






 本文详细介绍了PCIe规范中的复位机制,包括传统复位(冷复位、暖复位)和功能级别复位(FLR)。传统复位由硬件处理,复位整个设备,而FLR允许软件针对性地复位设备中的某个功能,不影响其他共享链路的功能。FLR确保了数据安全性并提高了系统管理效率。
本文详细介绍了PCIe规范中的复位机制,包括传统复位(冷复位、暖复位)和功能级别复位(FLR)。传统复位由硬件处理,复位整个设备,而FLR允许软件针对性地复位设备中的某个功能,不影响其他共享链路的功能。FLR确保了数据安全性并提高了系统管理效率。
一、概述
PCIe规范描述了四种类型的复位机制。其中三个是PCIe规范早期版本的一部分,现在被统称为传统复位,当中的两个也被称为基本复位(CR,Conventional Resets)。第四个类别和方法是2.0规范修订版中添加的,称为功能级别复位(FLR,Function Level Reset)。
二、传统复位
1 基本复位
基本复位是由硬件处理,它复位整个设备,重新初始化每个状态机、所有硬件逻辑、端口状态及配置寄存器。该规则的例外是一组被标识为“sticky”的配置寄存器字段,除非所有的电源被移除,否则它们保留其内容。这使得它们对于诊断问题非常有用,而这些问题需要重置以使链路再次工作,因为错误状态在重置后仍然存在,而这些状态对软件可用。如果主电源被移除,但Vaux电源依旧可用,此时也将会保持sticky位,但如果主电源和Vaux电源都失去了,sticky位也将被重置。
基本复位通常发生在系统范围内的复位,但也可以对单个设备进行基本复位。
两种基本复位的类型:
(1)冷复位(Cold Reset):当设备的主电源打开时执行。循环使用电源会导致冷复位。
(2)暖复位(Warm Reset)(可选):在不关闭主电源的情况下,由系统专门的方式触发。例如,可以使用系统电源状态的更改来启动此操作。规范中没有定义生成Warm Reset的机制,由系统设计师自由选择实现。
定义了两种传递基本复位的方法。第一种可以由附加的称之为PERST# (PCI Express Reset)边际信号产生。第二种,当PERST#不提供给外接卡或组件时,当电源上电时,组件或外接卡自动完成基本复位。
1.1 PERST# 基本复位产生
中央资源设备例如PCIe系统的芯片组提供了这种复位。如图1所示,IO控制集线器 (ICH)芯片可以根据系统电源“POWERGOOD”信号的状态产生PERST#,因为这表明主电源已打开并稳定。如果电源被关闭,POWERGOOD切换并导致PERST#失信号,进而导致冷重启。系统还可以通过其他方式提供切换PERST#来完成热复位。
所有PCIe设备都需要将PERST#信号连接在主板上,包括连接器和图形控制器。设备可以选择使用PERST#,但并不要求这样做。PERST#也需要在PCIe转PCI-X桥之间进行连接。桥总是将主(上游)总线上的复位转发给次级(下游)总线,因此PCI-X总线会有RST#。
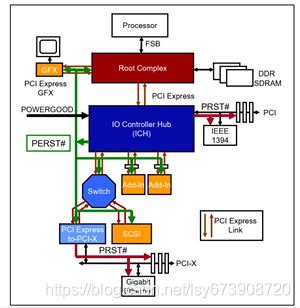 图1 PERST#产生示意图
图1 PERST#产生示意图
1.2 自主复位产生
当主电源上电时,设备需要实现自复位。规范中没有描述如何做到这一点,因此自复位机制可以设计到设备内部或者增加到外部逻辑中。例如,附加卡检测到上电,可以使用这个事件产生逻辑复位。如果检测到电源超出了指定的范围,设备还必须自动复位。
1.3 链路从L2低功率状态唤醒
举一个需要自动复位的场景。由于电源管理政策的因素,设备的主电源被关闭了,当它被设计为唤醒信号,那么其能够请求恢复到全功率。当电源恢复正常时,必须对设备进行复位。系统的电源控制器可以增加PERST#引脚到设备上,但如果设备不支持PERST#,当它感知到主电源重新上电时,设备必须自主完成基本复位。
2 热复位
热复位通过发送几个TS1s在相邻的链路里传递,这些TS1s带有声明符号5的0位,如图2所示。这些TS1s使用协商的链路和通道编号在所有的通道上发送,时间为2毫秒。一旦发送,热复位的发射器和接收器都将在检测LTSSM状态结束。
 图2 热复位为的TS1流程
图2 热复位为的TS1流程
热复位在软件中通过设置桥的桥控配置寄存器的次级总线复位位初始化。因此,只有包含桥的设备,如Root Complex或Switch,才能做到这一点。Switch接收到上游端口的热复位后,必须广播到所有下行端口并复位自己。Switch所有下游所有接收到热复位的设备将自动复位。
2.1 接收热复位的响应
(1)设备的LTSSM经过恢复和热复位状态后回到检测状态,此时将进行链路训练。
(2)所有设备的状态机,硬件逻辑,端口状态和配置寄存器(除了sticky寄存器)初始化为默认状态。
2.2 switch对下游端口进行热复位
当以下情况发生时,Switch将对所有下行端口进行热复位:
(1)接收到上游端口的热复位信号;
(2)对switch或桥的上游端口,如果数据链路层报告了DL_Down状态,其效果非常类似于热复位。由于物理层或者数据链路层的无法恢复的错误,当上游端口已经失去了和上游设备的连接时,就会发生这种情况。
(3)软件设置与上游端口相关桥控配置寄存器的“二级总线复位”位。
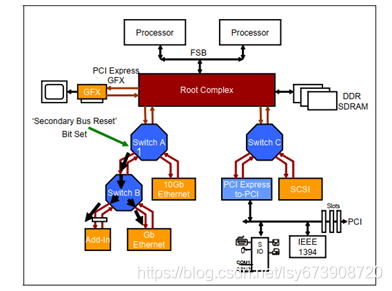 图3 switch对下游端口产生热复位示意图
图3 switch对下游端口产生热复位示意图
2.3 桥转发热复位到二级总线
如果一个桥接器(如PCIe to PCI(‐X)桥接器)在其上游端口检测到热复位,它必须assert其次级PCI(‐X)总线上的PRST#信号。
2.4 软件产生热复位
软件通过向相关端口配置头的桥控寄存器“二级总线复位”位上先写入0后写1,来产生特定端口的热复位,如图5所示。软件设置Switch A的左下游端口的“二级总线复位”寄存器,使其发送带有热复位位配置的TS1命令集。Switch B在其上行端口接收到此热复位,并将其转发到其所有下行端口。
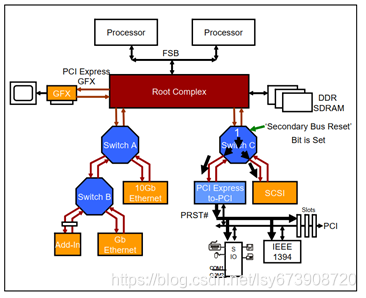 图4 switch对所有下游端口产生热复位示意图
图4 switch对所有下游端口产生热复位示意图
如果软件设置了switch的上行端口的二级总线复位位,则switch在其所有下行端口上产生热复位,如图4所示。在这里,软件设置在Switch C的上行端口的二级总线复位位,导致它发送TS1与设置在其所有下行端口的热复位位。PCIe转PCI桥接收到此热复位并通过assert PRST#将其转发到PCI总线。
设置二级总线复位位会导致端口的LTSSM转换到恢复状态,此时带有热复位位设置的TS1信号。TS1持续生成2毫秒,然后端口退出到检测状态,在此状态下可以开始链路训练。
热复位TS1(总是下游)的接收器也将进入恢复状态。当有两个连续的热复位位设置TS1信号时,会超时2ms进入热复位状态,然后退出到检测状态。上游和下游端口都被初始化,并以检测状态结束,准备开始链路训练。如果下游设备也是switch或桥,它也将热复位转发到其下游端口。
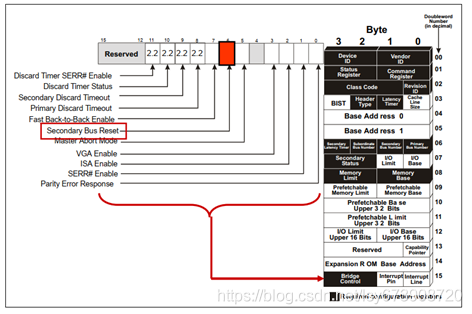 图5 产生热复位的二级总线复位寄存器
图5 产生热复位的二级总线复位寄存器
2.5 软件禁用链路
软件也可以禁用链路,迫使它进入闲置状态直到进一步通知。在这一点上提到的原因是,禁用链路也会导致下游组件的热复位。禁用是通过设置下游端口的链路控制寄存器中的链路禁用位来实现的,如图6所示。这将导致端口进入恢复LTSSM状态,并开始发送设置失效位的TS1。由于如果链路已被禁用,该位只能对下行端口进行控制,因此为上行端口保留该位(如端点或switch上行端口)。
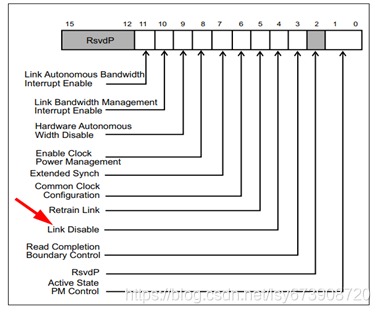 图6 链路控制寄存器
图6 链路控制寄存器
当上行端口识别到设置了失效位的TS1入站时,它的物理层信号LinkUp=0 (false)到链路层,所有的通道都进入空闲状态。在2ms超时后,上游端口将进入检测状态,但下游端口将保持在失效LTSSM状态,直到退出(例如清除链路失效位),所以链路将保持禁用,在此之前不会尝试训练。
 图7 禁用链路位TS1配置
图7 禁用链路位TS1配置
三、功能级别复位 (FLR)
FLR功能允许软件在一个多功能设备中只复位一个功能,而不影响所有功能共享的链路。强烈推荐实现,但不是必需的,因此软件在尝试使用它之前需要通过检查设备功能寄存器来确认它的可用性,如图8所示。如果设置了功能级复位的功能位,那么只需在设备控制寄存器中设置初始功能级复位位就可以启动功能级复位,如图9所示。
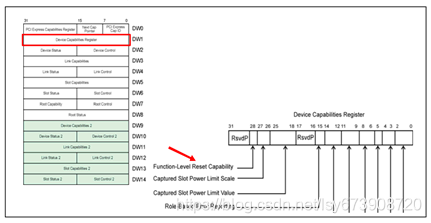 图8 功能级别复位的功能位
图8 功能级别复位的功能位
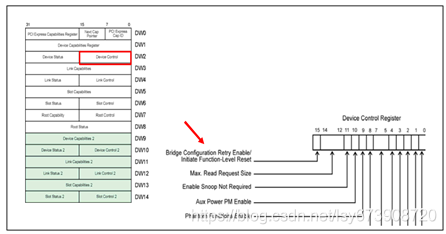 图9 功能级别复位初始化位
图9 功能级别复位初始化位
规范中提到了几个促使添加FLR的例子:
(1)控制功能的软件可能遇到问题,无法正常运行。防止数据损坏需要复位该功能,但如果该设备内的其他功能仍然正常工作,最好能够复位有问题的那个。
(2)在虚拟化环境中,应用程序可以从一个硬件迁移到另一个硬件。重要的是,当应用程序从一个功能移出时,功能不保留关于自己正在做什么的任何信息。这可以防止应用程序使用的信息被认为是机密的,而被运行在该功能上的新应用程序看到。迁移前一个应用程序后,最简单的清理方法就是复位功能。
(3)当软件为函数重新构建软件堆栈时,有时需要首先将函数置于未初始化状态。和前面一样,避免复位所有共享链路的函数是可取的。
另一个特性没有出现在规范的案例列表中,但它本身仍然是一个激励因素。虽然传统的复位将重新初始化设备内部的一切,但它不要求所有外部活动,如网络接口上的流量,必须立即停止。FLR添加了这个需求,并且只有复位才能满足这个需求。
FLR复位了功能的内部状态和寄存器,使其处于静止状态,但不影响任何sticky位,或硬件初始化位,或链路特定的寄存器,如捕获功率、ASPM控制、最大载荷大小或虚拟通道寄存器。如果发送了一个未完成的断言 INTx中断消息,则必须发送一个相应的解断言INTx消息,除非该中断被内部另一个仍然断言的功能共享。当收到FLR时,该功能的所有外部活动都需要停止。
1 时间要求
必须在100ms内完成FLR的操作。然而,如果有任何尚未返回的分割完成(通过在设备状态寄存器中保持设置的事务挂起位来表示),软件可能需要延迟启动FLR。在这种情况下,软件必须要么等待他们完成后才启动FLR,要么等待FLR后100ms再尝试重新初始化功能。如果此事不进行管理,就会出现潜在的数据损坏问题:功能可能分割了未完成的事务,但复位会导致失去对这些事务的跟踪。如果稍后返回,它们可能会被误认为是对FLR以来发出的新请求的响应。为了避免这个问题,规范建议软件应该:
(1)与其他可能访问该功能的软件进行协调,以确保在FLR期间不会尝试访问。
(2)清除整个命令寄存器,从而使功能停止。
(3)通过轮询设备状态寄存器中的事务挂起位,确保之前请求的完成已经返回,直到它被清除或等待足够长的时间,以确保完成永远不会返回。多长时间才够呢?如果使用了完成超时,请在发送FLR之前等待超时时间。如果完成超时被禁用,那么至少等待100ms。
(4)启动FLR,等待100ms。
(5)设置功能的配置寄存器并使其正常运行。
当FLR完成时,无论时间如何,都必须清除事务挂起位。
2 FLR期间的行为
规范编写者选择用相当宽泛的术语来描述功能复位的行为,以便不排除设计师可能希望采取的任何内部步骤。规范中列出了以下行为:
(1)功能不能对外部接口呈现,即使是一个活跃主机的初始化适配器。设计规范中,这些步骤确保所有对外部接口的活动是禁止的。例如,网络适配器在此期间不能响应活跃主机的请求。
(2)功能不能保留任何软件可读状态,因为可能包括以前使用功能时遗留的秘密信息。例如,必须清除或随机化任何内部内存。
(3)下一个驱动程序需要正常配置功能。
(4)对于配置的写操作,功能必须要返回一个完成,否则导致FLR,然后启动FLR。
当FLR正在处理时:
(1)任何到达的请求都允许被安静地丢弃,不做任何记录并且不发任何错误信号。不过,流控必须更新以维持链路可操作。
(2)即将到来的完成可以被视为意外完成,或者不记录或不发出错误信号的情况下静默地丢弃它们。
(3)FLR本身必须在上述时间内完成,但之后的初始化可能需要更长的时间。如果配置请求在初始化完成之前进入,功能必须返回CRS(配置重试状态)状态的完成。一旦完成返回任何其他状态,CRS状态将不再合法,直到功能再次复位。
3 复位退出
退出复位状态后,链路训练和初始化必须在20毫秒内开始。设备可以在不同的时间退出复位状态,因为复位信号是异步的,但必须在此时间内开始训练。
为了允许复位组件执行内部初始化,系统软件必须在发起复位后等待至少100毫秒,之后才可以发送配置请求。如果软件等待100毫秒后向设备发起配置请求,但设备仍然没有完成自初始化,则返回CRS的完成状态。由于配置请求只能由CPU发起,所以完成将被返回到Root Complex。作为回应,Root可能会自动重新发出配置请求,或者让软件可以看到故障。该规范还指出,如果启用了CRS软件可见性,软件只能使用100ms的等待时间,否则可能导致长时间超时或处理器停机。
在设备在给出配置请求的响应之前,允许复位后有1秒(‐0%/+50%)的时间。因此,系统必须小心地等待很长时间,然后才决定无响应的设备是坏的。这个值是从PCI继承来的,造成这种长时间延迟的原因可能是一些设备将配置空间实现为本地内存,在配置软件可以正确地看到它之前,必须初始化配置空间。初始化可能涉及从慢速串行EEPROM中拷贝必要的信息,因此可能需要一些时间。

















 699
699

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









