







《【快捷部署】016_Ollama(CPU only版)》 介绍了如何一键快捷部署Ollama,今天就来看一下受欢迎的模型。
| 模型 | 简介 |
|---|---|
| gemma | Gemma是由谷歌及其DeepMind团队开发的一个新的开放模型。参数:2B(1.6GB)、7B(4.8GB) |
| llava | LLaVA是一种多模式模型,它结合了视觉编码器和Vicuna,用于通用视觉和语言理解,实现了模仿多模式GPT-4精神的令人印象深刻的聊天功能。参数:7B(4.7GB)、13B(8.0GB)、34B(20GB) |
| qwen | Qwen是阿里云基于transformer的一系列大型语言模型,在大量数据上进行预训练,包括网络文本、书籍、代码等。参数:0.5B、1.8B、4B (default)、7B、14B、 32B (new) 、 72B |
| llama2 | Llama 2由Meta Platforms发布。该模型默认情况下支持4096的上下文长度。Llama 2聊天模型根据超过100万条人工注释进行了微调,专为聊天而设计。参数:7B(3.8GB)、13B(7.4GB)、70B(39GB) |
| deepseek-coder | DeepSeek编码程序是从零开始训练的87%的代码和13%的英语和中文自然语言。每个模型都在2万亿个tokens上进行了预训练。参数:1.3B(0.8GB)、6.7B(3.8GB)、33B(19GB) |
| yi | 零一万物出品参数:6B(3.5GB)、34B(19GB) |
| phi | 由微软研究公司开发的2.7B语言模型,展示了卓越的推理和语言理解能力。参数:2.7B(1.6GB) |
| THUDM/GLM系列 | 智谱清言,https://chatglm.cn,知名的ChatGLM-6B、GLM-130B,以及最新的ChatGLM3-6B |
| nomic-embed-text | 大上下文嵌入模型 |
| grok-1 | Grok-1,马斯克xAI,314B,这个的使用门槛就比较高了。 |
点击模型文字,进入ollama library。选择对应的模型,就可以看到下载的命令。
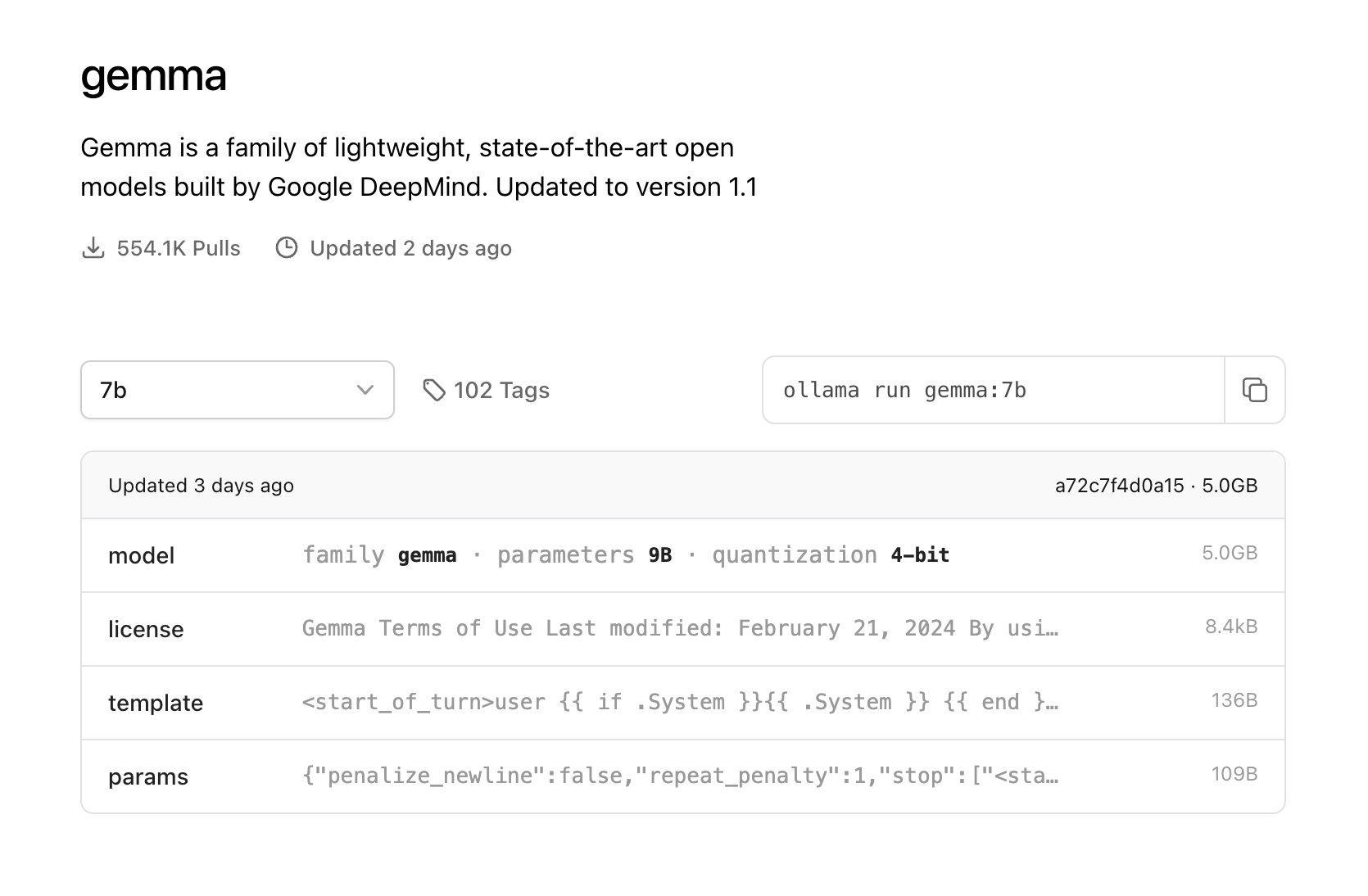
注意:运行7B模型至少需要8 GB RAM, 13B 模型至少需要16 GB RAM, 33B 需要 32 GB。
更多模型请参见:
https://ollama.com/library
https://huggingface.co/models
大模型榜单:https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
往期精彩内容推荐
👉 【快捷部署】016_Ollama(CPU only版)
👉 【快捷部署】015_Minio(latest)
👉 【快捷部署】014_elasticsearch(7.6)
👉 「快速部署」第一期清单
👉 云原生:5分钟了解一下Kubernetes是什么















 8767
8767











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









