






介绍
当前,人工智能大模型公司如雨后春笋般迅速涌现,例如 OpenAI、文心一言、通义千问等,它们提供了成熟的 API 调用服务。然而,随之而来的是不同公司的繁琐协议接入过程,这让许多开发者感到头疼不已。有没有一种统一的工具,能够让我们一次性接入所有公司的 API 协议,并且基于它们的底层能力封装出各种酷炫功能呢?今天,这样的工具终于来了——Langchain,它以坚实的步伐走来,为我们带来了极大的便利和创新。
Langchain 是一个专为适配各家大模型 API 而生的框架,不仅如此,它还封装了各种重要模块,使得大家能够轻松搭建出各种令人惊叹的人工智能应用。以下代码基于 langchain 2.0 版本实现
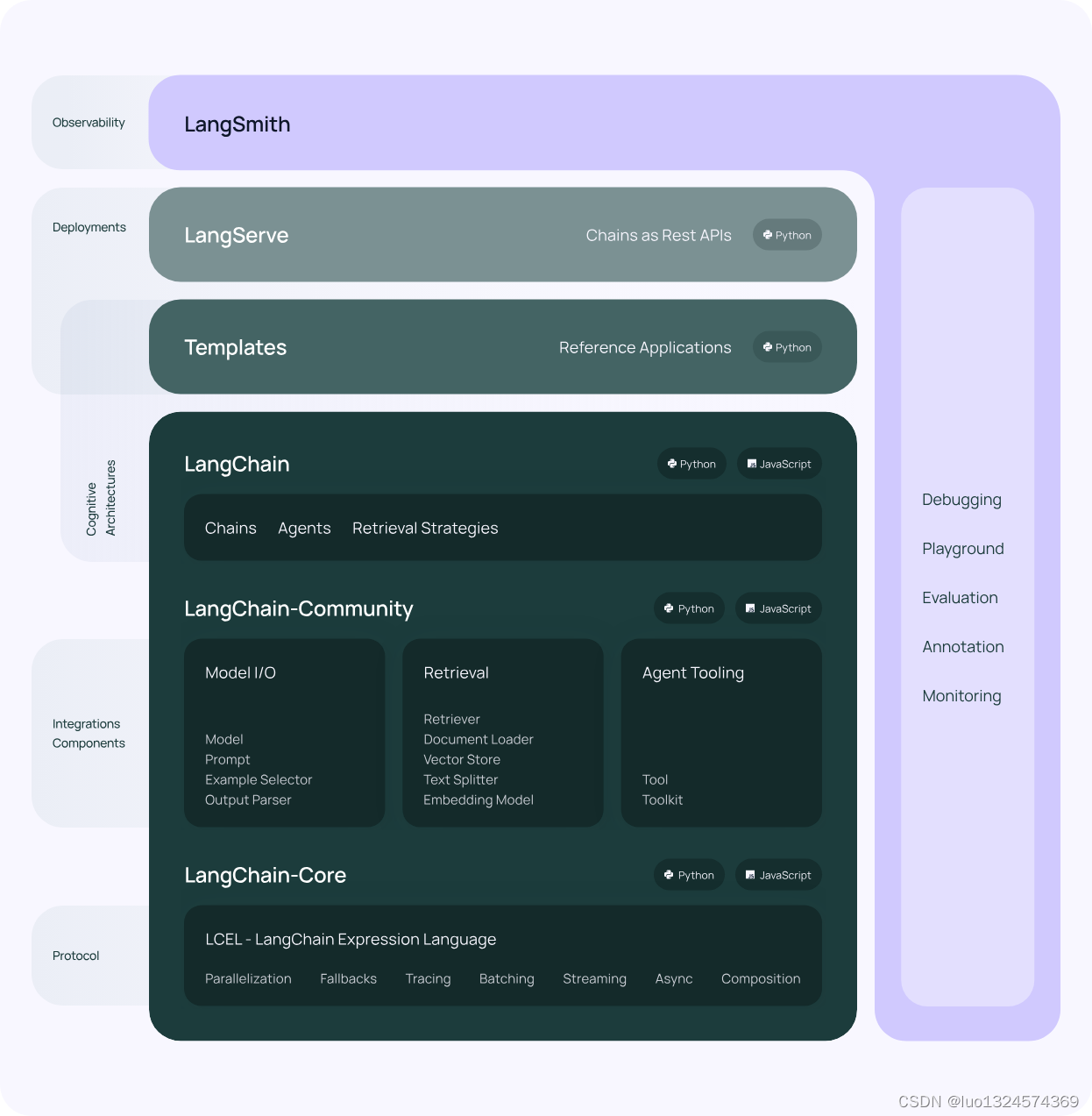
模块介绍:
-
Model: 这一模块的重要性不言而喻。Langchain 的 Model 模块致力于适配各大模型公司的接口协议,使得接入过程更加简单和高效。不再需要为每个公司的特殊协议而烦恼,Langchain 帮助您一次性搞定。
-
Prompt: 提示词的运用是大模型输出准确性的关键。Langchain 的 Prompt 模块不仅让大模型能更准确地输出我们期望的回答,还衍生出了“提示工程”。建议在使用大模型之前先查看提示工程,以获得更好的结果和体验。
-
History: 大模型本身并不具备记忆功能,这带来了一个看似矛盾的问题:为什么像 ChatGPT 这样的模型能够联系到我们之前的提问并给出相关回复呢?Langchain 的 History 模块揭示了这个谜团的解答。其实,实现原理非常简单,只需将你的上一个提问一并发送给大模型即可。当然,实际实现中还涉及一些问题,比如如何标识同一轮对话、信息存储位置、处理过多文本等等。因此,需要自行实现部分逻辑,但 Langchain 为您提供了思路和基础。
言归正传,让我们开始实战代码,探索 Langchain 带来的无限可能吧!
快速开始
1. 先安装依赖,以openai为例
pip install langchain
pip install -qU langchain-openai2. 初始化model
import os
os.environ["OPENAI_API_KEY"] = "sk-xxx"
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-3.5-turbo")3. 发起请求
from langchain_core.messages import HumanMessage
response = model.invoke([HumanMessage(content="你好")])
response.content4.得到回答
'你好!有什么可以帮助你的吗?'🎉 恭喜你,你已经可以成功使用langchain调用大模型api了
加入历史记忆实现连续对话
经过以上步骤,你已经可以跟大模型进行聊天,但是有个问题,现在他是不会记忆上一轮的回答的,你上一句问他东西,他转头就忘了,那该怎么办呢?那就给他加上历史记忆好了
# 没有 history memory
from langchain_core.messages import HumanMessage
question_1 = "你好,我叫小明"
result_1 = model.invoke([HumanMessage(content=f"{question_1}")])
print(result_1.content)
question_2 = "我叫什么名字"
result_2 = model.invoke([HumanMessage(content=f"{question_2}")])
print(result_2.content)返回结果
你好,小明!有什么可以帮助你的吗?
抱歉,我无法回答这个问题,因为我不知道您的名字。您可以告诉我您的名字吗?我会很高兴称呼您的名字。开头也说了,大模型是没有记忆功能的,目前业界的实现方式都是通过各自实现存储,在聊天中将上一轮的问答也一起发送过去,让大模型有了“记忆”,那最简单的方法就是用个list存储,然后每次回答都带上去就好了
# 简单实现 history memory
from langchain_core.messages import HumanMessage
store = []
question_1 = "你好,我叫小明"
result_1 = model.invoke([HumanMessage(content=f"{question_1}")])
print(result_1.content)
store.append({"human": question_1, "ai": result_1.content})
question_2 = "我叫什么名字"
result_2 = model.invoke([HumanMessage(content=f"history: {store} {question_2} ")])
print(result_2.content)返回结果:
你好,小明!有什么可以帮助你的吗?
你的名字是小明。有什么可以帮助你的吗?如果有任何问题,随时问我吧!神奇的事情发生了,大模型有“记忆”了
当然,langchain也为我们提供了方便的实现,让我们不用显式的写history
pip install langchain_community# 使用官方模块实现
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
store = {}
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
with_message_history = RunnableWithMessageHistory(model, get_session_history)
config = {"configurable": {"session_id": "abc2"}}
question_1 = "你好,我叫小明"
result_1 = with_message_history.invoke([HumanMessage(content=f"{question_1}")],config=config)
print(result_1.content)
question_2 = "我叫什么名字"
result_2 = with_message_history.invoke([HumanMessage(content=f"{question_2}")],config=config)
print(result_2.content)你好小明,有什么可以帮助你的吗?
你告诉我你叫小明。同时langchain还提供了更多类型的memory实现,让我们可以使用redis去存储历史记录,这个就留给大家自己实现了 Redis | 🦜️🔗 LangChain
加入提示词prompt格式化回答
在上述的实现中,我们的做法就是简单的字符串拼接发送给大模型,使用prompt可以让我们更好的格式化我们的输入
# 加入prompt
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
store = {}
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"在每一句话结尾都加上 回复完毕",
),
MessagesPlaceholder(variable_name="messages"),
]
)
chain = prompt | model
with_message_history = RunnableWithMessageHistory(chain, get_session_history)
config = {"configurable": {"session_id": "abc2"}}
question_1 = "你好,我叫小明"
result_1 = with_message_history.invoke([HumanMessage(content=f"{question_1}")],config=config)
print(result_1.content)
question_2 = "我叫什么名字"
result_2 = with_message_history.invoke([HumanMessage(content=f"{question_2}")],config=config)
print(result_2.content)你好,小明。有什么可以帮助你的吗?回复完毕
您的名字是小明。回复完毕🎉 这样你就完成了一个能连续对话的ai机器人啦

















 750
750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









