打印训练集的特征值与目标值
print(X_train)
print(y_train)
# 5:模型的选择
# 超参数设置:weight:距离的权重;uniform:一致的权重;distance:距离的倒数作为权重
knn = KNeighborsClassifier(n_neighbors=3,weights="distance")
knn.fit(X_train,y_train)
y_predict = knn.predict(X_test)
print('预测的结果为:', y_predict)
print('预测命中率为:',knn.score(X_test,y_test))
# 6: 模型的优化与使用: 交叉验证与网格搜索
# 7: 模型的保存与使用
















 1530
1530











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









