







 本文介绍了一种应用于X光图像自动标注的方法,使用了Recurrent Neural Cascade模型。通过labelemining技术,解决了医学图像初始化模型缺乏的问题,并通过多次迭代提高了标注精度。
本文介绍了一种应用于X光图像自动标注的方法,使用了Recurrent Neural Cascade模型。通过labelemining技术,解决了医学图像初始化模型缺乏的问题,并通过多次迭代提高了标注精度。
今天读了一篇检测的文章,Learning to Read Chest X-Rays Recurrent Neural Cascade Model for Automated Image Annotation,发在 CVPR2016,作者不是太了解,据说Li Lu 在医学图像领域比较犀利。
Summary
这是篇文章属于“老方法+新问题”,其实也不算新问题,只不过用在医学图像里很少,我对医学图像处理并不太了解,说错了请见谅。
文章要解决的问题是类似于 image caption,不过应用在 X光图像上。模型并没有改进,但在训练策略上对医学图像处理做了适应。
Approach
和普通的 自然图像的image caption 的不同点在于,医学图像没有可用于 初始化的模型,imagenet 和医学图像的差别还是很大的。
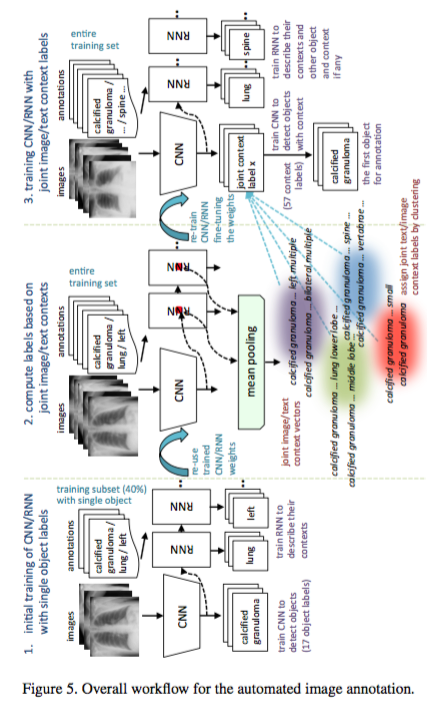
解决方案就是用医学图像训练一个 分类CNN作为初始化,但是这里的数据有些特殊,需要特别处理,具体是这样的:这里的图像是 X 光图像,每个图片都有对应的诊断报告,可以看成是多个描述,因此要首先解决图像的 label 的问题,也即 section 4所说的labele mining,具体做法是:找到17个高频label,并且每种label都含有超过30个 image,并且这17个 label下的图片 之间很少重复,因此就用这些图片构建一个分类数据库。
接着用 CNN 提出的feature 作为 RNN 的输入,接着是该图像对应的描述的输入,这个描述是用所谓的 MESH 处理过的,因此只是一些重要的词汇,并不是一个完整语义的句子。
然后将该图像在 RNN 模型中所有 t 时刻的 state vector 进行 mean pooling,得到一个平均表达,作为 image/text context,这个 context 的作用是对第一步的 CNN 模型进行细分,比如如下三个描述在第一次 CNN 是被认为是同一个 label,
“calcified granu- loma in right upper lobe”, “small calcified granuloma in left lung base”, and “multiple calcified granuloma”
现在就是想把他们区分开,就是利用 上面说到的context,对同一个 label 的 image 利用 context 再进行聚类,label 数目从17个扩大到57个,然后再训练,过程和上面一样。
流程图如下















 562
562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









