







介绍
LangChain是一个专门为利用语言模型创建应用程序而设计的全面框架。它的主要目标是帮助开发人员轻松构建基于语言模型的应用。虽然LangChain与多种语言模型兼容,但它特别与OpenAI ChatGPT无缝集成,从中受益于其先进功能。
本文学习知识点: 语言模型(LLMs)和LangChain。 提示工程。 语言模型的内存。 语言模型的链式结构。 LangChain索引。 工具和代理。
LLMs和LangChain
LLMs,即大型语言模型,是具有数十亿个参数的强大深度学习模型,在各种自然语言处理任务中表现出色。它们可以执行诸如翻译、情感分析和聊天机器人对话等任务,而无需进行特定训练。LLMs由多个神经网络层组成,包括前馈、嵌入和注意力层,共同处理输入文本并生成预测。 虽然LLMs有改变行业的潜力,但应考虑它们的限制和伦理影响。开发人员应优化这些模型,以最大程度地减少偏见并增强其实用性。LLMs可以处理的最大标记数取决于具体的实现。在LangChain中,最大标记数由所使用的底层OpenAI模型确定。为了处理超过标记限制的输入文本,可以将其拆分为较小的块并单独处理,然后再将结果组合起来。
简单使用:
from langchain.llms import OpenAI from langchain.callbacks import get_openai_callback llm = OpenAI(model_name="text-davinci-003", n=2, best_of=2) with get_openai_callback() as cb: result = llm("Tell me a joke") print(cb)
输出:
Tokens Used: 48 Prompt Tokens: 4 Completion Tokens: 44 Successful Requests: 1 Total Cost (USD): $0.00096
尽管LangChain与OpenAI LLMs协同工作非常顺畅,但它也可以与其他LLMs一起使用。我们将看一下Hugging Face托管的一个名为’google/flan-t5-large’的LLM。
from langchain import HuggingFaceHub, LLMChain # initialize Hub LLM hub_llm = HuggingFaceHub( repo_id='google/flan-t5-large', model_kwargs={'temperature':0} ) # create prompt template > LLM chain llm_chain = LLMChain( prompt=prompt, llm=hub_llm ) print(llm_chain.run(question))
输出
paris
基于OpenAI ChatGPT的gpt-3.5-turbo模型的示例。
from langchain.chat_models import ChatOpenAI from langchain.chains import LLMChain from langchain.prompts import PromptTemplate llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0) summarization_template = "Summarize the following text to one sentence: {text}" summarization_prompt = PromptTemplate(input_variables=["text"], template=summarization_template) summarization_chain = LLMChain(llm=llm, prompt=summarization_prompt) text = "LangChain provides many modules that can be used to build language model applications. Modules can be combined to create more complex applications, or be used individually for simple applications. The most basic building block of LangChain is calling an LLM on some input. Let’s walk through a simple example of how to do this. For this purpose, let’s pretend we are building a service that generates a company name based on what the company makes." summarized_text = summarization_chain.predict(text=text) summarized_text
输出
'LangChain offers various modules for building language model applications, allowing users to combine them for more complex applications or use them individually for simpler ones, with the basic building block being calling an LLM on input, as demonstrated in the example of creating a company name based on its product.'
提示工程(Prompt Engineering)
提示工程(Prompt Engineering)是在使用大型语言模型时必须掌握的关键方面。通过精心设计适当的提示,即使使用较弱或开源模型,也可以达到可比较的准确性水平。
角色提示(Role prompting)涉及指示LLM在执行任务时扮演特定的角色或身份。例如,可以要求它扮演一个文案撰稿人的角色。这种方法通过提供上下文或观点来引导模型的回应。为了有效地利用角色提示,可以按照以下迭代步骤进行操作:
-
1.在提示中明确指定所需的角色,例如:“作为一个文案撰稿人,为AWS服务生成引人注目的口号。”
-
2.利用提示从LLM生成输出。
-
3.分析生成的回应,并根据需要改进提示以提升结果的质量。
from langchain import PromptTemplate, LLMChain from langchain.llms import OpenAI # Before executing the following code, make sure to have # your OpenAI key saved in the “OPENAI_API_KEY” environment variable. # Initialize LLM llm = OpenAI(model_name="text-davinci-003", temperature=0) template = """ As a futuristic robot band conductor, I need you to help me come up with a song title. What's a cool song title for a song about {theme} in the year {year}? """ # prompt template prompt = PromptTemplate( input_variables=["theme", "year"], template=template, ) llm = OpenAI(model_name="text-davinci-003", temperature=0) input_data = {"theme": "interstellar travel", "year": "3030"} chain = LLMChain(llm=llm, prompt=prompt) response = chain.run(input_data) print("Theme: interstellar travel") print("Year: 3030") print("AI-generated song title:", response)
输出
Theme: interstellar travel Year: 3030 AI-generated song title: "Journey to the Stars: 3030"
LLMs 内存
在聊天机器人应用的动态领域中,保留消息历史在提供上下文相关的回应以增强用户体验方面起着关键作用。LangChain的ConversationChain包括一种基本形式的内存,它保留了过去的所有输入和输出,并将它们融入当前的上下文中。这可以被视为一种短期记忆。LangChain提供了多种类型的内存链,包括ConversationBufferMemory(对话缓冲内存)、ConversationBufferWindowMemory(对话缓冲窗口内存)、ConversationTokenBufferMemory(对话标记缓冲内存)和ConversationSummaryMemory(对话摘要内存)。
通过使用这些内存链,LangChain能够在对话过程中跟踪和保留消息的历史,使得模型可以根据之前的对话内容和用户交互生成更具上下文相关的响应。这样的内存机制提高了对话的连贯性和个性化,从而提升用户体验。
llm = ChatOpenAI(temperature=0.0) memory = ConversationBufferMemory() conversation = ConversationChain( llm=llm, memory = memory, verbose=True ) print(conversation.predict(input="Hi, my name is Andrew")) print(conversation.predict(input="What is 1+1?")) print(conversation.predict(input="What is my name?"))
输出
Hello Andrew! It's nice to meet you. How can I assist you today? 1+1 is equal to 2. Your name is Andrew.
在上面的对话中,LLM能够记住之前的对话,并为第三次对话提供准确的回答。这得益于LangChain的内存机制,特别是ConversationChain。ConversationChain保留了过去的输入和输出,并将它们整合到当前的上下文中。这使得LLM能够根据之前的对话内容和用户交互生成更准确、更具上下文的回答。
通过ConversationChain的内存功能,LLM可以回顾之前的对话历史,并将其作为参考来理解当前的问题并生成相关的回答。这样的记忆机制有助于提供连贯的对话体验,并确保LLM在整个对话过程中能够保持准确性和一致性。
print(memory.buffer)
输出
Human: Hi, my name is Andrew AI: Hello Andrew! It's nice to meet you. How can I assist you today? Human: What is 1+1? AI: 1+1 is equal to 2. Human: What is my name? AI: Your name is Andrew.
LLMs的链式结构
LangChain中的链式结构旨在建立一个全面的流程,以利用语言模型。它们集成了模型、提示、内存、解析输出和调试功能,提供了用户友好的界面。一个链式结构执行以下步骤:1)接收用户的查询作为输入,2)处理语言模型的响应,3)将输出返回给用户。
链式结构的类型包括:
-
LLMChain:LLMChain是使用单个语言模型的链式结构。它接收用户的查询,将其发送给语言模型进行处理,并将模型生成的响应返回给用户。
-
Sequential Chains(SimpleSequentialChain和SequentialChain):这些是顺序执行的链式结构,可以按照特定的顺序连接多个处理组件。例如,SimpleSequentialChain可能包括一个提示组件、一个语言模型组件和一个输出解析组件,依次进行处理。
-
Router Chain:路由链是一种根据条件将查询路由到不同的子链的结构。它根据一些规则或条件决定将查询发送到哪个子链进行处理,并返回子链处理的结果。
通过这些链式结构,LangChain能够组织和管理对语言模型的查询和响应流程,提供更灵活、可扩展的应用开发方式,并为用户提供更好的交互体验。
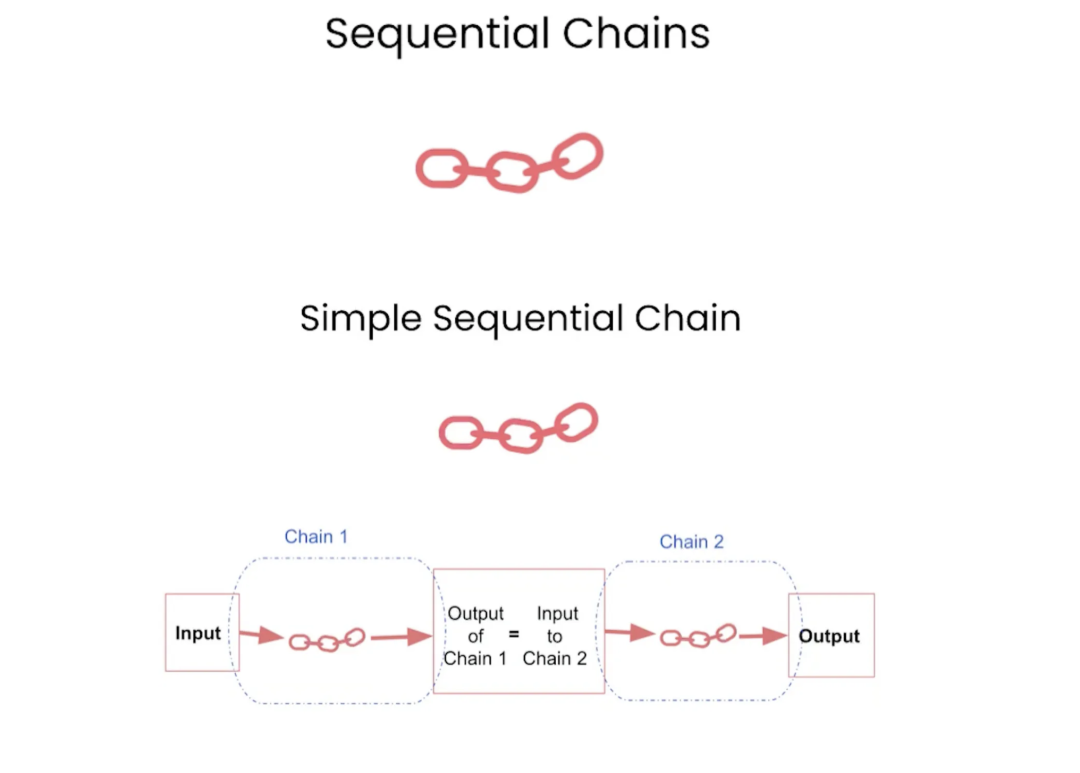
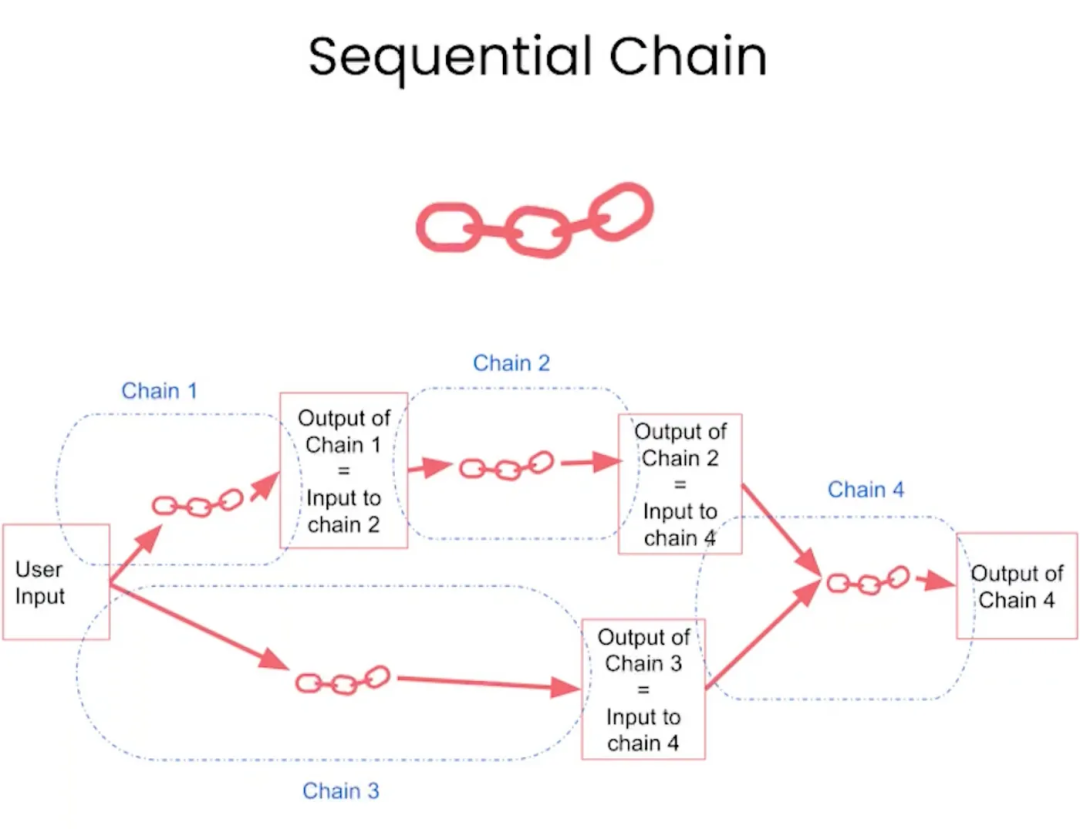
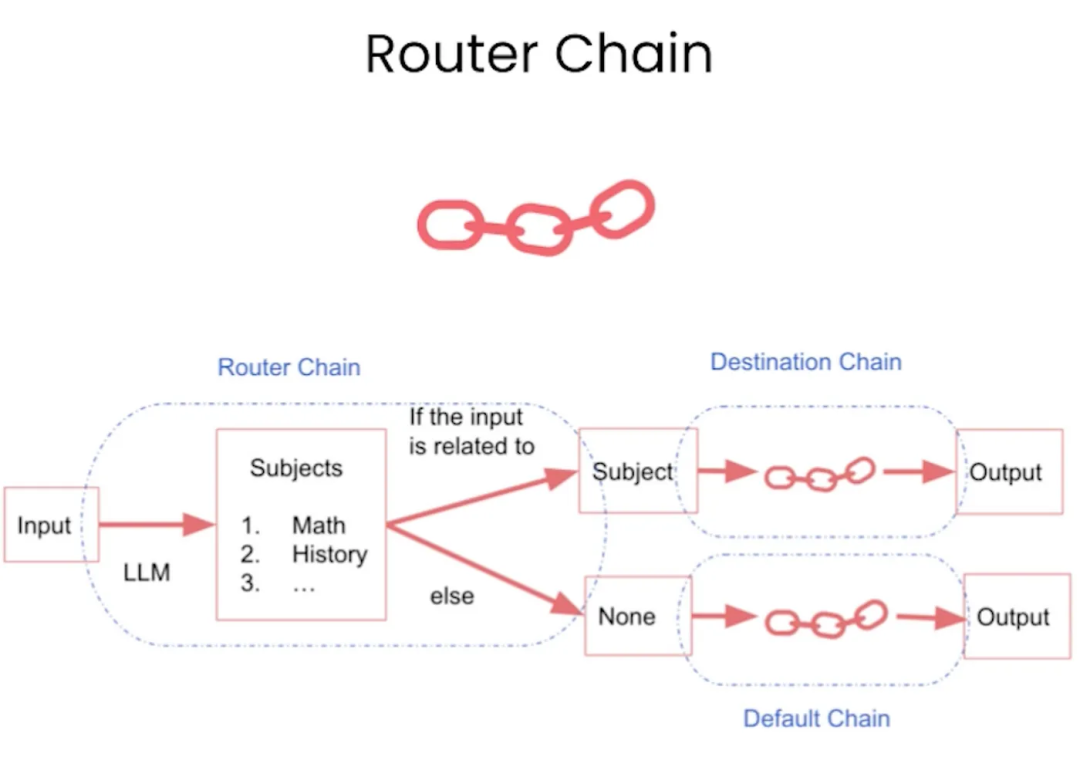
这是一个用于SimpleSequentialChain的示例代码:
from langchain.chat_models import ChatOpenAI from langchain.prompts import ChatPromptTemplate from langchain.chains import SimpleSequentialChain llm = ChatOpenAI(temperature=0.9) # prompt template 1 first_prompt = ChatPromptTemplate.from_template( "What is the best name to describe \ a company that makes {product}?" ) # Chain 1 chain_one = LLMChain(llm=llm, prompt=first_prompt) # prompt template 2 second_prompt = ChatPromptTemplate.from_template( "Write a 20 words description for the following \ company:{company_name}" ) # chain 2 chain_two = LLMChain(llm=llm, prompt=second_prompt) overall_simple_chain = SimpleSequentialChain(chains=[chain_one, chain_two], verbose=True ) overall_simple_chain.run(product)
LangChain索引
无论选择了哪种模型或使用了哪种提示表达方式,语言模型本身都具有一些无法通过我们所学的技术来克服的局限性。这些模型有一个训练截断点,这意味着它们无法获得实时新闻和最新的更新。因此,这些模型提供的回应可能不总是事实准确的,有可能包含虚构的信息。
在LangChain中,索引和检索器在组织和检索语言模型相关数据方面起着关键作用。索引是高效存储和组织文档的强大数据结构,用于快速搜索;而检索器利用这些索引,在用户查询时定位和检索相关文档。在LangChain中,主要的索引类型是基于向量数据库的,其中基于嵌入向量的索引是最常见的方法。
下面的图片展示了从向量数据库中读取索引的过程。(图片来源:deeplearning.ai)

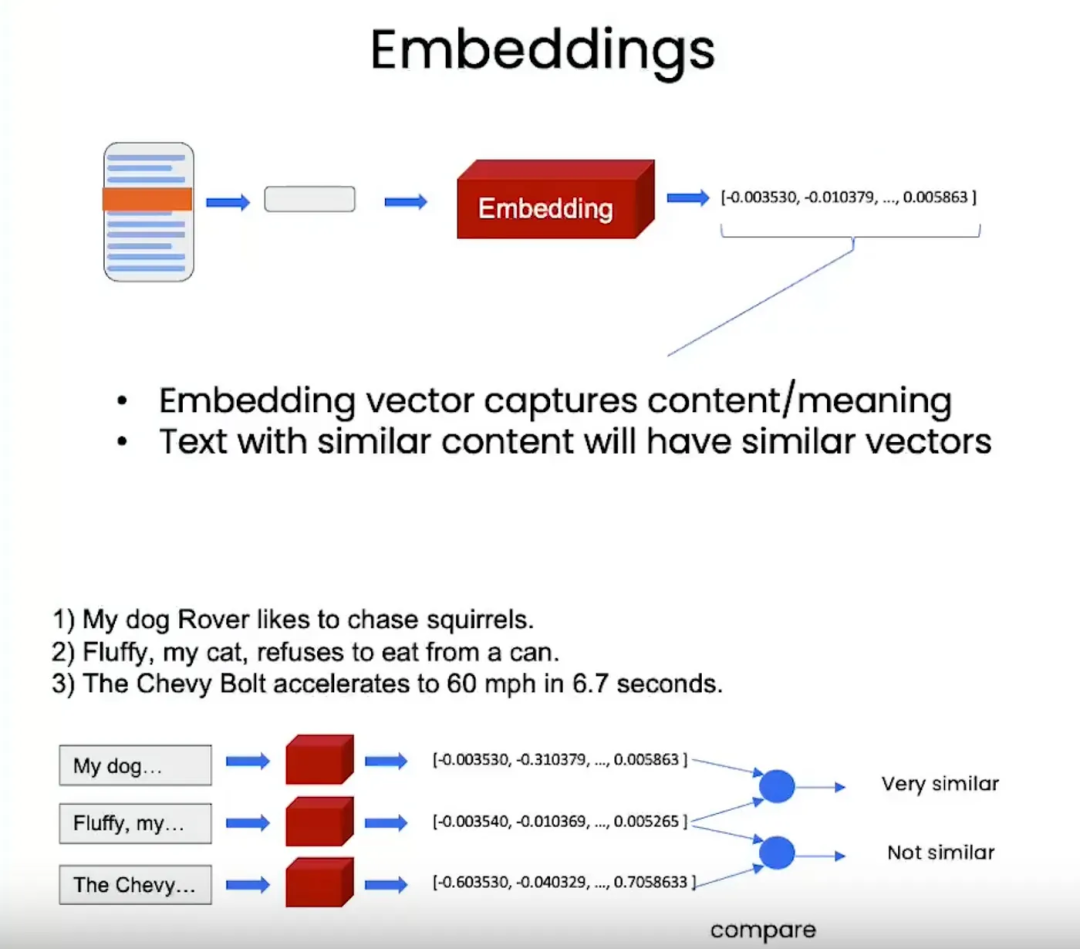
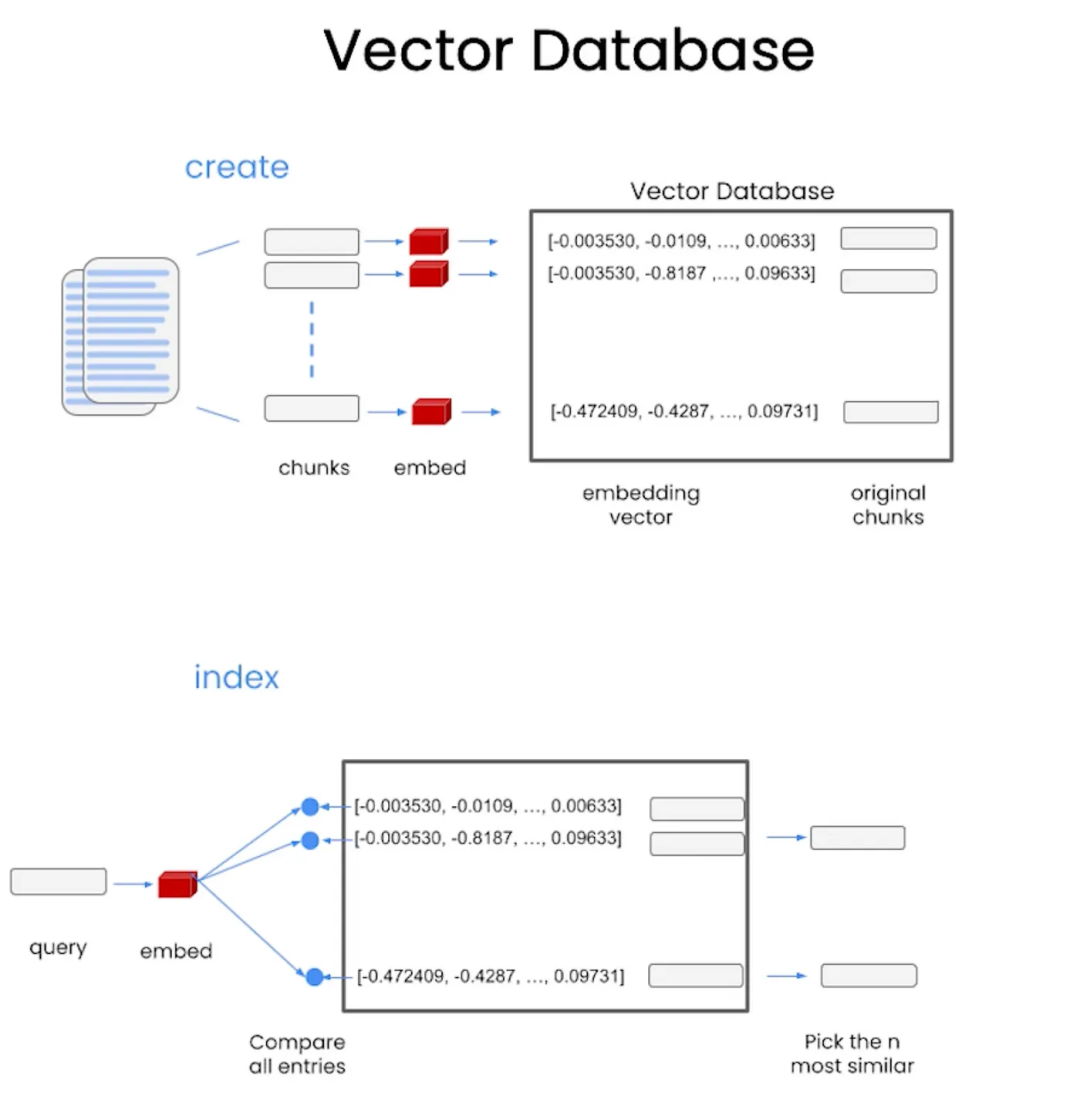
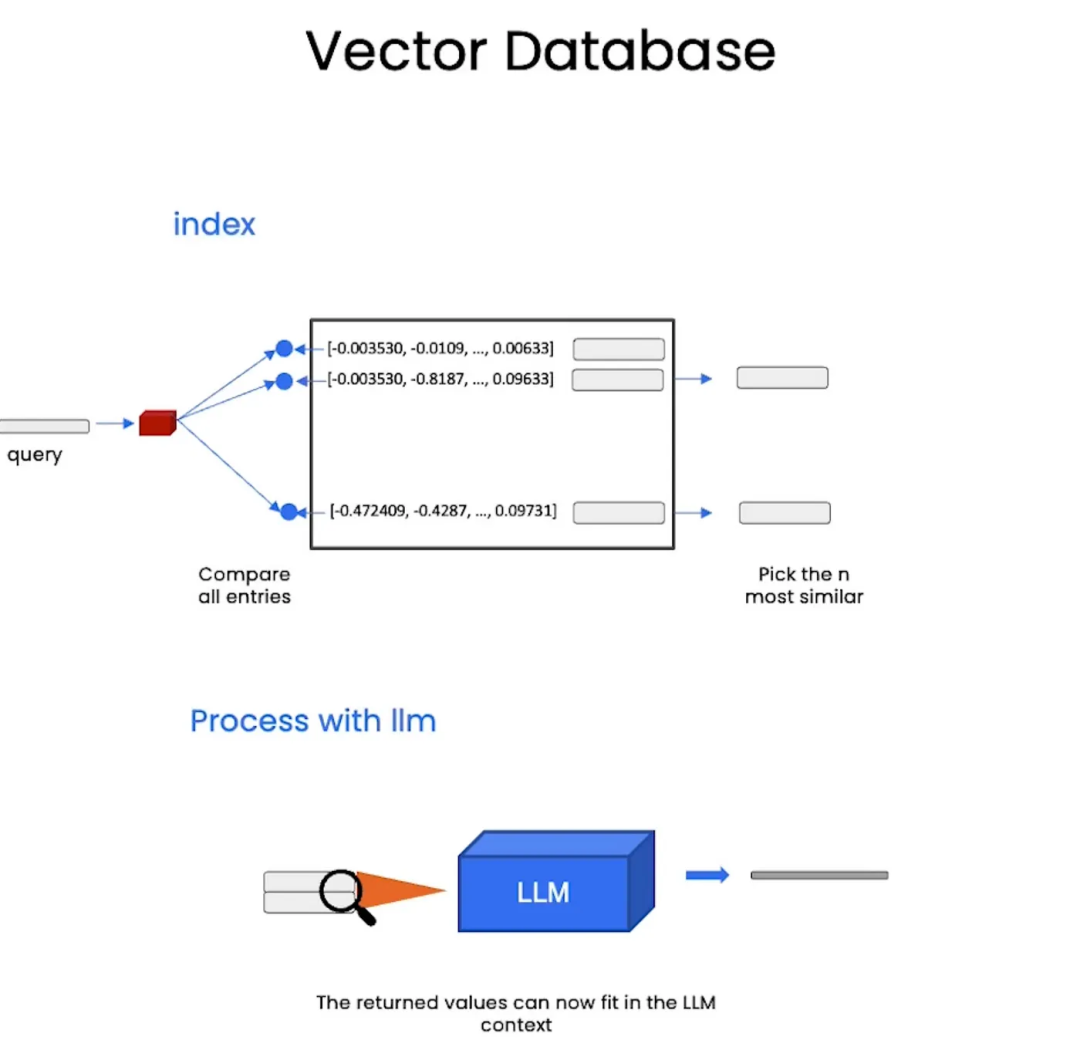
面是一个读取词嵌入(word embeddings)的示例:
from langchain.chains import RetrievalQA from langchain.chat_models import ChatOpenAI from langchain.document_loaders import CSVLoader from langchain.vectorstores import DocArrayInMemorySearch from langchain.indexes import VectorstoreIndexCreator file = 'csv_file.csv' loader = CSVLoader(file_path=file) index = VectorstoreIndexCreator( vectorstore_cls=DocArrayInMemorySearch ).from_loaders([loader]) query ="Please list all your shirts with sun protection \ in a table in markdown and summarize each one." response = index.query(query) loader = CSVLoader(file_path=file) docs = loader.load() from langchain.embeddings import OpenAIEmbeddings embeddings = OpenAIEmbeddings() embed = embeddings.embed_query("Hi my name is Harrison") print(embed[:5])
输出
[-0.021913960576057434, 0.006774206645786762, -0.018190348520874977, -0.039148248732089996, -0.014089343138039112]
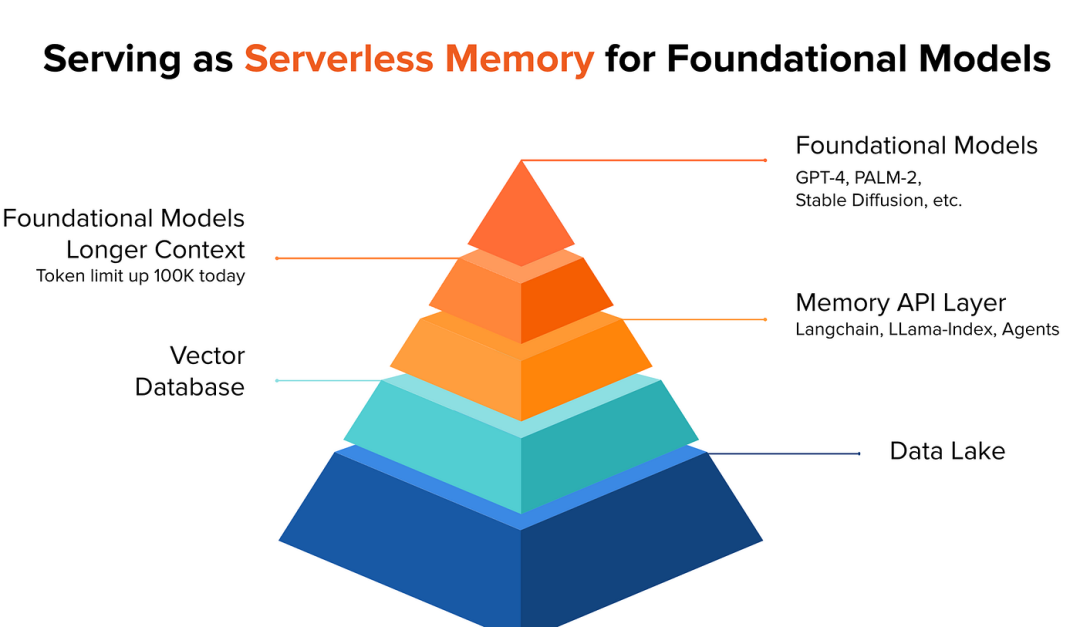
下面是一个来自Data Lake Serverless Vector Database的示例:
from langchain.document_loaders import TextLoader # text to write to a local file # taken from https://www.theverge.com/2023/3/14/23639313/google-ai-language-model-palm-api-challenge-openai text = """Google opens up its AI language model PaLM to challenge OpenAI and GPT-3 Google is offering developers access to one of its most advanced AI language models: PaLM. The search giant is launching an API for PaLM alongside a number of AI enterprise tools it says will help businesses “generate text, images, code, videos, audio, and more from simple natural language prompts.” PaLM is a large language model, or LLM, similar to the GPT series created by OpenAI or Meta’s LLaMA family of models. Google first announced PaLM in April 2022. Like other LLMs, PaLM is a flexible system that can potentially carry out all sorts of text generation and editing tasks. You could train PaLM to be a conversational chatbot like ChatGPT, for example, or you could use it for tasks like summarizing text or even writing code. (It’s similar to features Google also announced today for its Workspace apps like Google Docs and Gmail.) """ # write text to local file with open("my_file.txt", "w") as file: file.write(text) # use TextLoader to load text from local file loader = TextLoader("my_file.txt") docs_from_file = loader.load() from langchain.text_splitter import CharacterTextSplitter # create a text splitter text_splitter = CharacterTextSplitter(chunk_size=200, chunk_overlap=20) # split documents into chunks docs = text_splitter.split_documents(docs_from_file) from langchain.embeddings import OpenAIEmbeddings embeddings = OpenAIEmbeddings(model="text-embedding-ada-002") from langchain.vectorstores import DeepLake my_activeloop_org_id = "<YOUR-ACTIVELOOP-ORG-ID>" my_activeloop_dataset_name = "langchain_course_indexers_retrievers" dataset_path = f"hub://{my_activeloop_org_id}/{my_activeloop_dataset_name}" db = DeepLake(dataset_path=dataset_path, embedding_function=embeddings) # add documents to our Deep Lake dataset db.add_documents(docs) # create retriever from db retriever = db.as_retriever() from langchain.chains import RetrievalQA from langchain.llms import OpenAI # create a retrieval chain qa_chain = RetrievalQA.from_chain_type( llm=OpenAI(model="text-davinci-003"), chain_type="stuff", retriever=retriever ) query = "How Google plans to challenge OpenAI?" response = qa_chain.run(query) print(response)
输出
Google plans to challenge OpenAI by offering access to its AI language model PaLM, which is similar to OpenAI's GPT series and Meta's LLaMA family of models. PaLM is a large language model that can be used for tasks like summarizing text or writing code.
工具和代理
LangChain提供了各种工具和代理,用于帮助用户在应对挑战和生成有意义的回答时提高效率和便捷性。通过无缝集成这些工具,用户可以访问各种功能和信息源,以解决问题和提供不同类型的答案。LangChain中一些重要的工具示例包括Google搜索、Requests、Python REPL、Wikipedia和Wolfram Alpha。
代理是根据自然语言指令行动的机器人,可以利用工具来回答查询。它们确定要采取的操作顺序,可能涉及使用工具或向用户提供回答。有效使用代理可以发挥强大的作用,因为它们可以根据用户输入动态调用链条。在LangChain中创建代理时,可以使用initialize_agent函数和load_tools函数来准备代理可用的工具。
LangChain中的代理在根据用户输入进行决策和任务执行方面起着重要作用。它们评估情况并确定要使用的适当工具。LangChain提供了两类主要的代理:执行单个动作的“Action Agents”,适用于简单的任务;以及制定包含多个动作并按顺序执行的“Plan-and-Execute Agents”,适用于复杂或长时间运行的任务。
以下示例中,我们将使用Google搜索作为工具来查找Ashes系列赛事的最新摘要。(在撰写这篇文章时,我正在积极关注Ashes系列赛事)
from langchain.llms import OpenAI from langchain.agents import AgentType from langchain.agents import load_tools from langchain.agents import initialize_agent from langchain.agents import Tool from langchain.utilities import GoogleSearchAPIWrapper llm = OpenAI(model="text-davinci-003", temperature=0) os.environ["GOOGLE_API_KEY"]= "<GOOGLE_API_KEY>" os.environ["GOOGLE_CSE_ID"] = "<GOOGLE_CSE_ID>" search = GoogleSearchAPIWrapper() tools = [ Tool( name = "google-search", func=search.run, description="useful for when you need to search google to answer questions about current events" ) ] agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True, max_iterations=6) response = agent("latest status on ashes series") print(response['output'])
输出
> Finished chain. The 2021–22 Ashes series, named the Vodafone Men's Ashes Series for sponsorship reasons, is scheduled to take place in England from 8 July to 7 September 2023. Australia last won an Ashes series in England in 2001 and the current series is scheduled to take place from 8 July to 7 September 2023. The ESPNcricinfo app has an all-new native experience on match score screens and an exciting new feature 'Fantasy Cheatsheet' to help you win your fantasy games. The 2023 Ashes series is sure to be a highly anticipated event for cricket fans worldwide.
进一步阅读
随着ChatGPT和LangChain引起的激动,这个领域出现了许多令人振奋的项目和发展。以下是一些链接,可供探索这些令人兴奋的创新项目:
-
CAMEL : https://www.camel-ai.org/
-
Deep Lake: https://python.langchain.com/docs/modules/data_connection/vectorstores/integrations/deeplake
-
AgentGPT : https://github.com/reworkd/AgentGPT
-
AutoGPT : https://www.lesswrong.com/posts/566kBoPi76t8KAkoD/on-autogpt
-
https://github.com/yoheinakajima/babyagi/blob/main/docs/inspired-projects.md
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓















 5779
5779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









