







我们首先把Attention(Q, K, V)简单定义为(Q @ K.T) @ V,@为pytorch中的矩阵乘法
那么,若K = torch.cat((K1, K2)) V=torch.cat((V1, V2))
其中K1: [6, 128] K2: [7, 128] V1: [6, 128] V2:[7, 128]
那么则有(Q @ K.T) @ V = (Q @ K1.T) @ V1+ (Q @ K2.T)@ V2
如图所示:
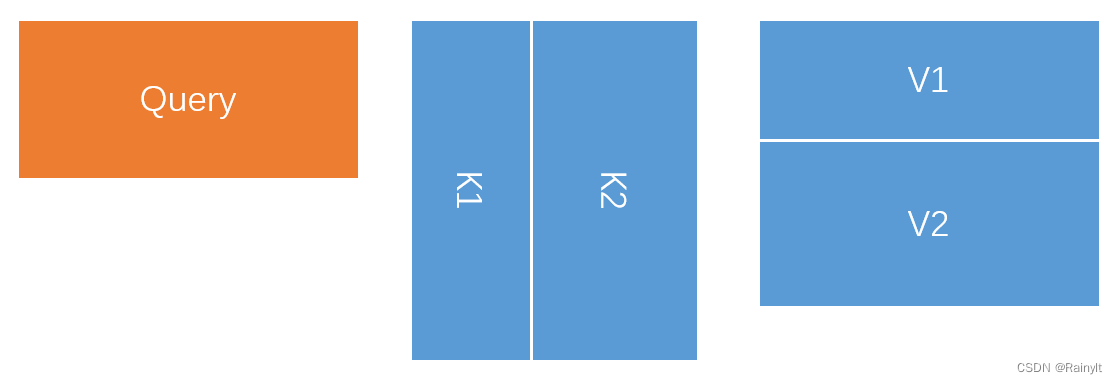
Q @ K.T @ V根据矩阵乘法的结合律可以等效为Q @ (K.T @ V)
由下图中可以看出,[K1, K2].T与[V1, V2]相乘==K1.T * V1 + K2.T * V2

所以
Q @ K.T @ V = Q @ (K1.T @ V1 + K2.T @ V2)
= Q @ K1.T @ V1 + Q @ K2.T @ V2
加上原本attention的softmax的话就是
Attention(Q, [K1, K2], [V1, V2]) = Softmax(Q @ [K1, K2].T) @ [V1, V2]
=(1-f(x))*Softmax(Q @ K1.T) @ V1 + f(x)*Softmax(Q @ K2.T) @ V2
其中,f(x)是为了将K1, K2拆开成两个softmax时产生的标量,详见TOWARDS A UNIFIED VIEW OF PARAMETER-EFFICIENT TRANSFER LEARNING (ICLR 2022)















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









