







主要是引入了去噪(class、bbox重建)的辅助任务
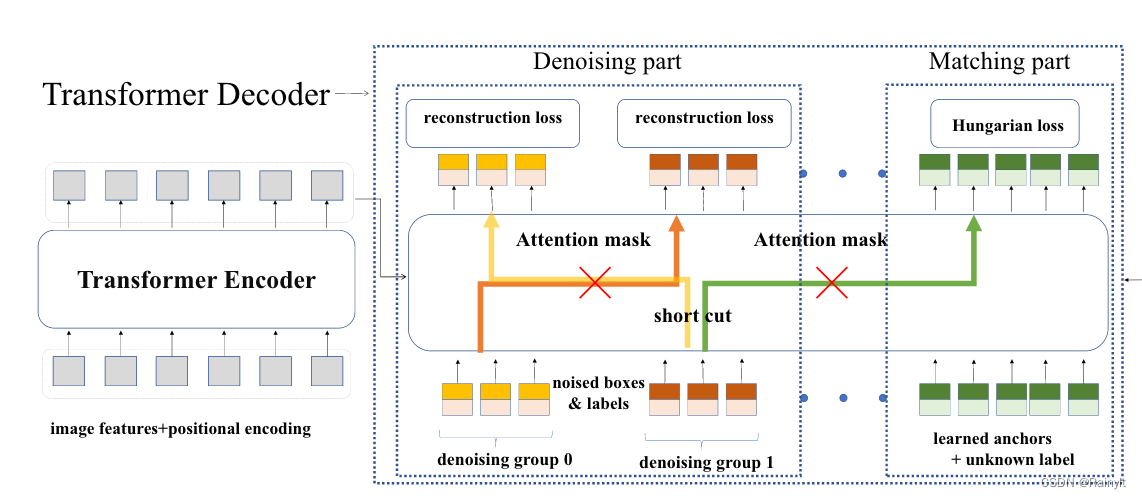
在Decoder部分,除了anchor的embedding,还加入了带噪声的bbox和class,比如gt_bbox
是(x, y, h, w),加噪声可以有很多种方式,比如变成
(
x
+
Δ
x
,
y
+
Δ
y
,
h
+
Δ
h
,
w
+
Δ
w
)
(x+\Delta{x}, y+\Delta{y}, h+\Delta{h}, w+\Delta{w})
(x+Δx,y+Δy,h+Δh,w+Δw),label加噪声的话就是随机变成别的class label,要求Decoder输出对应的GT bbox或者Class label。
每个group代表一种加噪声模式,每个group包含M个加噪声后的Query,M是这张图片上gt的数量
结果:加速训练50%,效果还是挺显著的。相当于对每个img引入了更多的sample/数据增强来增强对Decoder的训练,只是成本比较低















 632
632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









