






AI时代的风口在哪里?
吴恩达认为,AI Agent将在今年推动人工智能的大规模进步。
——甚至,有可能超过下一代基础模型所带来的影响。
他希望所有从事人工智能工作的人,都能关注AI智能体的发展。

Andrew Ng
大佬「退役」后,作为专业的「教书先生」,仍然孜孜不倦,授业传道解惑。
最近在工作之余,吴恩达连续分享了很多关于智能体的见解,并定义了AI Agent的四大设计模式,

Reflection(反思)、Tool use(工具使用)、Planning(规划)和Multi-agent collaboration(多智能体协同):
-反思:LLM检查自己的工作,并提出改进的方法。
-工具使用:LLM利用Web搜索、代码执行或任何其他功能的工具,来帮助自己收集信息、采取行动或处理数据。
-规划:LLM提出并执行实现目标的多步骤计划(比如一篇论文,首先写大纲,然后搜索和研究各部分内容,再写草稿)。
-多智能体协作:多个AI agent协同工作,分工任务,讨论和辩论想法,提出比单个智能体更好的解决方案。
智能体工作流
我们大多数人使用LLM通常是zero-shot模式,模型根据提示逐个输出token,没有返回修改的机会。
——这相当于要求人类从头到尾一口气写完一篇文章,不允许回退,——尽管是个比较困难的要求,不过大模型们目前都做得非常出色。

但事实上,我们人类正常的工作流程一般是迭代式的。
比如对于一篇文章,可能需要:
计划一个大纲;通过网络搜索来收集更多信息;
写初稿;
通读初稿,发现不合理的论点或无关的信息;
反复修改…
这种工作模式对于人类写出好文章至关重要,——那么对于AI来说,是不是也应如此?
前段时间,世界上第一个AI程序员Devin的演示,在社交媒体上引起了轰动。
吴恩达团队于是研究了多个相关算法,在HumanEval编码基准测试中的表现,如下图所示:

在zero shot的情况下,GPT-3.5的正确率为48.1%,GPT-4的表现更好,达到67.0%。
然而,加入了迭代智能体工作流程之后,GPT-3.5的正确率直接飙到了95.1%,——Agent工作流效果显著,而且GPT-3.5比GPT-4得到的提升更加可观。
目前,各种开源智能体工具和相关研究的数量正在激增,擅于利用这些工具和经验,将使你的LLM更加强大。
Reflection
反思,作为容易迅速实现的一种设计模式,已经带来了令人惊讶的性能影响。

我们可能有过这样的经历:当LLM( ChatGPT/Claude/Gemini等)给出的结果不太令人满意时,我们可以提供一些反馈,通常LLM再次输出时,能够给出更好的响应。
——如果这个反馈的过程留给LLM自己执行,是不是会更好?这就是反思(Reflection)。
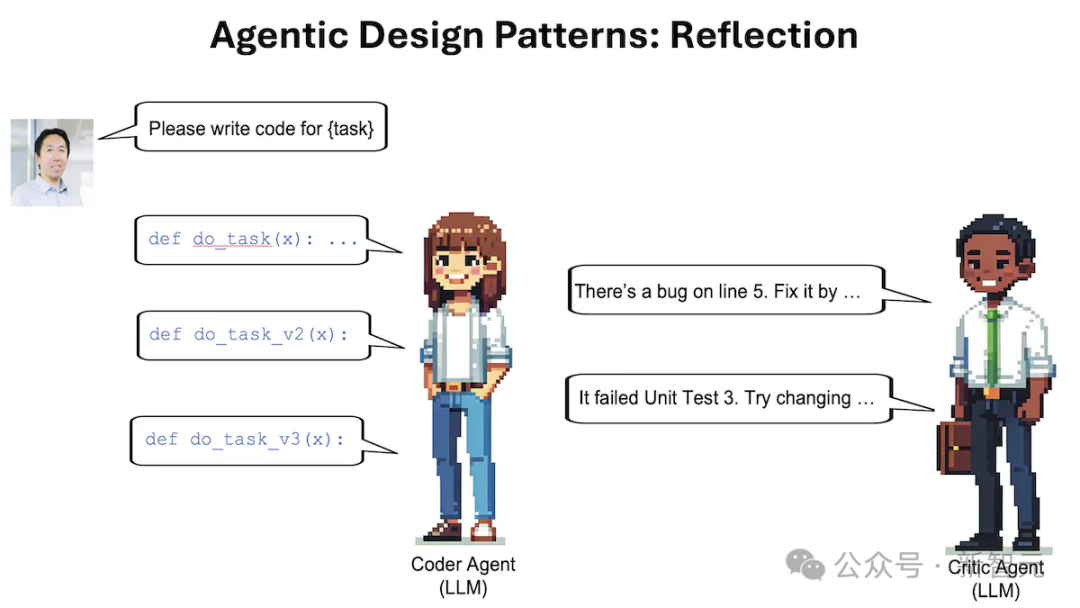
以编码任务为例,可以通过类似的提示,让LLM反思自己的输出:
这是用于任务 X 的代码,仔细检查代码的正确性、风格和效率,并就如何改进它提出建设性的批评。
接下来,将之前生成的代码和反馈放进提示的上下文,并要求LLM根据反馈重写代码。
当然,我们也可以利用一些评估LLM输出质量的工具,使上面这个过程更进一步,
比如通过单元测试检查代码在测试用例上的结果,或者通过web搜索来比对输出的正确性。
此外,也可以像上图那样,使用多智能体框架实现Reflection:一个负责生成输出,另一个负责对输出提出建议。
如果诸位对Reflection感兴趣,这里推荐下面几篇文章,可以提供更多相关的知识:

论文地址:https://arxiv.org/pdf/2303.17651.pdf

论文地址:https://arxiv.org/pdf/2303.11366.pdf

论文地址:https://arxiv.org/pdf/2305.11738.pdf
Tool Use
工具使用,LLM可以调用给定的函数,来收集信息、采取行动或操作数据,——这是AI智能体工作流的关键设计模式。
最常见的例子就是LLM可以使用工具,执行Web搜索或执行代码。事实上,一些面向消费者的大型公司已经采用了这些功能。
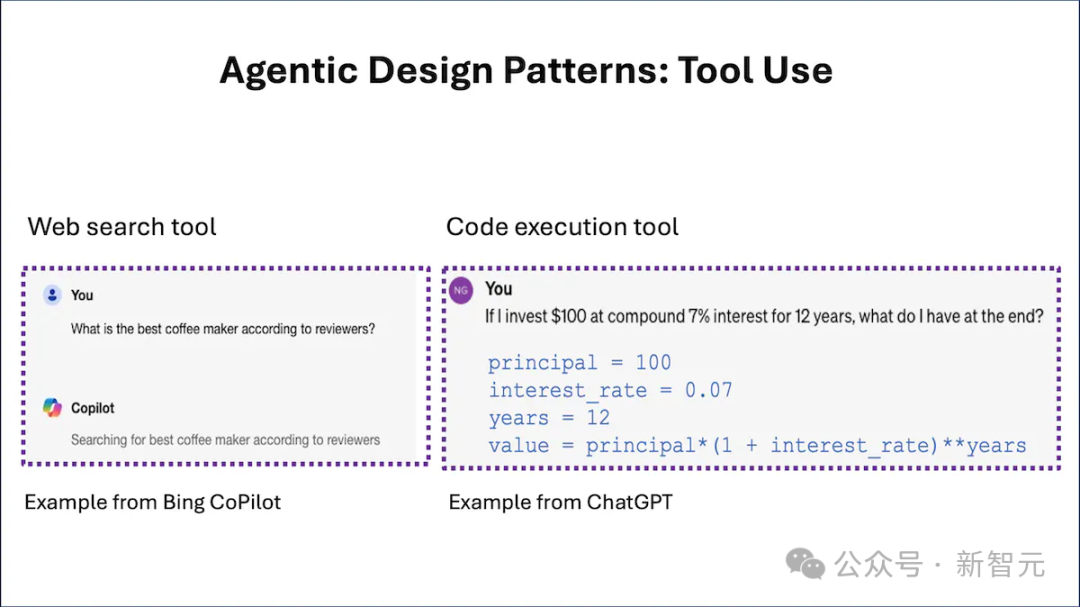
比如如果你问Copilot这样的在线LLM:「最好的咖啡机是哪一款?」,它可能会决定进行网络搜索,并下载一个或多个网页以获取上下文。
毕竟,仅依靠预训练的Transformer来生成输出答案是有局限性的,而提供Web搜索工具可以让LLM做更多的事情。
LLM使用特殊的字符串,例如 {tool:web-search,query:coffee maker reviews} ,以请求调用搜索引擎。
后处理步骤会查找字符串,调用具有相关参数的Web搜索函数,并将结果附加到输入上下文,传递回LLM。

再比如,如果你问,「如果我以12年复利7%,投资100美元,最后会获得多少收益?」,
LLM可能会使用代码执行工具,运行Python命令来计算:{tool:python-interpreter,code:100 *(1+0.07)**12}。
现在这个过程更近一步,我们可以搜索不同的来源(Web、Wikipedia、arXiv等),与各种生产力工具交互(发送电子邮件、读/写日历条目等),并且我们希望LLM自动选择正确的函数调用来完成工作。
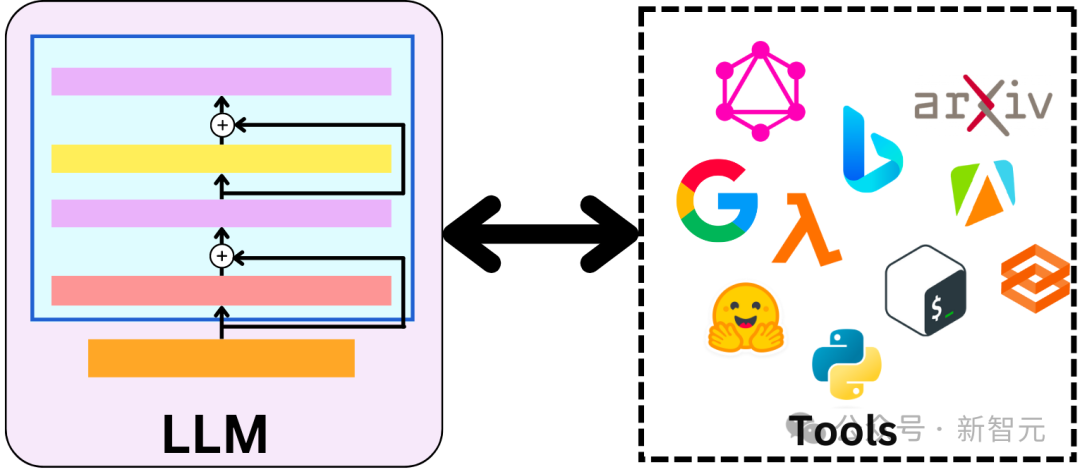
此外,当有太多函数可供使用时,无法将所有函数都放入上下文中,这时可以使用启发式方法,在当前处理步骤中选择要包含在LLM上下文中的最相关子集。
事实上,当有太多的文本无法作为上下文包含,检索增强生成(RAG)系统也是采用同样的方法,选择要包含的文本子集。
这里同样推荐几篇相关文章:

论文地址:https://arxiv.org/pdf/2305.15334.pdf

论文地址:https://arxiv.org/pdf/2303.11381.pdf

论文地址:https://arxiv.org/pdf/2401.17464.pdf
Planning
规划,使用LLM将目标任务分解为更小的子任务,然后自主决定执行的步骤。
例如,如果我们要求智能体对给定主题进行在线研究,LLM可以将其拆解为特定的子主题、综合发现、编写报告。
曾经,ChatGPT的发布让很多人经历了「ChatGPT时刻」,AI的能力大大超出了人们的预期。
——而类似的「AI Agent时刻」,也许很快就会到来。
吴恩达回忆了之前的一次现场展示,因为网速问题,Agent的Web搜索API返回了错误,——眼看就要被公开处刑,Agent居然转到了维基百科的搜索工具,最终完成了任务(救大命了)。
吴恩达表示,看到一个Agent以出人意料的方式执行任务,并获得成功,是一件美好的事情。
不过也有网友表示,大事不好啦,Agent失控啦!

现实中,有许多任务无法通过单个步骤或单个工具调用完成,但Agent可以决定要执行哪些步骤。
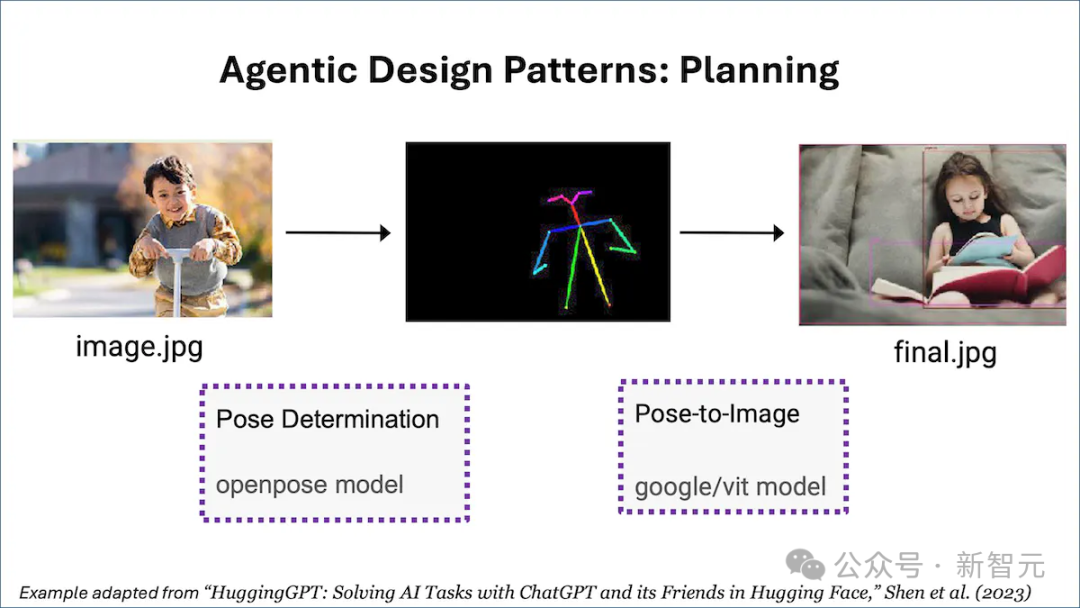
例如,要求智能体参照一张男孩的照片,画一张相同姿势的女孩的照片,则该任务可以分解为两个步骤:(i)检测男孩图片中的姿势,(ii)以检测到的姿势渲染女孩的图片。
LLM可能会通过输出类似 {tool:pose-detection,input:image.jpg,output:temp1 } {tool:pose-to-image,input:temp1,output:final.jpg} 这样的字符串来指定计划。
Planning是一种非常强大的能力,不过它也会导致难以预测的结果。
吴恩达表示Planning仍是一项不太成熟的技术,用户很难提前预测它会做什么,——不过我们可以期待技术的快速发展来解决这个问题。
这里同样推荐3篇相关的优秀工作:

论文地址:https://arxiv.org/pdf/2201.11903.pdf

论文地址:https://arxiv.org/pdf/2303.17580.pdf

论文地址:https://arxiv.org/pdf/2402.02716.pdf
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓















 2310
2310

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









