







🧡🧡实验内容🧡🧡
用粒子群求解下列函数的最小值
f ( x ) = ∑ i = 1 D X i 2 4000 − ∏ i = 1 D cos ( X i i ) + 1 f(x) = \sum_{i=1}^{D} \frac{X_i^2}{4000} - \prod_{i=1}^{D} \cos \left( \frac{X_i}{\sqrt{i}} \right) + 1 f(x)=i=1∑D4000Xi2−i=1∏Dcos(iXi)+1
其中,D 为变量维度,x∈[-600,600],i=1,2,…,D
🧡🧡求解代码🧡🧡
import numpy as np
import matplotlib.pyplot as plt
def f(x):
D = len(x)
sum_1 = np.sum(x**2) / 4000
prod_2 = np.prod(np.cos(x / np.sqrt(np.arange(1, D + 1))))
return sum_1 + prod_2 + 1
def PSO(obj_func, dim, swarm_size, max_iter, lb, ub):
position = np.random.uniform(lb, ub, (swarm_size, dim)) # 粒子的初始位置
velocity = np.random.rand(swarm_size, dim) # 粒子的初始速度
p_best_pos = position.copy() # 粒子的历史最佳位置
p_best_val = np.zeros(swarm_size) # 粒子的历史最佳适应度值
g_best_pos = np.zeros(dim) # 种群的最佳位置
g_best_val = float('inf') # 种群的历史最佳适应度值
g_best_val_history = [] # 记录每一代种群的全局最优适应度值
for i in range(swarm_size):
p_best_val[i] = obj_func(position[i])
if p_best_val[i] < g_best_val:
g_best_val = p_best_val[i]
g_best_pos = p_best_pos[i]
for t in range(max_iter):
w = 0.8 # 惯性权重
c1 = 0 # 局部学习因子
c2 = 2 # 全局学习因子
# 更新粒子位置和速度
r1, r2 = np.random.rand(swarm_size, dim), np.random.rand(swarm_size, dim)
velocity = w * velocity + c1 * r1 * (p_best_pos - position) + c2 * r2 * (g_best_pos - position)
position = position + velocity
# 边界处理
position = np.clip(position, lb, ub)
# 更新个体和全局最佳位置
for i in range(swarm_size):
if obj_func(position[i]) < p_best_val[i]:
p_best_val[i] = obj_func(position[i])
p_best_pos[i] = position[i]
if p_best_val[i] < g_best_val:
g_best_val = p_best_val[i]
g_best_pos = p_best_pos[i]
# 记录全局最优适应度值
g_best_val_history.append(g_best_val)
return g_best_pos, g_best_val, g_best_val_history
# 设置参数
dim = 5 # 维度
swarm_size = 50 # 粒子群大小
max_iter = 100 # 最大迭代次数
lb = -600 # 下界
ub = 600 # 上界
# 求解
best_val_list=[]
val_history_=[]
for i in range(10):
best_pos, best_val, val_history = PSO(f, dim, swarm_size, max_iter, lb, ub)
best_val_list.append(best_val)
print("最优解:", best_pos)
print("最优值:", min(best_val_list))
print("平均最优值:", np.mean(best_val_list))
# 可视化适应度值随迭代次数的变化
plt.plot(range(max_iter), val_history)
plt.xlabel('Iteration')
plt.ylabel('g_best Fitness Value')
plt.title('PSO Fitness Curve')
plt.grid(True)
plt.show()
# 画三维图
# %matplotlib notebook # jupyter上选择3D图像
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
def f(x):
D = len(x)
sum_1 = np.sum(x**2) / 4000
prod_2 = np.prod(np.cos(x / np.sqrt(np.arange(1, D + 1))))
return sum_1 + prod_2 + 1
dot_cnt=100
lb=-5
ub=5
# 生成网格点
x1 = np.linspace(lb, ub, dot_cnt)
x2 = np.linspace(lb, ub, dot_cnt)
X1, X2 = np.meshgrid(x1, x2)
fx=[]
for i in range(len(X1)):
for j in range(len(X1[i])):
value1 = X1[i][j]
value2 = X2[i][j]
# print(value1, value2)
fx.append( f(np.array([value1,value2])) )
fx=np.array(fx)
fx=fx.reshape((100, 100))
# print(X1.shape)
# print(X2.shape)
# print(fx.shape)
# 绘制曲面图
fig = plt.figure()
ax = Axes3D(fig)
ax.plot_surface(X1, X2, fx, cmap=plt.cm.hot ) # 渐变颜色
ax.set_zlim(-2, 2)
# 设置坐标轴名称
ax.set_xlabel('X1')
ax.set_ylabel('X2')
ax.set_zlabel('f(x)')
ax.view_init(30, 120) # 设置可转动查看
plt.show()
🧡🧡分析结果🧡🧡
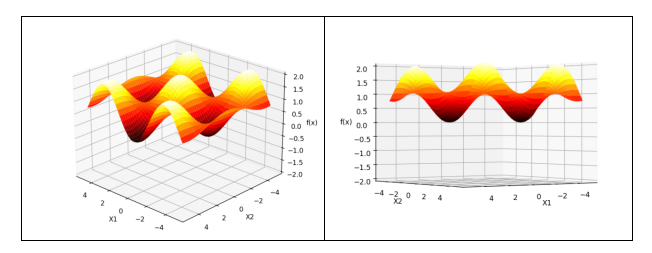
当D=2时,函数有两个变量x1,x2,画出它的三维图如下,显然当x1=x2=0时,函数取得最小值0,同理,易推导出D=n维时,x1=x2=…xn=0时,函数f(x)取得最小值
记录每一代种群的全局最优个体 g_best 的适应度值,使用 Matplotlib 可视化g_best 适应度值随种群迭代的变化曲线。理解并分析种群收敛过程
设置初始参数如下:
变量维度D=5
粒子群大小:50
迭代次数:100
惯性权重:w=0.8
学习因子:c1=1.5,c2=1.5
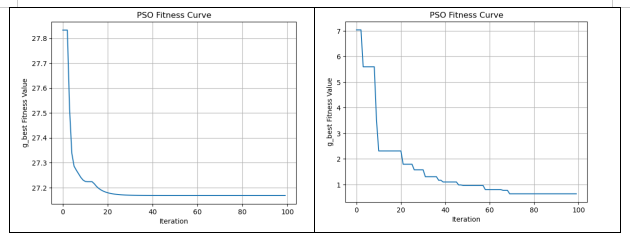
每一代种群的全局最优个体g_best适应度值如下图:
得到的最优解:[ 12.56616022 -4.18234793 5.39109688 -12.29064823 -7.0316828 ]
得到的最优值:0.12790639780782853分析可知:随着迭代次数增加,全局最优值逐渐收敛,可以认为此时种群已经收敛到一个较优解(已经非常接近理想解0了)。在每一代中,粒子群通过更新速度和位置,并比较当前粒子的适应度值与其历史最佳适应度值,更新个体最佳位置(p_best_pos)和全局最佳位置(g_best_pos)。同时,记录全局最优适应度值(g_best_val)的历史值(g_best_val_history)

设置不同的加速度常量,求得相应的最佳适应度和平均适应度,填入表 A.11,比较并分析 PSO社会模型、PSO 认知模型等对算法性能的影响
设置初始参数如下:
变量维度D=5
粒子群大小:50
迭代次数:100
惯性权重:w=0.8
学习因子:c1=1.5,c2=1.5
每一代种群的全局最优个体g_best适应度值如下图:
由上分析可知:
- 最佳适应度:
第一组实验中的最佳适应度为20.578505104664895,而第二组实验中的最佳适应度为0.2856117919216936。由此可见,在第一组实验中,通过只设置学习因子1的值,算法只能找到局部的最优值。而在第二组实验中,由于学习因子2的设置,算法更加注重全局搜索,从而得到了全局更小的最优值。- 平均适应度:
第一组实验中的平均适应度为31.520517352011513,而第二组实验中的平均适应度为0.4665058315655012。可以观察到,在第一组实验中,平均适应度较大,且与最优适应度距离较远,说明算法仅限于局部搜索,而每次程序都会随机初始化粒子群,导致每次程序运行得出的最优值有较大差别。在第二组实验中,平均适应度较小,全局搜索能力较强,能找到更小的最优值。- 迭代曲线图:
第一组实验中,由于只增加了局部学习因子1,因此算法很快进行了收敛,且收敛速度很快。而在第二组实验中,由于只增加了全局学习因子2,收敛速度较慢,且收敛的波动性较大。
PSO社会模型、PSO 认知模型等对算法性能的影响- PSO社会模型:
在社会模型中,粒子的运动受到整个群体的影响。每个粒子根据当前位置、速度以及群体中最好的解(全局最优解)来更新自己的速度和位置。社会模型强调了群体合作和信息共享的重要性。
影响:社会模型增强了全局搜索能力,使算法能够更好地找到全局最优解。通过引入全局最优解的信息,粒子能够跳出局部最优解,向更好的解决方案搜索。- PSO认知模型:
在认知模型中,粒子的运动受到个体经验的影响。每个粒子根据自身历史最好的解(局部最优解)来更新自己的速度和位置。认知模型强调了个体经验和自我调整的重要性。
影响:认知模型有助于加强局部搜索能力,使算法能够更快地收敛到局部最优解。通过利用个体的经验信息,粒子可以在局部最优解附近搜索,从而加快算法的收敛速度。
综上所述,PSO社会模型有助于全局搜索能力,帮助算法找到全局最优解;而PSO认知模型则有助于局部搜索能力,加快算法收敛到局部最优解。



🧡🧡实验总结🧡🧡
理论理解:
做实验之前,虽然早在数学建模比赛中偶有浅学一下,但对知识更多地停留在“怎么用”的层面,对于理论知识的了解还不够深刻,经过上网学习之后,发现其实是比较好理解的,总的来说就是对粒子进行局部和全局的速度向量进行更新,多个粒子逐步迭代,从而快速达到最优值。


结果思考:
通过实验设置粒子群基本参数,能达到很好的搜索效果,相比实验一中用遗传算法求解函数最值:
- 全局搜索能力:粒子群算法通常能够更快地收敛到全局最优解,因为每个粒子可以通过全局信息来指导搜索方向。而遗传算法可能需要更多的迭代次数才能达到全局最优解,因为其搜索过程更侧重于种群的遗传演化。
- 局部搜索能力:对于复杂的多峰函数(例如本实验的Rastrigin函数),遗传算法在搜索空间中更具有探索性,因为它能够保留多样性,有助于跳出局部最优解。而粒子群算法在局部搜索能力上相对较弱,容易陷入局部最优解。
- 参数设置上:粒子群算法相对少一些(主要是惯性权重、学习因子等),而遗传算法的性能跟许多参数相关(编码方式、选择方式、交叉变异方式等等)















 804
804











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









