






 文章详细解释了Linux中文件系统如何利用缓存提高读写性能,涉及sys_read/sys_write的处理过程,从磁盘直接读写到cache的利用,以及bio和request在硬盘I/O中的角色,展示了从用户空间到设备驱动层的交互机制。
文章详细解释了Linux中文件系统如何利用缓存提高读写性能,涉及sys_read/sys_write的处理过程,从磁盘直接读写到cache的利用,以及bio和request在硬盘I/O中的角色,展示了从用户空间到设备驱动层的交互机制。
写入到cache
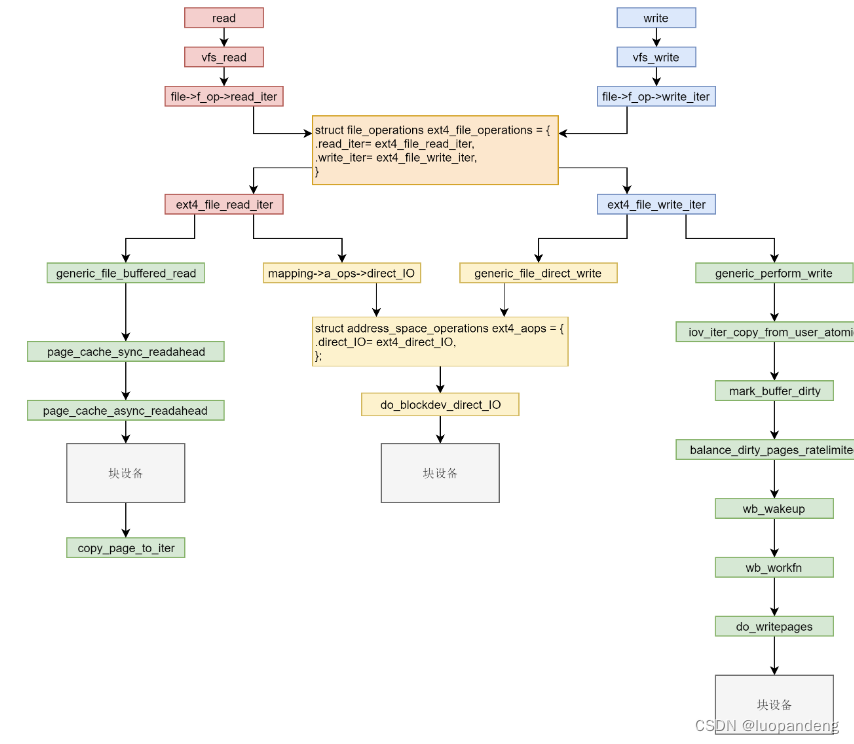
首先,打开一个文件,则会有一个 struct file结构,每个 struct file 结构都有一个 struct address_space 用于关联文件和内存,就是在这个结构里面,有一棵树,用于保存所有与这个文件相关的的缓存页。
sys_read/sys_write
vfs_read/vfs_write
file->f_op->read(ext4_file_operations..read_iter=ext4_file_read_iter ) 文件系统层
generic_file_read_iter
情况1:从磁盘读 iocb->ki_flags & IOCB_DIRECT
mapping->a_ops->direct_IO/ext4_direct_IO
(ext4_aops.direct_IO = ext4_direct_IO,) 文件 系统层,直接落盘
__blockdev_direct_IO->do_blockdev_direct_IO 设备驱动层
情况2:从cache读
generic_file_buffered_read 先找到 page cache 里面是否有缓存页,
page_cache_sync_readahead 如果没有找到缓存,不但读取这一页,
还要进行预读,调用设备驱动层,预读完了以后,再试一把查找缓存页,
应该能找到了
copy_page_to_iter 会将内容从内核缓存页拷贝到用户内存空间
file->f_op->write(ext4_file_operations..write_iter=ext4_file_write_iter ) 文件系统层
generic_file_write_iter
generic_file_direct_write 情况1:IOCB_DIRECT==1 直接写磁盘
generic_perform_write 情况2: 写到cache
ext4_aops.write_begin(address_space ext4_write_begin)
ext4_journal_start 记录日志
grab_cache_page_write_begin 根据pgoff_t index,在page_tree
中查找要写入的页,如果没有则创建缓存页
iov_iter_copy_from_user_atomic将用户态的数据拷贝到内核态
的页面的虚拟地址中
ext4_aops.write_end(address_space ext4_write_begin)
ext4_journal_stop
block_write_end->__block_commit_write->mark_buffer_dirty
将修改过的缓存标记为脏页,其实所谓的完成写入,并没有真
正写入硬盘,有一个问题,数据很危险,一旦宕机就没有了
balance_dirty_pages_ratelimited 检查脏页是否需要写入,
发现脏页的数目超过了规定的数目,则写入
balance_dirty_pages->wb_start_background_writeback 启动一个背
后线程开始回写,bdi_wq 是一个全局变量,所有回写的任务都挂在
这个队列上,每个块设备初始化块设备的时候,
调用 bdi_init 初始化这个结构,在初始化 bdi 的时候,
也会调用 wb_init 初始化bdi_writeback,初始化一个 timer,
也即定时器,到时候我们就执行wb_workfn,
wb_workfn->wb_do_writeback->wb_writeback->
writeback_sb_inodes
->__writeback_single_inode->do_writepages 调用设备驱动层
写入页面到硬盘,另外几种写回时机:用户主动调用 sync,当内存十分紧张,脏页已经更新了较长时间,
下面是图:
参考: 极客时间 趣谈Linux操作系统
从cache到bio
用于描述硬盘里面要真实操作的位置与page cache的页映射关系的数据结构是bio,bio里面会有一个bio_vec *bi_io_vec的表
如果我们要读 0~16KB数据:
第1种情况是在硬盘里面正好是顺序排列的,Linux会为这一次4页的读,
分配1个bio就足够了,并且让这个bio里面分配4个bi_io_vec,指向4个不同的内存页。
第2种情况是完全不连续的4块,Linux会为这一次4页的读,分配4个bio,
并且让这4个bio里面,每个分配1个bi_io_vec,指向4个不同的内存页面。
第3种情况,比如0~8KB在硬盘里面连续,8~16KB不连续。。。。
其他的情况请类似推理…完成这项工作的是mpage_readpages()。

mpage_readpages()会间接调用ext4_get_block(),真的搞清楚0~16KB的数据,在硬盘里面的摆列位置,并依据这个信息,转化出来一个个的bio。
bio到request
request代表对硬盘一段连续扇区的操作,包含一个bio链表,bio中包含bio_vec,内核会使用scatterlist来处理request.
1.原地蓄势
blk_queue_bio, 尝试把bio合并进入一个进程本地task_struct->plug list里面的一个request,如果无法合并,则造一个新的request。,把request放入进程本地的plug队列;蓄势多个request后,再进行泄洪。
2.电梯排序
进程本地的plug队列的request进入到电梯,进行再次的合并、排序,执行QoS的排队,之后按照QoS的结果,分发给块设备驱动。电梯内部的实现,可以有各种各样的队列。电梯入口:elevator_add_req_fn, 出口:elevator_dispatch_fn()
电梯调度里面也调度算法cfq, noop, deadline,比如CFQ调度算法,可以根据进程的ionice,调整不同进程访问硬盘的时候的优先级:
# ionice-c 2 -n 0 cat /dev/sda > /dev/null&
# ionice -c 2 -n 7 cat /dev/sda >/dev/null&
3.分发执行
电梯分发的request,被设备驱动的request_fn()挨个取出来,派发真正的硬件读写命令到硬盘。这个分发的队列,一般就是我们在块设备驱动里面见到的request_queue了。最终的完成一般是在另外一个上下文,而不是发起IO的进程,
探知到IO完成的上下文会以blk_end_request()的形式,通知等待IO请求完成的本进程。主动发起IO的进程的代码序列一般是:
- submit_bio()
- io_schedule(),放弃CPU。
blk_end_request()一般把io_schedule()后放弃CPU的进程唤醒。io_schedule()的这段等待时间,会计算到进程的iowait时间上。
参考:宋宝华: 文件读写(BIO)波澜壮阔的一生


















 1446
1446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











