






AI大模型得到了前所未有的关注度与蓬勃发展,并在各类应用场景中产生了深远的影响。与之相应的是,对于高效、高可用的AI大模型推理系统的需求逐渐增长,成为许多企业的业务效率和成本挑战。
潞晨科技公司为此打造了高效易用的Colossal-Inference推理引擎,可显著提高AI大模型吞吐速度,以应对推理场景中的性能瓶颈和成本挑战。该推理引擎集成了分块显存管理与分页注意力算法,预设与自定义模型优化策略,连续批处理调度。预设中提供高性能手写算子, 第三方的算子加速库;而在预设之外,用户可以通过使用基础算子与模型层,自行搭建自定义模型优化策略,对指定模型进行优化。
GitHub开源地址:https://github.com/hpcaitech/ColossalAI/tree/main/colossalai/inference
性能对比
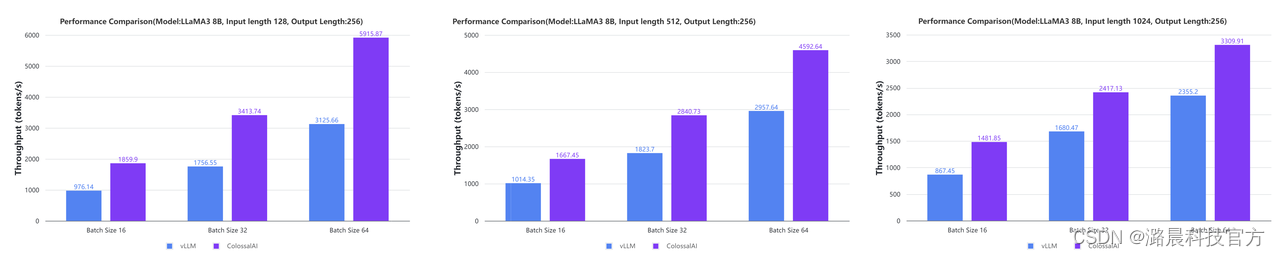
在NV H100 80GB SXM单卡上,对于LLaMA3 8B模型,与vLLM的离线推理性能相比,推理吞吐可至多提升近40%。
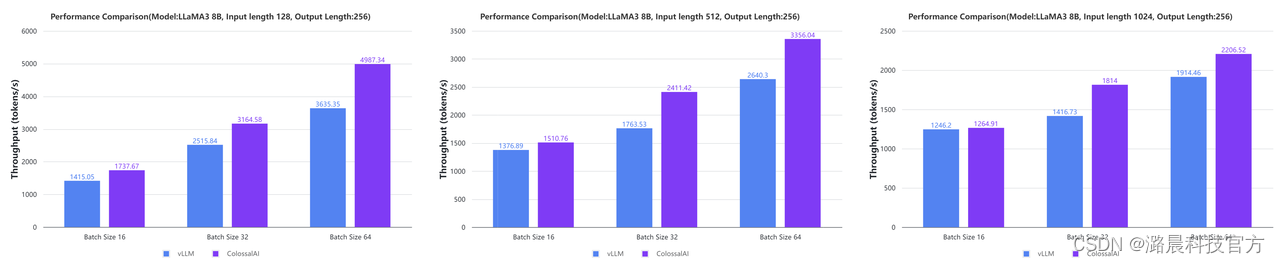
对于多卡并行推理,以NV H100 80GB SXM两卡张量并行为例,对于LLaMA3 8B模型,与vLLM的离线推理性能相比,部分情况下推理吞吐可接近翻倍提升。
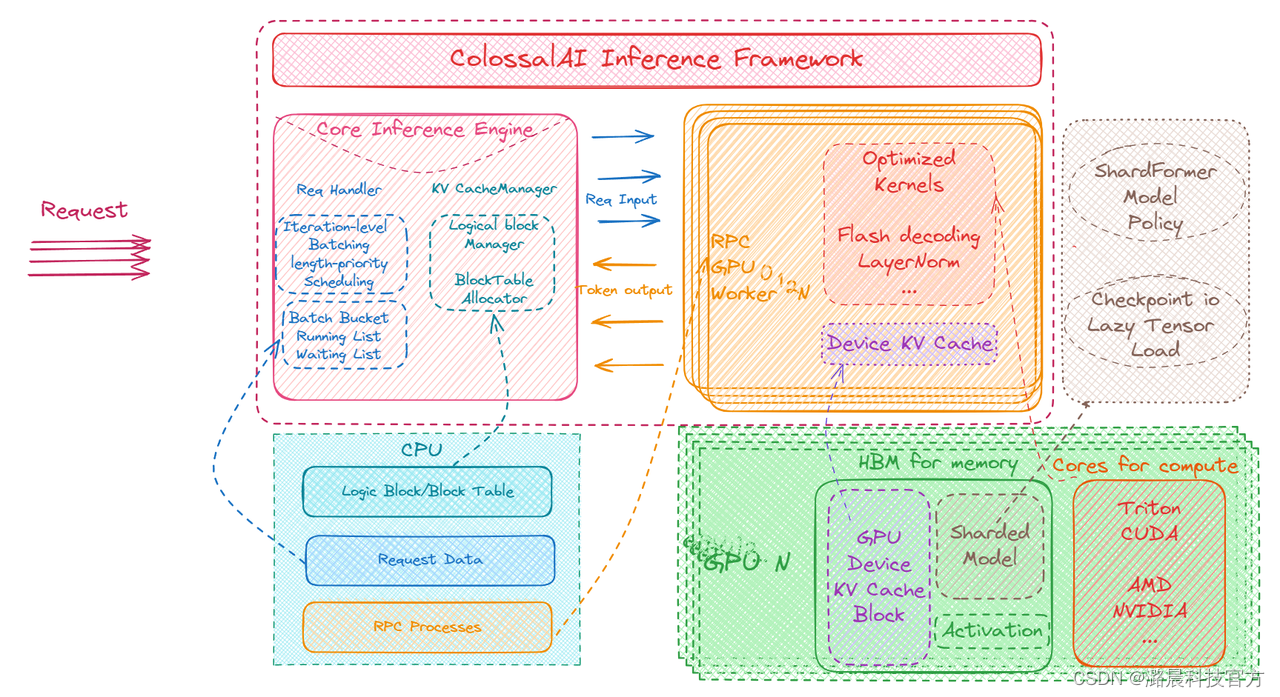
Colossal-Inference推理流程
推理引擎初始化
用户输入模型 (模型地址或HuggingFace Model Card) 与初始化配置,包括通用类型、推理引擎设置、多卡并行配置、功能配置和生成预设等。在推理引擎初始化过程中,输入模型会经由ColossalAI.ShardFormer进行切分和优化;针对多卡配置,模型将按照张量并行的方式分布到指定的卡上。而自定义优化算子可以通过ColossalAI.Extension模块引入。完成切分优化后,推理引擎保留优化后的模型。同时,系统在设备上预先分配激活缓存,初始化请求调度器、KV缓存管理器、及其他功能组件。
https://n4fyd3ptax.feishu.cn/sync/MB3Fd0Sm3sVMdkb1yogc3b8rnxc
模型优化完成、等待接受请求状态
初始化完成后,系统进入等待接受用户请求的状态。当用户输入提示词,例如“夏季旅行去哪里”,推理引擎调度器会进行调度,使用优化后的模型进行推理。在此过程中,根据功能配置,系统会选择性执行如KVCache量化和投机采样等组件模块。最后,系统将生成的结果返回给用户,例如“夏季旅行值得去的地方有承德避暑山庄、青岛、苏州等。其中,避暑山庄作为古典园林之一,融合了北方的宏伟气势和南方的秀丽景致,游览经典包括...” (文本生成举例)。
Colossal-Inference优化能力
在处理大语言模型推理任务时,推理系统面临着诸多挑战:包括但不限于计算资源消耗、用户等待时延过长、推理速度下降等。为了解决这些问题,我们期望一种更加高效与灵活的推理优化方法。这种方法期望针对不同类型的推理任务、不同类型的模型、和不同的硬件设备进行优化,以实现推理速度的显著提升和计算资源的有效利用。同时,推理优化方案还应该考虑到推理系统的可扩展性,在面对新出现的任务类型以及技术方法时能够高效进行组件添加,以及易用性,以便对于不断增长用户规模时确保用户方便使用。Colossal-Inference综合集成了以下诸多前沿技术。
张量并行 (Tensor Parallelism) 功能
结合Colossal-AI的shardformer 张量切分并行算法及ColossalAI.Shardformer组件,我们在模型初始化阶段对模型进行切分、模型层或模型层中使用的算子进行替换,替换为自定义的优化版本,并根据并行配置将切分的模型权重转移至相应设备。其中,自定义的优化算子使用CUDA,Triton进行实现,已适配下面提及的分块KV缓存,而自定义模型层使用Python进行组装,为用户提供了灵活性较高的自定义优化选项。
分块式KV缓存 (BlockedKeyValueCache)
受操作系统分页算法启发,分页注意力算法PagedAttention[1]将虚拟内存中的分页思想引入大语言模型的推理当中。我们针对用于大型语言模型的注意力机制部分算子应用了基于分块式KV缓存的分页注意力算法,实现高性能算子(CUDA/Triton)。该算法采用了分块式KV缓存,将每个序列的KV缓存分割成块,每个块包含固定数量的令牌的keys和values。在注意力计算中,PagedAttention算子(kernels)能够高效地识别并提取这些块。由于块不需要在内存中连续,我们可以灵活地管理keys和values,类似于操作系统的虚拟内存管理。连续逻辑块(logical blocks)通过块表映射到非连续的物理块(physical blocks)。随着新令牌的生成,物理块会按需分配。在此过程中,内存浪费主要发生在序列的最后一个块。这一设计接近最优的内存使用,提高了GPU利用率,从而显著提高了吞吐量。
KV缓存量化 (KVCache Quant)
在Decoder-Only的model下,通过对KV矩阵进行Cache的方式可以有效的减少冗余的KV矩阵计算,同时,考虑到Decoder结构下,KVCache相关的计算是一个GEMV的计算模式,属于Memory-Bound的性能问题,因此,通过用低bit的类型来进行KVCache的存储,进行Weight-Only的量化,可以有效的节省设备内存的同时,减少KVCache上下游Kernel的数据读写量,以进一步的提高模型吞吐。
以下图为例,在Colossal-Inference中,我们目前支持NV GPU下的FP8(E5M2) KVCache格式。以FP16的data flow为例子,kernel1在写入KVCache的时候,将FP16的输出Cast成FP8类型并存储在KVCache中,而kernel2读取KVCache时将FP8类型数据转回FP16进行计算,通过上述的方式,可以于KVCache上减少一半的设备内存占用。

投机采样 (Speculative decoding)
Colossal-Inference推理引擎支持投机采样:用户可选择性开启此组件、提供参数量较小的模型作为草稿用小模型 (Drafter Model) 进行投机推测,再使用优化后的大模型作为验证模型 (Verifier Model)进行多个令牌的同步验证。高灵活性的组件对接使用户可以选择随时开启和关闭投机采样而无需重新初始化引擎。此外,投机采样部分支持实现GliDe模型作为小模型,使用大模型 (验证模型) 的KV缓存参与交叉注意力[2]。使用gsm8k及mt-bench数据集benchmark,加速比达到1.5。
分页注意力算法 (PagedAttention)
在 Decode 阶段,Attention 计算因为 KVCache 的引入而转换为 Memory-Bound 的 GEMV 模式。在 ColossalAI 中,我们参考 vllm/FasterTransformer 实现高性能 PagedAttention 算子,采用特定形式的 Key Cache Layout([NUM_BLOCKS, NUM_KV_HEADS, HEAD_SIZE/X, BLOCK_SIZE, X])以优化 Attention 计算过程中的 shared memory 写入效率并配合相应的线程映射方式实现高效 reduce 计算。
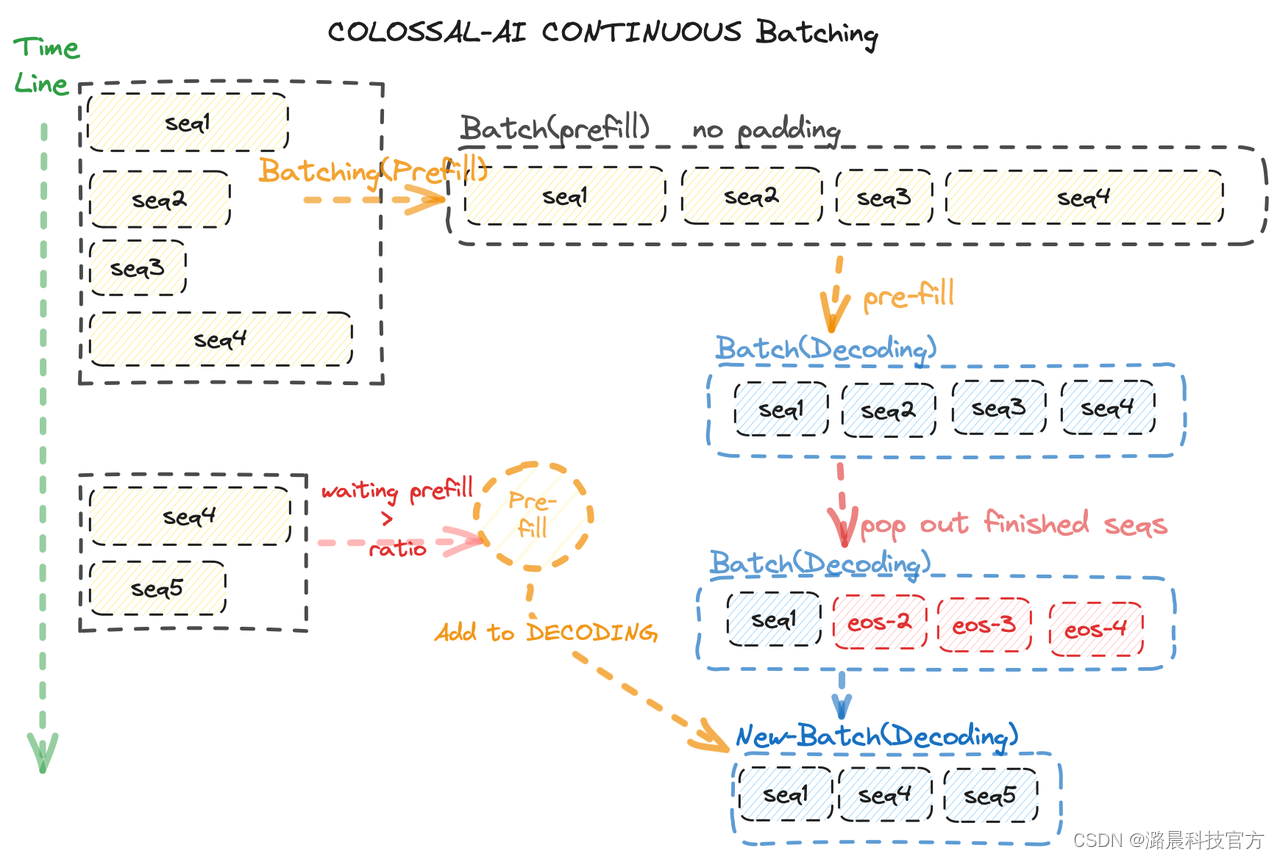
连续批量化算法(Continuous Batching)
现有的LLM在推理过程通常分为prefill阶段和decoding阶段。其中,prefill阶段使用输入的input_ids进行计算,推理出一个token并保存对应的key,value cacahe。decoding阶段则使用推理出的单个token和key,value cache进行推理。传统的推理方案不考虑二者的区分,批量处理也采用最直接的统一处理,通常会存在算力空置(idle)的问题。这一点在Orca[3]论文中也有说明。
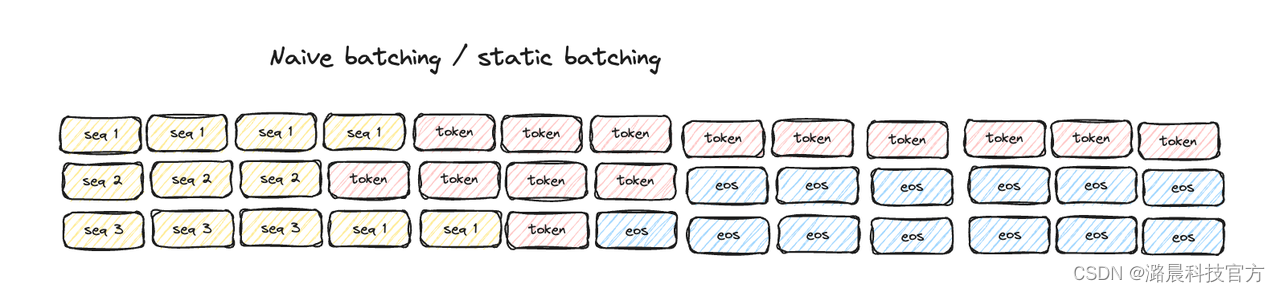
为了减少算力闲置,Continuous Bacthing算法被引入,目前最主流的做法有两种,一种是Orca的Selective-Batching方法,不区分prefill和decoding,在attention计算阶段将输入按照长度分开,不同长度的输入分批执行,其他算子则进行集合计算。另一种是vLLM的方法,在Batching时将prefill和decoding分开,prefill阶段针对长度不同的输入执行paddding操作,这样所有的算子均可以使用相同的batching逻辑。
Colossal-Inference系统吸收了两种不同方法的优点,我们同样区分了prefill和decoding的计算,但无需进行额外的padding操作。Colossal-AI重构的nopadding算子可以直接处理一维输入。然而,由于prefill阶段输入的单个句子长度不一,计算量大,需要的时间长,因此规定了prefill-ratio,当需要进行prefill的输入达到一定比例时,进行一次prefill操作。这样保证了大部分时间内均执行高速decoding过程。
在线推理(Online Serving)
Colossal-Inference集成了以FastAPI为架构的在线推理服务模块,支持单句补全(completion)和多轮对话(chat)两类接口服务。使用Colossal-Inference提供的api_server模块,用户可以便捷地生成本地推理服务端
口,并利用Colossal-Inference后端高效执行推理任务。本地启动的server服务端口稳定性强,能够满足较大规模同时调用的需要。
潞晨云优质算力,百万补贴,开箱即用
体验AI大模型还需要有GPU算力支持。
潞晨云不仅提供了便捷易用的AI解决方案,还为力求为广大AI开发者和其他提供了随开随用的廉价算力:

现在潞晨云官方进行限时大额算力补贴,NVIDIA H800的租用价格,低至5.99元/卡/时;NVIDIA A800为3.99元/卡/时,4090甚至低至1.59元/卡/时。
平台上还支持快速简易部署Llama 3微调、训练、推理。
其中在64卡H100集群上,经过Colossal-AI优化,相比微软+英伟达方案,可提升LLaMA3 70B的训练性能近20%,Open-Sora也能玩转。
特别活动:
-
【百万补贴】优质线上算力资源百万补贴等你来薅,随开随用。
-
【企业认证】企业用户参与潞晨云企业认证可得500元代金券。
-
【分享有礼】:用户在社交媒体和专业论坛(如知乎、小红书、微博、CSDN等)上分享使用体验并加上“#潞晨云”,一次有效分享可得100元代金券。
-
【用户社群】:加入潞晨云用户群,专业工程师在线答疑,不定时发放特价资源、代金券等优惠活动。
潞晨云体验地址:https://cloud.luchentech.com/
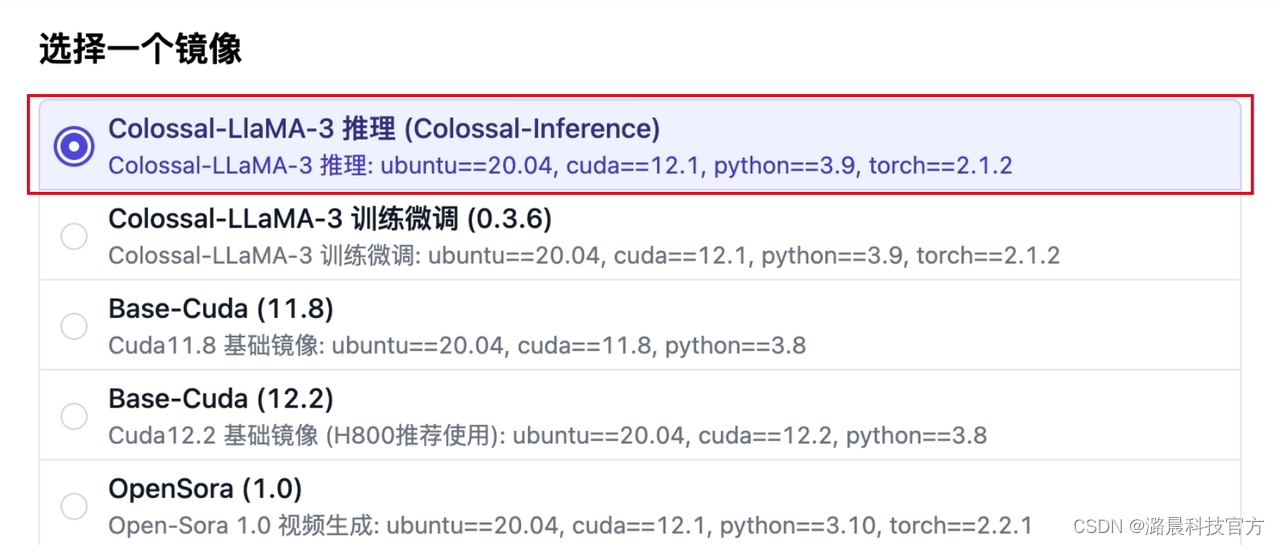
在潞晨云使用Colossal-Inference推理LLaMA-3
Colossal-Inference现已适配支持了LLaMA-3推理加速。在潞晨云,您可以选择推理镜像,使用Colossal-Inference进行推理优化提速,体验LLaMA-3的自然语言生成能力。
前期准备
LLaMA-3模型权重已准备好,无需额外安装步骤。
目前推理版本持续迭代中,您可以使用以下命令切换开发分支进行更新。
cd ColossalAI git checkout feature/colossal-infer git pull BUILD_EXT=1 pip install -v -e .
推理生成
运行生成脚本
PRETRAINED_MODEL_PATH="/root/notebook/common_data/Meta-Llama-3-8B" # huggingface or local model path cd ColossalAI/examples/inference/ colossalai run --nproc_per_node 1 llama_generation.py -m $PRETRAINED_MODEL_PATH --max_length 80
进行多卡TP推理,如下例使用两卡生成
colossalai run --nproc_per_node 2 llama_generation.py -m $PRETRAINED_MODEL_PATH --max_length 80 --tp_size 2
吞吐脚本
运行吞吐Benchmark测试
PRETRAINED_MODEL_PATH="/root/notebook/common_data/Meta-Llama-3-8B" git pull # update example benchmark from branch feature/colossal-infer cd ColossalAI/examples/inference/ python benchmark_llama3.py -m llama3-8b -b 32 -s 128 -o 256 -p $PRETRAINED_MODEL_PATH
潞晨云体验地址:https://cloud.luchentech.com/
Colossal-Inference GitHub 开源地址:https://github.com/hpcaitech/ColossalAI/tree/main/colossalai/inference
参考文献:
[1] Kwon, Woosuk, et al. "Efficient Memory Management for Large Language Model Serving with PagedAttention." arXiv preprint arXiv:2309.06180 (2023).
[2] Du, Cunxiao, et al. "GliDe with a CaPE: A Low-Hassle Method to Accelerate Speculative Decoding." arXiv preprint arXiv:2402.02082 (2024)
[3] Yu, Gyeong-In, et al. "Orca: A distributed serving system for {Transformer-Based} generative models." 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22). 2022.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









