






大模型的微调有很多方法,所谓微调是指将一个已经过大规模预训练的模型(如Transformer-based的语言模型)调整以适应特定任务的过程。以下是几种常见的微调方法,每种方法各有特点,适用于不同的场景和资源限制:
-
全微调(Full Fine-tuning):
-
描述:这是最直接的微调方式,涉及到模型的所有参数都会被更新。预训练模型在特定任务的数据集上进行额外训练,通常采用较小的学习率来避免破坏预训练学到的知识。
-
优点:能充分适应新任务,通常可以获得最佳性能。
-
缺点:需要较多计算资源和时间,且可能会导致过拟合,尤其是当目标任务数据集较小时。
-
微调顶层(Top-Layer Fine-tuning):
-
描述:仅对模型的顶层(通常是输出层或最后一层)进行微调,保持其他层不变。
-
优点:计算成本低,速度快,因为大部分参数保持不变。
-
缺点:性能提升可能有限,对于需要模型深层次理解的任务效果不佳。
-
冻结底层(Freezing Lower Layers):
-
描述:冻结模型的底层(通常是靠近输入的层),仅微调顶层或部分高层。
-
优点:可以保留模型的通用知识,减少过拟合风险。
-
缺点:对任务特性的适应性不如全微调。
-
逐层微调(Layer-wise Fine-tuning):
-
描述:从模型的顶层开始,逐步向下逐层进行微调,每一层在前一层微调后的基础上进行调整。
-
优点:可以更好地平衡预训练知识与特定任务需求。
-
缺点:复杂度较高,需要仔细设计微调策略。
-
高效参数微调(Efficient Parameter Fine-tuning):
-
描述:引入少量额外参数或修改现有参数的子集来适应新任务,如LoRA (Low-Rank Adaptation)、适配器调整(Adapter Tuning)、前缀调整(Prefix Tuning)等。
-
优点:显著减少计算和内存需求,同时仍能保持较好的性能。
-
缺点:可能不如全微调精确,需要更精细的调参。
-
监督式微调(Supervised Fine-Tuning, SFT):
-
描述:使用人工标注的数据集进行传统的监督学习微调。
-
优点:直观且直接,易于理解和实施。
-
缺点:依赖大量高质量标注数据,成本高且某些领域获取困难。
-
基于人类反馈的强化学习微调(Reinforcement Learning with Human Feedback, RLHF):
-
描述:通过人类评价者的反馈作为奖励信号,指导模型的微调过程,如OpenAI的InstructGPT。
-
优点:能够优化模型生成的内容,使其更符合人类偏好。
-
缺点:过程复杂,需要设计有效的反馈收集和强化学习机制。
-
对齐微调(Aligned Fine-tuning):
-
特别提及于text-davinci-003等模型,目的是使模型的输出更加有帮助、真实和无害。
-
优点:提高模型输出的质量和可靠性。
-
缺点:需要精心设计的微调目标和评估标准。
选择哪种微调方法取决于具体任务的需求、可用资源、时间限制以及对模型性能的期望。在实际应用中,经常需要实验比较不同方法的效果,以确定最适合的微调策略。本节我们将重点介绍LoRa微调。
LoRa我们主要针对文章《LoRA: Low-Rank Adaptation Of Large Language Models》进行介绍。
LoRa 一文小结
-
背景与动机:随着transformer模型规模的不断扩大,它们在各种自然语言处理任务上的表现显著提升。然而,这些大模型的微调(fine-tuning)往往因计算成本高昂而受到限制,尤其是在资源有限或针对特定任务数据量较少的场景下。
-
LoRA方法介绍:
-
核心思想:LoRA提出了一种低秩分解(low-rank approximation)策略,通过在模型的每一层添加少量的可训练参数来实现微调,而不是调整所有参数。这些参数通过低秩矩阵来影响模型的线性变换,从而以较低的计算和内存开销达到对特定任务的适应。
-
技术细节:具体来说,LoRA为模型的权重矩阵引入了两个小的、低秩的矩阵A和B。在前向传播过程中,原权重矩阵W会与这两个矩阵进行矩阵乘法运算,形成一个调整后的权重矩阵,进而影响模型的输出。这种调整允许模型在不显著增加参数量的前提下快速适应新的任务。
-
优势:
-
资源效率:相比全微调,LoRA大幅减少了所需训练参数的数量,降低了内存占用和计算成本。
-
灵活性与扩展性:LoRA可以轻松应用于不同大小和结构的模型,并且对模型架构的改动较小,便于实施。
-
性能保持:尽管参数量减少,LoRA在多个NLP任务上仍然展现出了接近甚至达到全微调水平的性能。
-
实验与结果:文中通过广泛的实验验证了LoRA的有效性,包括在GLUE基准测试、SuperGLUE任务以及一些特定领域的任务上进行了评估。结果显示,LoRA不仅显著减少了训练时间和资源消耗,而且在许多任务上取得了与全微调相近甚至相当的性能表现。
-
结论:LoRA作为一种创新的微调策略,为大型语言模型的高效适应和部署提供了一条可行的道路,尤其是在资源受限的环境下。它的提出,对于促进大模型在实际应用中的普及和多样化使用具有重要意义。
1 ABSTRACT
自然语言处理的一个重要范式包括在通用领域数据上的大规模预训练以及对特定任务或领域的适应。随着我们预训练的模型规模越来越大,全量微调(即重新训练所有模型参数)变得不再可行。以GPT-3 175B为例——部署独立的微调模型实例,每个实例都有1750亿参数,成本高得令人望而却步。我们提出了一种名为低秩适应(LoRA)的方法,它冻结了预训练模型权重,并在Transformer架构的每一层注入可训练的秩分解矩阵,大幅减少了下游任务所需的可训练参数数量。与使用Adam对GPT-3 175B进行微调相比,LoRA可以将可训练参数数量减少10000倍,GPU内存需求减少3倍。尽管可训练参数更少,LoRA在RoBERTa、DeBERTa、GPT-2和GPT-3模型质量上的表现却毫不逊色,甚至更优,它具有更高的训练吞吐量,并且与适配器不同,它不会增加额外的推理延迟。我们还对语言模型适应中的秩不足进行了实证研究,这有助于解释LoRA的有效性。我们发布了一个软件包,以便于LoRA与PyTorch模型集成,并在github上提供了我们的实现和RoBERTa、DeBERTa、GPT-2的模型checkpoints。
2 INTRODUCTION
在自然语言处理的许多应用中,依赖于将一个大规模预训练的语言模型适应到多个下游应用已成为一种常态。这种适应通常通过微调来完成,即更新预训练模型的所有参数。微调的主要缺点在于新模型包含的参数数量与原始模型相同。随着每隔几个月就会训练出更大的模型,这从GPT-2或RoBERTa large的“不便”转变为对GPT-3的严峻部署挑战,GPT-3拥有1750亿个可训练参数。
为了缓解这一问题,人们尝试仅适应部分参数或为新任务学习外部模块。这样,我们只需要存储和加载一小部分特定于任务的参数,除了预训练模型之外,极大地提高了部署时的操作效率。然而,现有技术通常引入推理延迟,通过扩展模型深度或减少模型可用序列长度。更重要的是,这些方法常常无法达到微调的基线性能,造成了效率和模型质量之间的权衡。
我们从Li等人(2018a)和Aghajanyan等人(2020)的研究中获得灵感,这些研究表明,实际上过度参数化的学习模型事实上位于低内在维度上。我们假设模型适应期间权重的变化也具有低“内在秩”,这引导我们提出了所提出的低秩适应(LoRA)方法。LoRA允许我们通过优化在适应期间密集层变化的秩分解矩阵来间接训练神经网络中的一些密集层,同时保持预训练权重不变,如图1所示。以GPT-3 175B为例,我们展示了即使全秩(即d)高达12,288,一个非常低的秩(如图1中的r,可以是1或2)也已足够,使LoRA在存储和计算上都非常高效。
LoRA具有几个关键优势:
-
可以共享一个预训练模型,并用它构建许多小型LoRA模块以适应不同任务。我们可以冻结共享模型,并通过替换图1中的矩阵A和B来高效切换任务,显著减少存储需求和任务切换开销。
-
LoRA使训练更加高效,并且在使用自适应优化器时,将硬件的入门门槛降低了高达3倍,因为我们不需要计算大多数参数的梯度或维护优化器状态。相反,我们只优化注入的、小得多的低秩矩阵。
-
我们简单的线性设计允许我们在部署时将可训练的矩阵与冻结的权重合并,在构造上与完全微调的模型相比,不引入任何推理延迟。
-
LoRA与许多现有方法正交,并且可以与它们中的许多方法结合使用,例如前缀调整。我们在附录E中提供了一个示例。
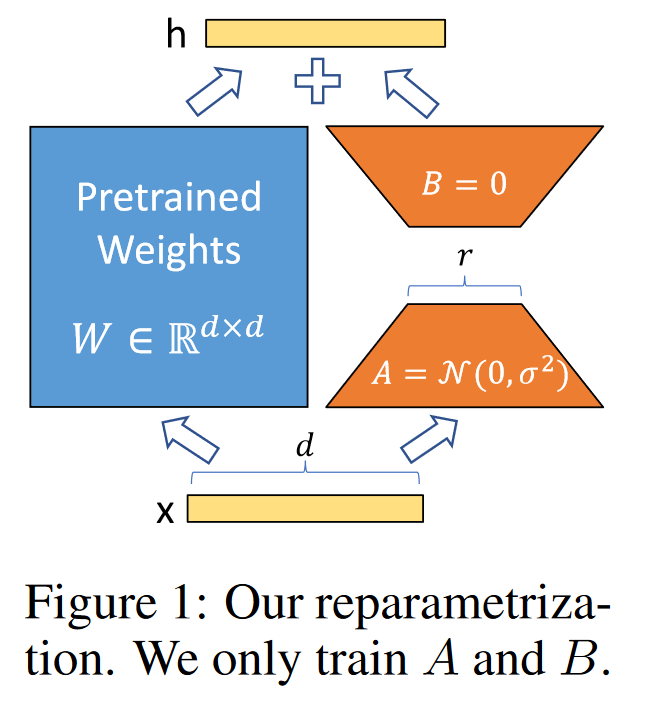
Figure 1 讲述了什么,简单描述一下
Figure 1 在文章中提供了LoRA方法的直观表示,即如何在不重新训练整个预训练模型的情况下,通过低秩分解来适应特定任务。以下是对Figure 1的解释说明:
在LoRA方法中,我们不是对整个预训练模型的权重矩阵 W 进行更新,而是保持这些权重固定不变,即“冻结”状态。取而代之的是,我们在每个Transformer层中注入两个较小的可训练矩阵 A 和 B,它们的秩(rank)远小于 W 的秩。这两个矩阵的乘积 AB 近似表示权重矩阵 W 在适应任务时的变化 △W。
例如,假设 W 是 12,288 * 12,288 的大型权重矩阵,而我们使用的 A 和 B 分别是 12,288 * r 和 r * 12,288 的矩阵,其中 r 是一个远小于12,288的较小数字。在实践中 r 可能只选择为1或2,这意味着 A 和 B 包含的参数数量大大减少。
在训练过程中,我们只更新 A 和 B,而不是整个 W 矩阵。这样,我们通过优化这两个小矩阵来间接地调整 W 的行为,使其更好地适应特定的下游任务。这种方法显著减少了模型参数的数量,从而降低了训练和部署所需的计算资源。
在部署阶段,我们可以将 A 和 B 与 W 合并,得到一个新的权重矩阵 W + AB,这个新矩阵可以直接用于推理过程,而不会引入任何额外的推理延迟。这种方法允许我们快速地在不同任务之间切换,只需简单地替换 A 和 B 矩阵即可。
通过这种方式,LoRA方法实现了对大型预训练模型的高效微调,同时保持了模型的灵活性和适应性。
我们频繁引用Transformer架构,并使用其尺寸的传统术语。我们将Transformer层的输入和输出维度大小称为d_model。我们使用 W_q、W_k、W_v 和 W_o 来指代自注意力模块中的查询/键/值/输出投影矩阵。W 或 W_0 指的是预训练的权重矩阵,而 △ W 表示在适应过程中累积的梯度更新。我们用 r 来表示LoRA模块的秩。我们遵循Vaswani等人(2017)和Brown等人(2020)设定的惯例,并使用Adam算法(Loshchilov和Hutter, 2019; Kingma和Ba, 2017)进行模型优化,并使用Transformer MLP前馈维度 d_ffn = 4 * d_model。
3AREN’T EXISTING SOLUTIONS GOOD ENOUGH?
我们要解决的问题绝不是什么新问题。自从迁移学习的概念诞生以来,已经有数十项研究致力于使模型适应更加参数和计算效率化。请参阅第6节,其中对一些知名作品进行了概述。以语言建模为例,在进行高效适应时有两种突出的策略:添加适配器层(Houlsby等人,2019年;Rebuffi等人,2017年;Pfeiffer等人,2021年;Rücklé等人,2020年)或优化输入层激活的一些形式(Li和Liang,2021年;Lester等人,2021年;Hambardzumyan等人,2020年;Liu等人,2021年)。然而,这两种策略在大规模和对延迟敏感的生产场景中都有其局限性。
Adapter Layers Introduce Inference Latency。adapter有许多变体。我们关注的是Houlsby等人(2019年)最初的设计,每个Transformer块有两个适配器层,以及Lin等人(2020年)的一个较新设计,每个块只有一个适配器层,但增加了一个LayerNorm(Ba等人,2016年)。虽然可以通过剪枝层或利用多任务设置(Rücklé等人,2020年;Pfeiffer等人,2021年)来减少总体延迟,但没有直接的方法可以绕过适配器层的额外计算。由于适配器层被设计为只有很少的参数(有时小于原始模型的1%),通过具有小的瓶颈维度来限制它们能增加的浮点运算次数(FLOPs),这看起来似乎不是问题。然而,大型神经网络依赖于硬件并行性来保持低延迟,而适配器层必须顺序处理。在通常批量大小只有一的在线推理设置中,这会产生影响。在没有模型并行性的通用场景中,例如在单个GPU上运行GPT-2(Radford等人,b)中型模型时,我们发现使用适配器时延迟明显增加,即使瓶颈维度非常小(见表1)。

当我们需要像Shoyebi等人(2020年);Lepikhin等人(2020年)所做的那样对模型进行分片时,这个问题会变得更糟,因为额外的深度需要更多的同步GPU操作,如AllReduce和Broadcast,除非我们多次冗余地存储适配器参数。
总结一下上面的内容:
上述内容讨论了在自然语言处理领域,尤其是在大规模语言模型微调和推理过程中,使用适配器层(Adapter Layers)方法时遇到的一个关键挑战:推理延迟问题。适配器层作为一种高效微调策略,旨在通过在预训练模型的Transformer块中插入少量额外参数来适应特定任务,而不必调整整个模型的大量参数。这样做理论上可以减少模型适应新任务所需的资源,但实际上却可能在某些场景下增加推理时间,特别是对于实时应用而言,这是一个重要考量。
适配器层的工作原理与设计
适配器层的设计通常包含两个主要部分:一个降维层(down-projection)和一个升维层(up-projection),中间夹着一个非线性函数(如ReLU)。这样的设计使得适配器即便拥有较少的参数(相比原模型参数量可能少于1%),也能有效地捕捉任务特定的信息。例如,Houlsby等人提出的原始设计在每个Transformer块中包含两个这样的适配器层,而Lin等人则提议每个块使用一个适配器层并加入额外的LayerNorm层以稳定训练。
引入的推理延迟问题
尽管适配器层在参数数量上做了减法,但在实际推理过程中,它们可能引入额外的计算延迟。原因在于:
硬件并行性限制:现代深度学习模型在高性能计算平台上运行时,高度依赖于并行处理来加速计算。适配器层的加入意味着模型的部分计算不能并行执行,因为它们必须按照序列顺序处理,这与原模型中可以高度并行化的Transformer层形成对比。在单个GPU上运行中等规模模型(如GPT-2 Medium)时,即使适配器层的参数非常少,也会观察到推理延迟的显著增加。
模型切分的影响:在分布式训练或推理场景中,模型会被分割到多个GPU上以进一步加速训练或处理更大的模型。这种切分(sharding)通常需要额外的同步操作(如AllReduce和Broadcast)来确保各个GPU间的参数一致性。适配器层的加入增加了模型的深度,这可能会导致更多的同步通信需求,进一步增加延迟,除非通过冗余存储适配器参数来减少这些通信成本。
实例说明
假设你正在开发一个基于云的服务,该服务使用了一个大型语言模型来进行文本生成。为了提高模型在特定领域的表现,决定采用适配器微调技术。原本,模型可以在单个GPU上快速响应用户请求,因为原模型设计充分利用了GPU的并行计算能力。然而,引入适配器层后,尽管模型在特定任务上的性能有所提升,但由于适配器层的串行处理特性,每个请求的处理时间(即推理延迟)变长了。在用户量大、实时交互要求高的场景下,这种延迟的增加可能会严重影响用户体验。
为了缓解这一问题,研究人员和工程师可能会探索不同的策略,比如优化适配器结构、改进硬件利用效率或者在模型切分时采取更高效的通信策略,以在保持微调效率的同时,最小化对推理延迟的影响。
Directly Optimizing the Prompt is Hard The other direction 直接优化提示很困难。正如前缀调整prefix tuning(Li和Liang,2021年)所示例的那样,这种方法面临不同的挑战。我们观察到前缀调整难以优化,并且其性能随着可训练参数的数量变化是非单调的,这与原始论文中的观察结果一致。更根本的是,为了适应性而保留一部分序列长度必然减少了用于处理下游任务的序列长度,我们怀疑这使得调整提示的性能不如其他方法。我们将任务性能的研究推迟到第5节。
prefix tuning是什么?
我们先进行简单说明,后续再进行详细介绍。
直接优化提示:这里指的是一种微调方法,通过改变输入数据的提示部分来调整模型的行为,使其更适合特定的任务。
前缀调整(Prefix Tuning):是一种特定的优化提示的方法,通过在输入序列的开始添加特殊的标记(tokens),并训练这些标记的嵌入表示来实现模型的微调。
优化困难:前缀调整可能难以找到合适的参数,因为它的性能可能随着参数数量的增加而不一定持续提高,有时甚至会出现性能下降的情况。
非单调变化:意味着性能指标(如准确率)并不总是随着训练的进行而单调增加,可能会出现波动或下降。
序列长度保留:在前缀调整中,需要在输入序列中预留一部分位置给特殊的前缀标记,这减少了模型处理实际任务数据的序列长度。
性能比较:由于减少了处理任务数据的序列长度,可能限制了模型的性能,使得前缀调整相比于其他微调方法(如LoRA)可能不那么有效。
这段内容强调了在进行模型微调时,除了考虑参数数量外,还需要考虑微调方法对模型整体性能的影响。
4 OUR METHOD
我们描述了LoRA的简单设计及其实际好处。这里概述的原则适用于深度学习模型中的任何密集层,尽管在我们的实验中,我们只关注Transformer语言模型中的某些权重,作为激励性用例。
-
LoRA的简单设计:指的是低秩适应(Low-Rank Adaptation)方法,它通过在模型的权重矩阵中引入低秩的可训练矩阵来实现对模型的微调,而不需要重新训练整个模型。
-
实际好处:LoRA方法带来了多方面的好处,包括减少所需的训练参数数量、降低计算资源需求、提高训练效率,同时避免了增加推理时的延迟。
-
适用于任何密集层:LoRA的设计原理不仅限于Transformer模型,也可以应用于深度学习中包含密集连接权重的任何层,这提供了一种通用的微调策略。
-
专注于Transformer语言模型:尽管LoRA可以广泛应用于不同的模型和层,但在本文的实验部分,作者选择专注于Transformer架构中的语言模型,因为它们在自然语言处理任务中非常流行且有效。
-
激励性用例:指的是使用LoRA对Transformer语言模型进行微调的实际案例,这些案例展示了LoRA方法的有效性和实用性,激励了对该方法进一步的研究和开发。
4.1 LOW-RANK-PARAMETRIZED UPDATE MATRICES
神经网络包含许多执行矩阵乘法的密集层。这些层中的权重矩阵通常具有全秩。在适应特定任务时,Aghajanyan等人(2020年)表明,预训练的语言模型具有低“内在维度”,并且尽管进行了到较小子空间的随机投影,仍然可以高效地学习。受此启发,我们假设在适应过程中权重的更新也具有低“内在秩”。对于预训练的权重矩阵 W_0 in R^{d * k,我们通过表示后者具有低秩分解 W_0 + △W = W_0 + BA 来限制其更新,其中B in R^{d * r}, A in R^{r * k},秩 r 《 min(d, k)。在训练期间,W_0 被冻结,不接受梯度更新,而 A 和 B 包含可训练的参数。注意,W_0 和 △W = BA 与相同的输入相乘,并且它们各自的输出向量按坐标相加。对于 h = W_0x,我们修改后的前向传播过程产生的结果是:
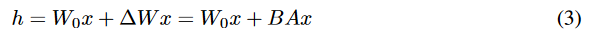
请注意,这里的 W_0 是预训练模型中的原始权重矩阵,△W 是权重的更新,B 和 A 是在训练过程中学习的低秩矩阵,x 是输入向量,h 是经过修改后的层的输出向量。这种方法允许模型在保持大部分预训练权重不变的同时,通过调整小部分参数来适应新任务。
我们在图1中展示了我们的重新参数化。我们对 A 使用随机高斯初始化,对 B 使用零初始化,因此在训练开始时△ W = BA 是零。然后我们按 alpha 除以 r 的比例缩放 △W x ,其中 alpha 是与 r 相关的常数。当使用Adam优化器时,调整 alpha 大致上与调整学习率相同,如果我们适当地缩放初始化的话。因此,我们简单地将 alpha 设置为我们尝试的第一个 r 值,并且不进行调整。这种缩放有助于在变化 r 时减少重新调整超参数的需要(Yang & Hu, 2021)。
总结一下上面的内容:
重新参数化:指的是在神经网络中对权重矩阵的更新方式进行的一种调整,以便于更高效地进行训练和微调。
随机高斯初始化:这是一种初始化方法,其中 A 矩阵的初始值是从高斯分布中随机抽取的,这有助于模型在训练初期探索参数空间。
零初始化:B 矩阵则被初始化为零,这意味着在训练开始时, △W = BA 的值是零,从而不会影响模型的初始状态。
缩放:在训练过程中,对 △W x 进行缩放,缩放因子为 alpha 除以 r ,这里 alpha 是一个常数,而 r 是低秩分解中的秩。
优化器Adam:一种自适应学习率优化算法,广泛应用于深度学习中,因其结合了AdaGrad和RMSProp的优点。
调整α:在优化过程中,调整 lpha 与调整学习率有相似的效果,特别是当初始化值被适当缩放时。
超参数调整:在模型训练中,超参数如学习率和 r 需要被调整以获得最佳性能。文中提到的缩放方法减少了在改变 r 时重新调整这些超参数的需要。
A Generalization of Full Fine-tuning。全微调的一种泛化形式允许对预训练参数的一个子集进行训练。LoRA更进一步,它不要求在适应过程中累积的梯度更新到权重矩阵必须是满秩的。这意味着,当我们将LoRA应用于所有权重矩阵并训练所有偏置时,通过将LoRA的秩r设置为预训练权重矩阵的秩,我们大致能恢复全微调的表达能力。换句话说,随着可训练参数数量的增加,训练LoRA大致趋近于训练原始模型,而基于适配器的方法趋近于一个多层感知器(MLP),基于前缀的方法则趋近于一个无法处理长输入序列的模型。
总结一下上面的内容:
上述内容描述了LoRA(Low-Rank Adaptation)方法如何作为一种全微调的泛化形式,允许对预训练模型的参数子集进行训练,并且具有一些独特的优势。以下是对这段内容的说明和示例:
全微调的泛化:通常的全微调会更新模型的所有参数以适应新任务。而全微调的泛化形式,允许我们只选择性地更新模型的一部分参数,而不是全部。
LoRA方法:LoRA通过在预训练的权重矩阵中引入低秩的可训练矩阵来实现参数更新,而不是直接更新整个权重矩阵。这减少了训练所需的参数数量。
不需要满秩更新:在LoRA中,权重矩阵的更新(即梯度累积)不需要是满秩的。这意味着即使在参数更新中存在一些线性依赖,模型仍然可以有效地学习和适应新任务。
恢复全微调的表达能力:通过将LoRA的秩 r 设置为与预训练权重矩阵相同的秩,我们可以在一定程度上模拟全微调的效果。这表明LoRA在参数数量增加时,其表达能力可以接近全微调。
训练LoRA与训练原始模型的趋近性:随着可训练参数数量的增加,使用LoRA进行训练的效果将越来越接近于直接训练原始模型。
与适配器方法和前缀方法的比较:与基于适配器的方法(可能导致模型趋向于一个多层感知器)和基于前缀的方法(可能导致模型无法处理长输入序列)相比,LoRA提供了一种平衡,既能有效适应新任务,又能保持处理长序列的能力。
示例说明:
假设我们有一个大型的预训练Transformer模型,它包含数十亿个参数。如果我们想要将这个模型适应到一个特定的下游任务,比如情感分析,使用全微调我们将不得不更新所有参数,这在计算上可能非常昂贵。
使用LoRA,我们可以只选择模型中与情感分析最相关的部分权重矩阵进行更新。例如,我们可以只更新模型中与情感表达有关的特定层的权重,通过引入低秩矩阵 B 和 A 来实现这一点。这样,我们只训练这些低秩矩阵的参数,而不是整个权重矩阵,从而大大减少了训练参数的数量和计算成本。
如果我们将LoRA应用于模型的所有权重矩阵,并适当设置秩 r ,我们就可以近似地恢复全微调的效果,但同时保持了训练效率。这样,我们就可以在不牺牲太多性能的情况下,快速适应新任务。
No Additional Inference Latency。在生产环境中部署时,我们可以明确计算并存储 W = W_0 + BA,并像平常一样进行推理。注意,W_0 和 BA 都在 R^{d * k} 中。当我们需要切换到另一个下游任务时,我们可以通过减去 BA 然后加上不同的 B’A’ 来回恢复 W_0,这是一个快速操作,几乎没有内存开销。至关重要的是,通过构造,这保证了我们在推理期间不会引入任何与微调模型相比的额外延迟。
4.2 APPLYING LORA TO TRANSFORMER
原则上,我们可以将LoRA应用于神经网络中任意子集的权重矩阵以减少可训练参数的数量。在Transformer架构中,自注意力模块含有四个权重矩阵(Wq、Wk、Wv、Wo),而多层感知器(MLP)模块含有两个权重矩阵。尽管输出维度通常被切分为注意力头,我们仍将Wq(或Wk、Wv)视为维度为dmodel × dmodel的单一矩阵。为了简化处理和提高参数效率,我们的研究仅限于针对下游任务调整自注意力权重,并冻结MLP模块(使其在下游任务中不被训练)。
我们在第7.1节中进一步研究了在Transformer中适应不同类型注意力权重矩阵的效果。将MLP层、LayerNorm层以及偏置项的适应调整留作未来工作的实证研究。
Practical Benefits and Limitations。最显著的好处来自于内存和存储使用的减少。对于使用Adam训练的大型Transformer模型,如果 r 《 d_model,我们最多可以减少三分之二的VRAM使用量,因为我们无需为冻结的参数存储优化器状态。在GPT-3 175B模型上,我们将训练期间的VRAM消耗从1.2TB降低到了350GB。当 r = 4 ,且仅适应查询和价值投射矩阵时,checkpoint大小大约减少了1万倍(从350GB减少到35MB)。这使我们能够使用显著更少的GPU进行训练,并避免I/O瓶颈。
另一个好处是,部署后我们可以在更低的成本下切换任务,只需交换LoRA权重,而非所有参数。这允许创建许多可定制的模型,这些模型可以在存储了预训练权重的VRAM的机器上即时地插入和移除。我们还观察到,在GPT-3 175B上与全微调相比,训练速度提高了25%,因为我们不需要为绝大多数参数计算梯度。
LoRA也存在一些局限性。例如,如果选择将A和B合并到W中以消除额外的推理延迟,那么在单次前向传播中对不同任务使用不同A和B的输入进行批处理并不直接。尽管在延迟不是关键因素的情境下,可以选择不合并权重,并动态地为批次中的样本选择要使用的LoRA模块。
总结一下上面的内容:
优势包括:
资源节省:LoRA大幅减少了内存和存储需求。特别是对于大规模的Transformer模型,在使用Adam优化器训练时,由于不需要为冻结的参数保存优化器状态,当LoRA的秩r远小于模型维度d_model时,VRAM使用量可以减少多达三分之二。例如,在GPT-3 175B模型上,通过应用LoRA,训练时的VRAM消耗从1.2TB降低至350GB,且在特定配置下,模型checkpoint的大小更是缩减了约1万倍,从350GB减至35MB。这不仅使得模型能够在配备较少GPU的硬件上进行训练,还有效缓解了I/O瓶颈问题。
灵活的任务切换:部署后,仅需交换LoRA权重即可低成本地在不同任务间切换,相较于需要替换所有参数的做法更为高效。这促进了多种定制化模型的快速创建和即时部署,特别是在那些预训练权重已载入VRAM的设备上。
加速训练:与全微调相比,LoRA在GPT-3 175B上的训练速度提升了25%,因为它减少了需要计算梯度的参数数量。
局限性涉及:
- 批量处理挑战:LoRA的一个局限在于,如果为了减少推理延迟而将调整矩阵A和B合并到基础权重W中,那么在同一前向传播过程中处理多个任务且这些任务各有不同的A和B矩阵时,会变得不直观或复杂。虽然在对延迟要求不高的场景中,可以通过不合并权重并根据批次中样本所属任务动态选择相应的LoRA模块来绕过这个问题,但这依然增加了实现的复杂度。
总的来说,LoRA作为一种高效的模型微调技术,在减少资源消耗、加速训练流程及支持快速任务切换方面表现出色,但同时也需要考虑其在复杂多任务处理场景下的实现挑战。
5 EMPIRICAL EXPERIMENTS
我们在RoBERTa(刘等人,2019年)、DeBERTa(何等人,2021年)和GPT-2(拉德福德等人,b)上评估了LoRA在下游任务上的性能,然后扩展到GPT-3 175B(布朗等人,2020年)。我们的实验涵盖了从自然语言理解(NLU)到生成(NLG)的广泛任务。具体来说,我们在GLUE(王等人,2019年)基准测试中评估RoBERTa和DeBERTa。我们遵循李和梁(2021年)在GPT-2上的设置进行直接比较,并为GPT-3的大规模实验增加了WikiSQL(钟等人,2017年)(自然语言到SQL查询)和SAMSum(格利瓦等人,2019年)(对话摘要)。有关我们使用的更多数据集详细信息,请参阅附录C。我们所有实验都使用NVIDIA Tesla V100。
5.1 BASELINES
Fine-Tuning (FT) 微调(Fine-Tuning,简称FT)是一种常用的模型适应方法。在微调过程中,模型的参数(权重和偏置)会初始化为预训练时的值,随后所有模型参数都会通过梯度更新进行调整。一个简单的变种方法是只更新部分层的参数,而将其他层固定不变。我们纳入了一个基于GPT-2的先前工作(李和梁,2021)中报告的基线案例,该案例仅对最后两层进行微调(称为FTTop2)。
Bias-only or BitFit 偏置或BitFit是一种基线方法,其中我们只训练偏置向量,同时冻结所有其他参数。同时,这种基线方法也由BitFit(Zaken等人,2021年)进行了研究。
Prefix-embedding tuning (PreEmbed) 前缀嵌入调整(PreEmbed)在输入token中插入特殊token。这些特殊token具有可训练的词嵌入,并且通常不在模型的词汇表中。这些token的放置位置可能对性能有影响。我们专注于“前缀化”,它将这些token添加到提示的前面,以及“中缀化”,它将这些token添加到提示的后面;两者都在Li和Liang(2021年)中进行了讨论。我们使用 l_p(分别表示 l_i )来表示前缀(分别中缀)token的数量。可训练参数的数量是 |Θ| = d_model * (l_p + l_i) 。
Adapter tuning 适配器调整,如Houlsby等人(2019年)所提出的,在自注意力模块(和MLP模块)与随后的残差连接之间插入适配器层。适配器层中有两个带有偏置的全连接层,并在两者之间有一个非线性激活。我们称这种原始设计为AdapterH。最近,Lin等人(2020年)提出了一个更高效的设计,适配器层仅在MLP模块和LayerNorm之后应用。我们称它为AdapterL。这与Pfeiffer等人(2021年)提出的另一种设计非常相似,我们称它为AdapterP。我们还包括了另一个称为AdapterDrop的基线(Rücklé等人,2020年),它为了更高的效率而丢弃了一些适配器层(AdapterD)。我们尽可能引用先前工作中的数字,以使我们比较的基线数量最大化;它们在第一列带有星号(*)的行中。在所有情况下,我们有 |Θ| = L_Adpt * (2 * d_model * r + r + d_model) + 2 * hat{L}_LN * d_model,其中 L_Adpt 是适配器层的数量,hat{L}_LN 是可训练的LayerNorms的数量(例如,在AdapterL中)。
适配器调整(Adapter Tuning):一种在模型中引入适配器层的方法,用以改善模型对特定任务的适应性。
AdapterH:Houlsby等人(2019年)提出的原始适配器设计,每个适配器层包含两个全连接层和非线性激活。
AdapterL:Lin等人(2020年)提出的设计,适配器层仅在MLP和LayerNorm之后应用,更为高效。
AdapterP:Pfeiffer等人(2021年)提出的设计,与AdapterL类似。
AdapterDrop(AdapterD):Rücklé等人(2020年)提出的设计,通过丢弃一些适配器层来提高效率。
LoRA LoRA在现有权重矩阵旁添加了可训练的秩分解矩阵对。如第4.2节所述,为了简单起见,我们在大多数实验中仅将LoRA应用于 W_q 和 W_v 。可训练参数的数量由秩 r 和原始权重的形状决定:|Θ| = 2 * hat{L}_LoRA * d_model * r ,其中 hat{L}_LoRA 是我们应用LoRA的权重矩阵的数量。
5.2 ROBERTA BASE/LARGE
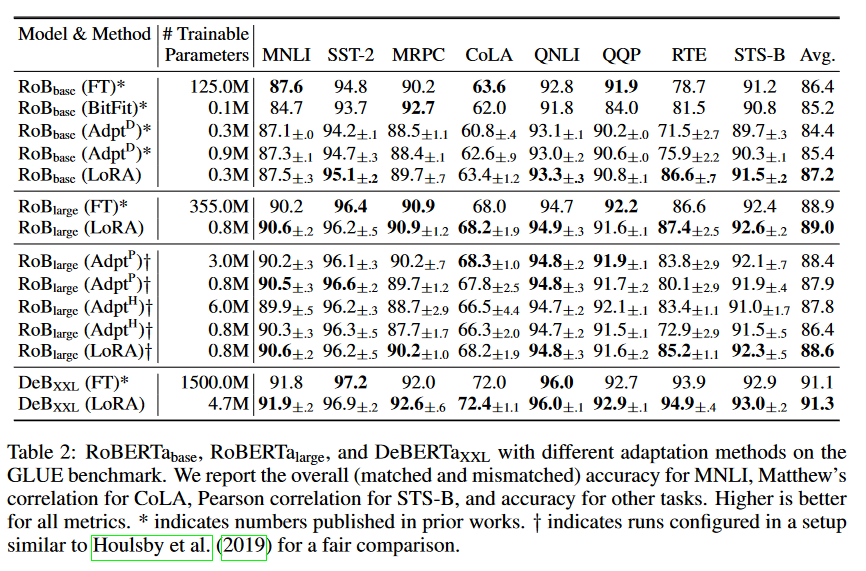
RoBERTa(刘等人,2019年)优化了最初在BERT(Devlin等人,2019a年)中提出的预训练方法,并在不引入更多可训练参数的情况下提高了后者的任务性能。尽管近年来在GLUE基准(王等人,2019年)等NLP排行榜上,RoBERTa已被更大的模型超越,但它仍然是实践中以其规模而受欢迎的竞争性预训练模型。我们从HuggingFace Transformers库(Wolf等人,2020年)中获取了预训练的RoBERTa基础版(125M)和RoBERTa大型版(355M),并评估了不同高效适应方法在GLUE基准任务上的性能。我们还根据Houlsby等人(2019年)和Pfeiffer等人(2021年)的设置复制了实验。为了确保公平比较,我们在与适配器比较时对LoRA的评估方式进行了两个关键性的改变。首先,我们对所有任务使用相同的批量大小,并使用128的序列长度以匹配适配器基线。其次,我们对MRPC、RTE和STS-B初始化模型为预训练模型,而不是像微调基线那样已经适应了MNLI的模型。遵循Houlsby等人(2019年)这种更受限制设置的运行被标记为†。结果在表2的前三个部分中呈现。有关使用的超参数的详细信息,请参见第D.1节。
RoBERTa:一种基于BERT优化的预训练模型,它改进了任务性能,同时保持了参数量的相对稳定。
BERT:一种先前提出的预训练模型,RoBERTa在其基础上进行了优化。
GLUE基准:一种广泛使用的自然语言处理任务基准,用于评估模型性能。
HuggingFace Transformers库:一个流行的开源库,提供了多种预训练模型和工具。
LoRA:一种低秩适应方法,用于在不显著增加参数量的情况下调整预训练模型。
微调基线:在比较实验中使用的已经针对特定任务进行微调的模型性能标准。
适配器:一种添加到模型中的模块,用于改善模型对特定任务的适应性。
5.3 DEBERTA XXL
DeBERTa(何等人,2021年)是BERT的一个更近期的变体,它在更大的规模上进行了训练,并且在GLUE(王等人,2019年)和SuperGLUE(王等人,2020年)等基准测试上表现出很强的竞争力。我们评估了LoRA是否仍然能够与完全微调的DeBERTa XXL(15亿参数)在GLUE上的性能相匹配。结果在表2的底部部分展示。有关使用的超参数的详细信息,请参见第D.2节。
5.4 GPT-2 MEDIUM/LARGE
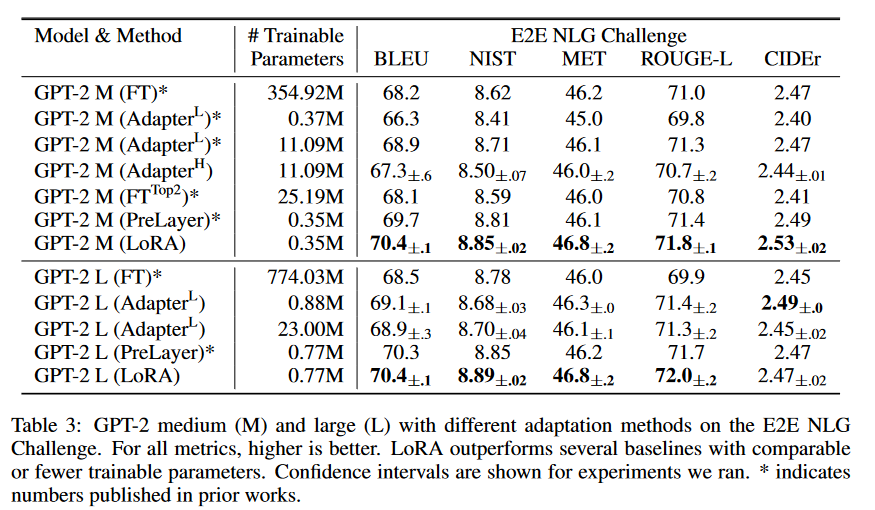
已经展示了LoRA在自然语言理解(NLU)任务上可以作为全微调的一个有竞争力的替代方案,我们希望探讨LoRA在自然语言生成(NLG)模型上是否仍然具有优势,例如GPT-2的中型和大型模型(Radford等人,b)。我们尽可能保持我们的设置与Li和Liang(2021年)接近,以便进行直接比较。由于篇幅限制,我们仅在这一部分展示我们在端到端自然语言生成挑战(E2E NLG Challenge)上的结果(表3)。有关WebNLG(Gardent等人,2017年)和DART(Nan等人,2020年)的结果,请参见第F.1节。我们在第D.3节中列出了使用的超参数列表。
5.5 SCALING UP TO GPT-3 175B
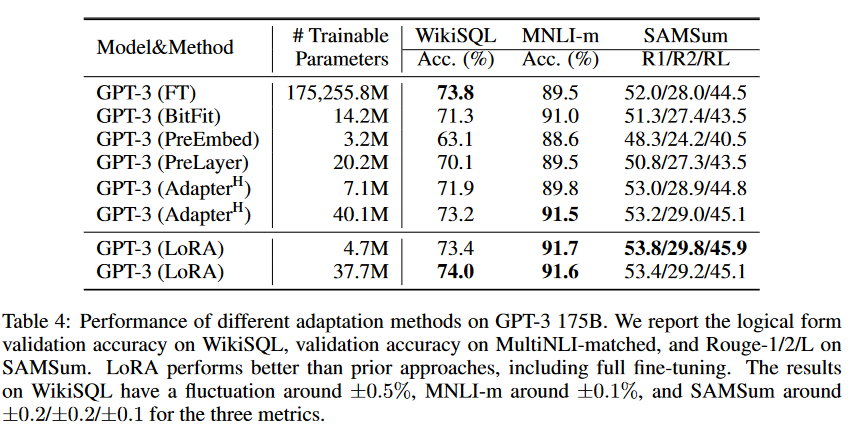
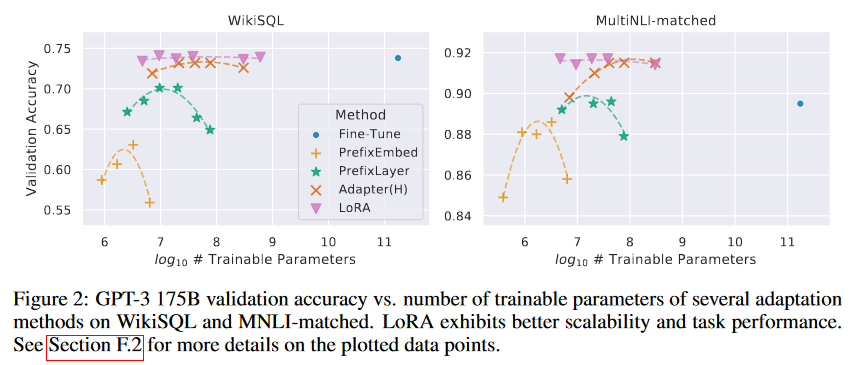
作为对LoRA的最终压力测试,我们将模型扩展到具有1750亿参数的GPT-3。由于训练成本高昂,我们只报告了给定任务在随机种子上的典型标准差,而不是为每个条目提供一个。有关使用的超参数的详细信息,请参见第D.4节。正如表4所示,LoRA在所有三个数据集上达到了或超过了微调基线。需要注意的是,并非所有方法都能从拥有更多可训练参数中单调受益,如图2所示。我们观察到,当用于前缀嵌入调整的特殊token超过256个,或用于前缀层调整的特殊token超过32个时,性能显著下降。这证实了Li和Liang(2021年)中的类似观察结果。虽然对这种现象进行彻底调查不在本工作范围内,但我们怀疑拥有更多特殊token会导致输入分布进一步偏离预训练数据的分布。此外,我们在第F.3节中研究了不同适应方法在低数据环境下的性能。
6 RELATED WORKS
Transformer Language Models。Transformer语言模型。Transformer(Vaswani等人,2017年)是一种序列到序列的架构,它大量使用了自注意力机制。Radford等人(a)通过使用一堆Transformer解码器将其应用于自回归语言建模。从那时起,基于Transformer的语言模型就主导了自然语言处理(NLP),在许多任务上实现了最先进的性能。随着BERT(Devlin等人,2019b年)和GPT-2(Radford等人,b)的出现,出现了一种新的范式——它们都是在大量文本上训练的大型Transformer语言模型,在通用领域数据上预训练后,再在特定任务数据上进行微调,与直接在特定任务数据上训练相比,可以获得显著的性能提升。通常,训练更大的Transformer模型会得到更好的性能,这仍然是一个活跃的研究方向。GPT-3(Brown等人,2020年)是迄今为止训练过的最大的单一Transformer语言模型,拥有1750亿参数。
Prompt Engineering and Fine-Tuning。尽管GPT-3 175B能够仅通过一些额外的训练样本来调整其行为,但结果在很大程度上取决于输入的提示(prompt)(Brown等人,2020年)。这就形成了一种实证艺术,即撰写和格式化提示以最大化模型在期望任务上的性能,这被称为提示工程或提示黑客技术。微调是对在通用领域预训练过的模型进行重新训练,以适应特定任务(Devlin等人,2019b年;Radford等人,a)。它的变化形式包括只学习参数的一个子集(Devlin等人,2019b年;Collobert和Weston,2008年),然而实践者通常重新训练所有参数以最大化下游性能。然而,GPT-3 175B的巨大规模使得按常规方式进行微调变得具有挑战性,因为它产生的大型checkpoint和高昂的硬件门槛,这与预训练时的内存占用相同。
Parameter-Efficient Adaptation。许多人提出在神经网络的现有层之间插入适配器层(Houlsby等人,2019年;Rebuffi等人,2017年;Lin等人,2020年)。我们的方法使用类似的瓶颈结构对权重更新施加低秩约束。关键的功能区别在于,我们学习到的权重可以在推理期间与主权重合并,因此不引入任何延迟,而这并不适用于适配器层(第3节)。适配器的一个当代扩展是COMPACTER(Mahabadi等人,2021年),它本质上是使用Kronecker积和一些预定的权重共享方案来参数化适配器层。同样,将LoRA与其他基于张量积的方法结合使用,可能会提高其参数效率,我们将这一点留作未来的工作。最近,许多人提出优化输入词嵌入以替代微调,类似于连续且可微的提示工程的概括(Li和Liang,2021年;Lester等人,2021年;Hambardzumyan等人,2020年;Liu等人,2021年)。我们在实验部分包括了与Li和Liang(2021年)的比较。然而,这一工作线索只能通过在提示中使用更多的特殊token来扩展,当学习位置嵌入时,这些特殊token会占用任务token的可用序列长度。
- 适配器层(Adapter Layers):在神经网络中插入的额外层,用于改变模型的行为以适应新任务。
- 瓶颈结构(Bottleneck Structure):一种网络结构,其中信息通过一个较窄的通道流动,常用于特征提取和降维。
- 低秩约束(Low-Rank Constraint):在数学和工程中,限制一个矩阵的秩(即线性独立行或列的数量)来简化问题。
-COMPACTER:一种适配器层的扩展方法,使用Kronecker积来参数化适配器层,可能引入权重共享。
Low-Rank Structures in Deep Learning。低秩结构在机器学习中极为普遍。许多机器学习问题展现出某种内在的低秩特性(Li et al., 2016; Cai et al., 2010; Li et al., 2018b; Grasedyck et al., 2013)。此外,众所周知,在众多深度学习任务中,特别是那些采用严重过参数化的神经网络时,经过训练后的学习神经网络往往呈现出低秩性质(Oymak et al., 2019)。一些前期工作甚至在训练原始神经网络时明确施加了低秩约束(Sainath et al., 2013; Povey et al., 2018; Zhang et al., 2014; Jaderberg et al., 2014; Zhao et al., 2016; Khodak et al., 2021; Denil et al., 2014);然而,据我们所知,这些工作中没有一项考虑到对冻结模型进行低秩更新以适应下游任务的情况。在理论文献中,已知当潜在概念类具有特定的低秩结构时,神经网络的表现优于其他经典学习方法,包括相应的(有限宽度)神经切线核方法(Allen-Zhu et al., 2019; Li & Liang, 2018)(Ghorbani et al., 2020; Allen-Zhu & Li, 2019; Allen-Zhu & Li, 2020a)。另一项Allen-Zhu & Li (2020b)的理论成果提示,低秩适应对于对抗性训练也是有益的。综上所述,我们认为提出的低秩适应更新方法受到了文献的充分启发。
7UNDERSTANDING THE LOW-RANK UPDATES
鉴于LoRA的实证优势,我们希望进一步解释从下游任务中学到的低秩适应的性质。请注意,低秩结构不仅降低了硬件的入门门槛,使我们能够并行运行多个实验,而且还更好地解释了更新权重与预训练权重之间的相关性。我们专注于研究GPT-3 175B,在这里我们在不影响任务性能的情况下实现了可训练参数的最大减少(高达10,000倍)。
我们进行了一系列实证研究以回答以下问题:1) 给定参数预算限制,我们应该调整预训练Transformer中的哪组权重矩阵以最大化下游性能?2) “最优”的适应矩阵 △W 真的是秩不足的吗?如果是,实践中应该使用多少秩?3) △ W 和 W 之间的联系是什么?△W 与 W 高度相关吗?与 W 相比, △W 有多大?
我们相信,我们对问题(2)和(3)的回答能够阐明使用预训练语言模型进行下游任务的根本原则,这是自然语言处理(NLP)中的一个关键话题。
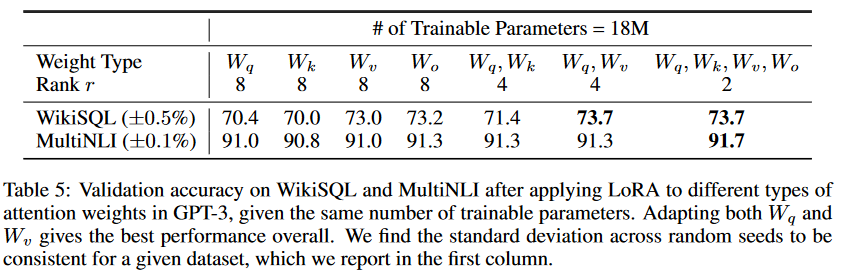
7.1 WHICH WEIGHT MATRICES IN TRANSFORMER SHOULD WE APPLY LORA TO?
在给定有限的参数预算下,我们应该用LoRA适应哪些类型的权重以获得下游任务的最佳性能?如第4.2节所述,我们只考虑自注意力模块中的权重矩阵。我们在GPT-3 175B上设定了一个18M的参数预算(如果以FP16存储大约为35MB),这对应于如果我们适应一种类型的注意力权重,则r = 8,或者如果我们适应两种类型的权重,则r = 4,适用于所有96层。结果在表5中呈现。注意,将所有参数都放在 △W_q 或 △W_k 会导致明显更低的性能,而同时适应△W_q 或 △W_k则产生最佳结果。这表明即使是秩为四也足以在△W_k中捕获足够的信息,以至于更倾向于适应更多的权重矩阵,而不是仅仅适应一种类型的权重且具有较大的秩。
总结一下上面的内容:
假设我们有一个预训练的GPT-3 175B模型,它是一个具有1750亿参数的大型语言模型,我们希望将其适应到特定的下游任务,比如情感分析。由于模型规模庞大,直接对所有参数进行微调(Full Fine-tuning)成本很高。因此,我们考虑使用LoRA方法来减少所需的可训练参数数量。
步骤1:设定参数预算
我们设定了一个参数预算,即我们只允许模型有18M个可训练参数进行调整。这个预算限制了我们可以使用的LoRA参数的数量。
步骤2:选择权重矩阵
在Transformer模型中,自注意力模块包含几种类型的权重矩阵:W_q (查询)、 W_k (键)、 W_v (值)和 W_o (输出)。根据上述内容,我们决定只考虑自注意力模块中的权重矩阵进行LoRA。
步骤3:分配秩(Rank)
我们的参数预算允许我们在秩为8时适应一种类型的注意力权重,或者在秩为4时适应两种类型的注意力权重。这意味着我们可以为每种权重矩阵分配更多的参数,或者用较少的参数适应更多的权重矩阵。
步骤4:进行LoRA
我们选择适应 W_q 和 W_v 两种权重矩阵,因为实验表明这种组合可以在下游任务中获得最佳性能。在LoRA中,我们不是直接更新这些权重矩阵,而是引入两个低秩矩阵 A 和 B ,它们的乘积 BA 近似了权重矩阵的更新 △W 。
步骤5:实验结果
实验结果显示,将所有参数仅放在 △W_q 或 △W_k 上会导致性能显著下降。而同时适应 W_q 和 W_v 可以得到最佳结果。这表明即使是秩为4,也足以捕获足够的信息来实现有效的任务适应。
步骤6:解释和应用
通过这个例子,我们了解到在使用LoRA进行模型微调时,选择适当的权重矩阵并合理分配秩是非常重要的。这不仅可以减少所需的参数数量,还可以保持或提高模型在特定任务上的性能。此外,由于LoRA在推理时不会引入额外的延迟,因此它在实际部署中也非常有用。
7.2 WHAT IS THE OPTIMAL RANK r FOR LORA?
我们将注意力转向秩 r 对模型性能的影响。为了进行对比,我们分别对 {W_q, W_v} 、 {W_q, W_k, W_v, W_o} 以及仅对 W_q 进行适应调整。
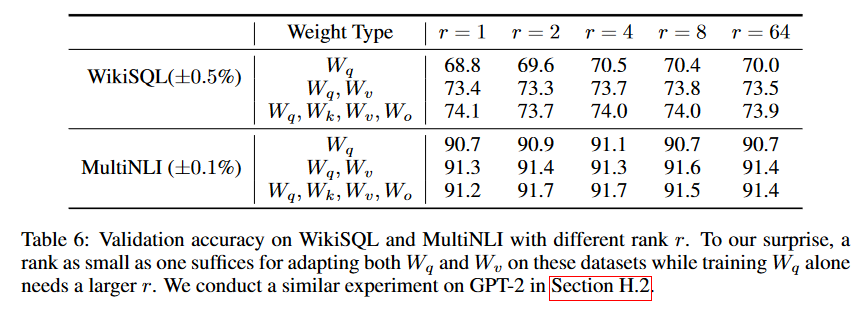
表6显示,令人惊讶的是,LoRA即便在使用非常小的秩 r (尤其是对 {W_q, W_v} 而非仅对 W_q 时)已经能展现出与竞争对手相当的性能。这表明更新矩阵 △W 可能具有非常小的“固有秩”。为了进一步证实这一发现,我们检查了不同 r 值选择及不同随机种子下所学到的子空间之间的重叠情况。我们主张,增大 r 并不会覆盖到更有意义的子空间,这表明低秩适应矩阵已经足够。
Subspace similarity between different r。给定学习到的适应矩阵 A_{r=8} 和 A_{r=64},它们分别是使用相同预训练模型并设置秩 r 为8和64得到的。我们对这两个矩阵进行了奇异值分解,从而获得了右奇异单位矩阵 U_A_{r=8} 和 U_A_{r=64}。我们的目的是探究如下问题:由 U_A_{r=8} 的前 i 个奇异向量(其中 1 <= i <= 8 )张成的子空间有多少包含在由 U_A_{r=64} 的前 j 个奇异向量(其中 ( 1 <= j <= 64)张成的子空间中?我们通过基于Grassmann距离的标准化子空间相似度来衡量这个量(关于更正式的讨论,请参见附录G)。
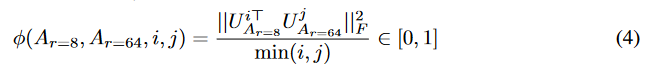
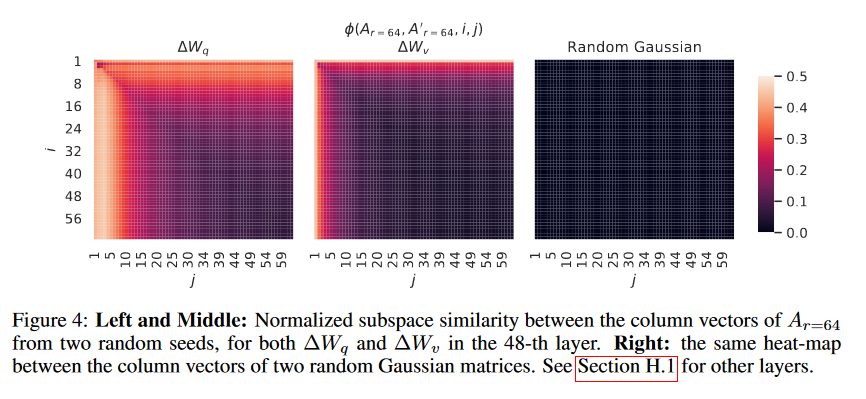
其中, U_i^{A_r=8} 表示 U_A_{r=8} 中对应于前i个最大奇异值的列向量。函数 varphi(·) 的取值范围为[0, 1],其中1表示子空间完全重叠,0表示子空间完全分离。图3展示了随着我们改变i和j时,varphi 如何变化。由于篇幅限制,我们仅观察了第48层(共96层)的情况,但结论同样适用于其他层,这一点在第H.1节中有展示。
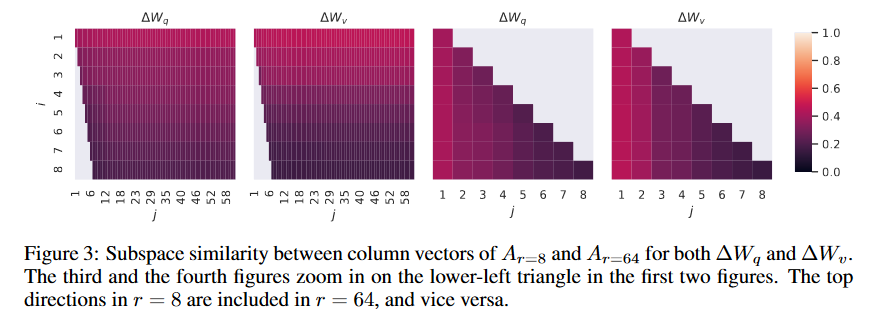
我们从图3中得出了一个重要观察结果。在 A_{r=8} 和 A_{r=64} 之间,对应于顶部奇异向量的方向有显著重叠,而其他向量方向则没有。具体来说, A_{r=8} 中的△ W_v(相应地, △ W_q )与 A_{r=64} 中的 △ W_v (相应地, △ W_q)共享一个维度为1的子空间,其归一化相似度大于0.5,这就解释了为什么在针对GPT-3的下游任务中, r = 1 能够表现出相当好的性能。
由于 A_{r=8} 和 A_{r=64} 都是使用相同的预训练模型学习得到的,图3表明, A_{r=8} 和 A_{r=64} 的顶级奇异向量方向是最有用的,而其他方向可能主要包含了训练过程中积累的随机噪声。因此,适应矩阵确实可以具有很低的秩。
Subspace similarity between different random seeds。我们通过绘制两个随机种子运行(均设置 r = 64 )之间的归一化子空间相似度来进一步确认这一点,如图4所示。△ W_q 显然比 △ W_v 具有更高的“固有秩”,因为两个运行都为 △ W_q 学习到了更多共同的奇异值方向,这与我们在表6中的经验观察一致。作为对比,我们还绘制了两个随机高斯矩阵,它们彼此之间没有任何共同的奇异值方向。
7.3 HOW DOES THE ADAPTATION MATRIX ∆W COMPARE TO W ?
为进一步探究权重变化 (∆W) 与原始权重 (W) 之间的关系,我们考察两者是否高度相关,即从数学角度分析,∆W 是否主要位于 W 的主导奇异方向内?同时,我们评估相对于 W 中相应方向的“幅度”,∆W 的规模如何?这能为理解预训练语言模型适应特定下游任务的底层机制提供洞见。
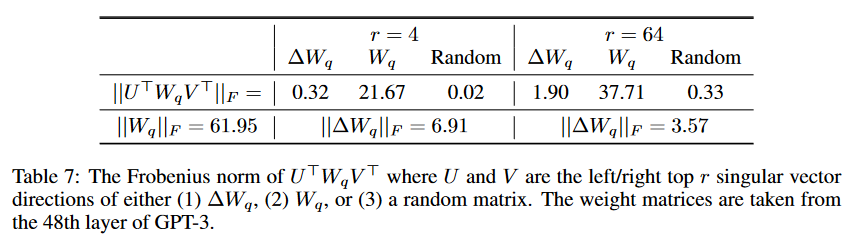
为解答这些问题,我们通过计算 U>WV> 将 W 投影到 ∆W 的 r 维子空间上,其中 U/V 分别代表 ∆W 的左/右奇异向量矩阵。随后,我们比较 U>WV> 与 W 在 Frobenius 范数上的大小关系。作为对比,我们同样计算了使用 W 或随机矩阵的前 r 个奇异向量替代 U 和 V 后的 U>WV> 的 Frobenius 范数。
从表 7 中,我们得出几点结论。首先,与随机矩阵相比,∆W 与 W 之间的相关性更强,表明 ∆W 增强了 W 中已存在的某些特征。其次,∆W 并非简单重复 W 的主导奇异方向,而是仅放大了 W 中未被充分强调的方向。第三,放大效应相当显著:当 r=4 时,放大因子约为 21.5,计算方式为 6.91/0.32。有关为何 r=64 时放大因子较小,请参见附录 H.4。此外,我们在附录 H.3 中通过可视化展示了随着纳入更多来自 Wq 的顶级奇异方向,相关性如何变化。
这表明低秩适应矩阵有可能针对特定下游任务放大那些在通用预训练模型中虽已习得但未被充分重视的重要特征。
8 CONCLUSION AND FUTURE WORK
微调庞大语言模型的成本极高,不仅需要大量的硬件资源,而且为不同任务托管独立实例时会带来存储和切换的高昂成本。我们提出了一种名为LoRA的有效适应策略,该策略在保持模型高质量的同时,不增加推理延迟,也不减少输入序列长度,并且支持快速的任务切换,尤其在作为服务部署时,通过共享绝大多数模型参数来实现这一优势。尽管我们的重点放在了Transformer语言模型上,但所提出的原理普遍适用于任何包含密集层的神经网络。
未来研究方向众多:1) LoRA可与其他高效的适应方法结合,可能带来互补性的改进。2) 微调或LoRA背后的机制尚不明确——预训练期间学习到的特征是如何转化为对下游任务表现优异的能力的?我们相信,与完全微调相比,LoRA使得回答这一问题更为可行。3) 目前我们主要依赖启发式方法来选择应用LoRA的权重矩阵。是否存在更原则化的选择方法?4) 最后,∆W的秩缺陷暗示W本身也可能存在秩缺陷,这同样可以作为未来研究的灵感来源。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓















 841
841

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









