









 本文介绍了如何在CentOS7环境中使用Docker快速部署Ollama应用,包括安装Docker、配置镜像、启动容器和加载大模型。同时提供了入门体验指南和注意事项,如网络带宽要求和GPU支持。
本文介绍了如何在CentOS7环境中使用Docker快速部署Ollama应用,包括安装Docker、配置镜像、启动容器和加载大模型。同时提供了入门体验指南和注意事项,如网络带宽要求和GPU支持。

📣【快捷部署系列】016期信息
| 编号 | 选型 | 版本 | 操作系统 | 部署形式 | 部署模式 | 复检时间 |
|---|---|---|---|---|---|---|
| 016 | Ollama(CPU only) | latest | CentOS 7.X | Docker | 单机 | 2024-04-10 |
注意事项:
1、目前镜像及大模型下载速度尚可,但由于容量较大,所以建议使用100Mbit/s以上的带宽。
2、2个容器镜像大小约为4G左右,大模型采用Gemma:9B,大约4.7G。
3、Ollama启动方式采用CPU only,由于没有GPU,所以运行速度较慢,建议采用16核以上的服务器。
4、为了降低入门体验门槛,所以规避掉了对于硬件GPU的要求,如想“顺滑”体验,还请使用带GPU的基础设施。
5、脚本部署过程,控制台会提示,输入内网IP地址,输入后才会继续执行,切勿一直等待。
6、本文脚本不适用于带GPU的设备,如有需要,请参见官网或关注后续博文。
一、快捷部署
#!/bin/bash
#################################################################################
# 作者:cxy@toctalk@hwy 2024-04-09
# 功能:自动部署Ollama(Docker方式)
# 说明:如果已安装了Docker,请注释掉 install_docker,避免重复安装
#################################################################################
info(){
echo -e "\033[34m 【`date '+%Y-%m-%d %H:%M:%S'`】\033[0m" "\033[35m$1\033[0m "
}
install_docker(){
#!/bin/bash
info "安装依赖..."
yum -y install gcc
yum -y install gcc-c++
##验证gcc版本
gcc -v
info "安装Docker(指定版本:23.0.6)"
wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O/etc/yum.repos.d/docker-ce.repo
##更新yum软件包索引
yum makecache fast
## 安装docker ce cli
# 查看可安装版本:yum list docker-ce --showduplicates | sort -r
yum -y install docker-ce-23.0.6-1.el7 docker-ce-cli-23.0.6-1.el7
info "启动Docker并验证"
systemctl enable docker && systemctl start docker
docker version
## 创建加速器
#cd /etc/docker
#if [ ! -f "$daemon.json" ]; then
# touch "$daemon.json"
#else
# rm -rf daemon.json
# touch "$daemon.json"
#fi
#tee /etc/docker/daemon.json <<-'EOF'
#{
# "registry-mirrors": ["https://自己的镜像加速器地址"]
#}
#EOF
#systemctl daemon-reload
#systemctl restart docker
info "Docker(23.0.6)安装完毕!"
}
# 安装 Ollama
install_Ollama(){
info "参考IP地址:"$(hostname -I)
read -p "请问,您当前服务器的内网IP地址是?:" inner_ip
inner_ip="${inner_ip:-127.0.0.1}"
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama --restart always ollama/ollama
info "ollama部署完毕,开始下载gemma大模型..."
docker exec -it ollama ollama run gemma “你好”
info "gemma大模型加载完成,开始部署webui界面..."
docker run -d -p 3000:8080 -e OLLAMA_BASE_URL=http://${inner_ip}:11434 -v open-webui:/app/backend/data --name open-webui --restart always ghcr.nju.edu.cn/open-webui/open-webui:main
eip=$(curl ifconfig.me/ip)
info "部署完毕,正在启动WEBUI界面,大约5分钟后,请访问:http://${eip}:3000"
}
install_docker
install_Ollama
使用方法:
$ vim install-ollama-centos7.sh
$ chmod +x install-ollama-centos7.sh
$ ./install-ollama-centos7.sh
# 感谢淘客科技提供的实验资源环境
验证:
1、docker ps (能看到2个容器实例正在运行)
2、浏览器访问:http://eip:3000 (需要等待WEBUI启动,并且放通了3000端口的访问规则)
# open-webui启动有些慢,通过日志查看进度
$ docker logs -f open-webui

二、入门体验
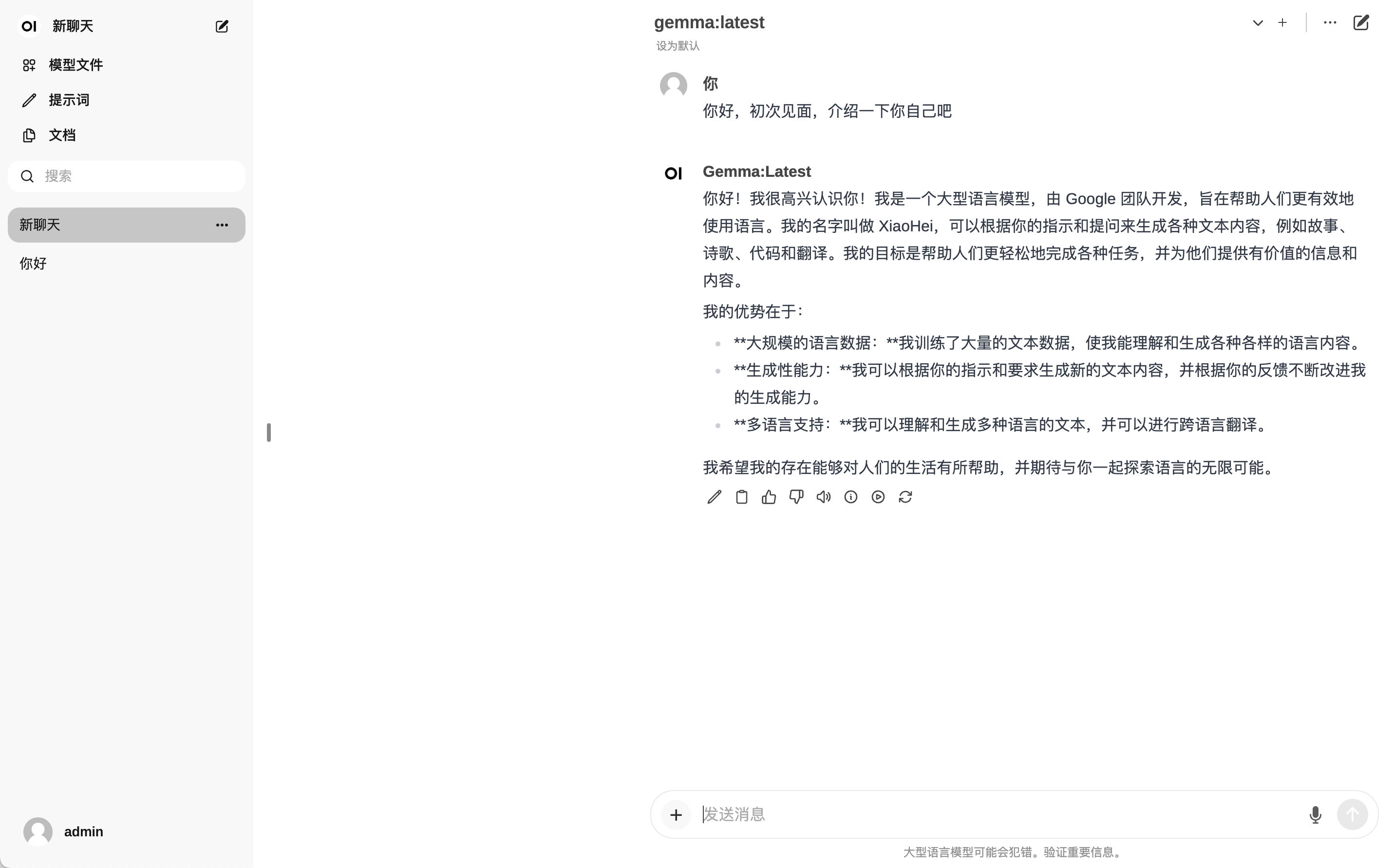
详细体验操作请观看后续相关视频
由于是入门系列,所以仅列举了简单的体验场景。
更多信息可访问官网:https://ollama.com
更多的模型:https://ollama.com/library
open-webui:https://github.com/open-webui/open-webui
当然,您也可以关注我,关注后续相关博文。
往期精彩内容推荐
云原生:5分钟了解一下Kubernetes是什么
【快捷部署】015_Minio(latest)
【快捷部署】014_elasticsearch(7.6)
【快捷部署】011_PostgreSQL(16)
【快捷部署】010_MySQL(5.7.27)
【快捷部署】009_Redis(6.2.14)
「快速部署」第一期清单

















 2997
2997

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









