









总述:
我觉得这篇论文的主要亮点就是不要标注数据。之前赵天成的zero-shot虽然很惊艳,但是迫于每一句话都需要标注dialogu action,所以应用性不强。这篇论文就是结合了赵天成之前的两篇工作,第一个zero-shot,第二个laed(用于在大规模数据中学习找到对话潜在的latent action)。然后作者就认为,在大规模无标签对话中用laed学习可以学到隐式的dialog action。
主要模型:

右图是他的主要模型,上面部分就是说其实就是训练了LAED和部分的ZSDG(只含有dialogue context部分),然后把它们的hidden连接起来,去生成。主要公式如下。k是表示融合了一些外部知识,c是对话上文的历史,d是domain,模型的外部知识片段就直接连在对话历史后面了(又是玄学操作)。

然后他的loss就只有ZSDGloss的一部分,也就是:
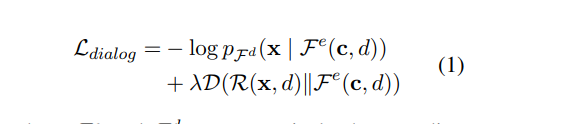
主要的训练过程:先用大规模无标注数据训练LAED,然后再target domain里面随机选取一些(1%--10%)对话作为seed data,然后这些seed对话经过LAED之后的hidden就相当于ZSDG里面的dialog action了。(话说,感觉这个过程不太靠谱,这不直接把测试集的答案告诉LAED了吗?还要训练吗QAQ)
一句话总结:
在ZHAO的两篇工作的基础上,融合了外部知识,通过LAED预训练大规模数据用来代替数据的标注,在不需要数据标注的情况下实现了few-shot dialogue生成的最好效果。















 691
691











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









