







写在前面
这篇文章看到多方评价都说效果很好,是
Abstract
1、提出一个模拟 ISP 处理的模型(模型是怎么构建的?)
2、在 RAW、sRGB 域都能生成图像对,都能做去噪。(它说在真是图像基准数据集上有 SOTA 效果,不会是 DND 吧)
3、参数量是之前的RAW去噪最佳方法(用的什么方法?)参数的 1/5
1、Introduction
(要长脑子了)
高层视觉问题:图像分类、目标检测、目标分割
底层视觉问题:图像去噪、超分、去模糊
本文工作是什么?
想在 raw 图上叠加噪声
raw 噪声和信号相关,去马赛克后和空间色彩相关,ISP走完噪声可能不再满足高斯分布
Unprocessing 的不足:需要目标相机设备的先验信息(CCM颜色校正矩阵、白平衡增益)——这就意味着需要一个事先调好的ISP欸!泛化性不足,不推荐使用。
看看白平衡增益的代码,这个用了什么参数
本模型厉害的是:不需要相机参数先验,实现sRGB和raw的转换
本文贡献
1、建立 CycleISP 模型,可实现 sRGB 和 RAW 的变换(听起来取代了 ISP 流程)
2、真实图像噪声合成器,可获得图像对
3、双重注意力机制CNN,在CycleISP、合成图像噪声、去噪中都有应用
4、在 DND、SIDD 数据集上 SOTA ,网络参数大大减少,只有 2.6M
2、RelatedWork
pass now
莫林的思考
1、模型用什么数据进行训练?
2、模型训练好之后,用什么数据进行测试?
3、CycleISP
真实的噪声数据集是人工合成的!
看懂网络结构设计思路(暂缓,等论文复现需要了解实现细节再看
多个 branch:RGB2RAW、RAW2RGB、RAW2RGB 中有颜色校正网络、叠加噪声模块(ON/OFF)
训练方式:RGB2RAW、RAW2RGB分开训练,然后联合微调
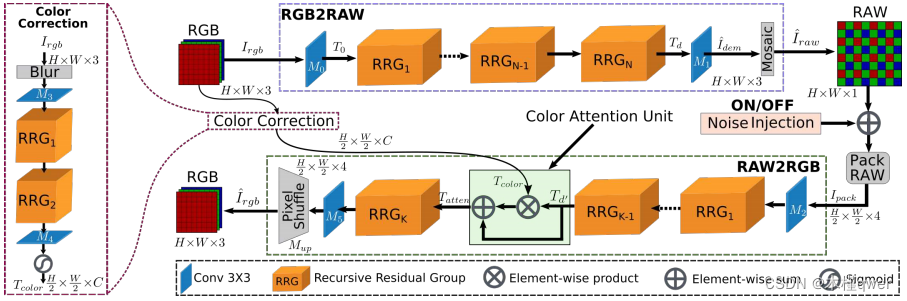

这是前文提到的双重注意力机制 CNN
3.1 RGB2RAW
Unprocessing 中也有从 RGB2RAW的部分,如下图所示,阅读代码发现:进行 Unprocessing 需要已知相机参数。
哪些参数来着?——忘记了,手头没有代码,暂时不深入看,但是我记得它需要相机参数信息。

那本文实现 RGB2RAW 的训练数据是什么?为什么它不需要相机的参数信息?后面做去噪用的又是什么数据呢?
仔细阅读论文,作者只是给出了模型架构方式,不讲上述核心信息。——没有这些信息模型训练不起来啊!
通过论文代码进行反向分析
1、作者训练得到了 RGB2RAW 的合理权重(TBD),用这个权重去对新输入的 RGB 数据生成 RAW 图。
RGB 域的去噪作者是如何实现的?
4、Synthetic Realistic Noise Data Generation 合成的真实噪声数据生成方式
叠加人为生成的噪声:add shot、read noise——移植了 Unprocessing 代码
如何对模型进行微调:用 SIDD 的数据,叠加真实噪声
5、Denoising Architecture
pass
6、Experiments
暂缓
文章实现思路总结
大概想清楚了模型的运行逻辑,从终点反向推到起点。我的两个目标及对应的解决办法
1、RGB 域去噪
目标:输入 RGB_noisy,输出 RGB_clean
1.1 模型训练一定需要用到的数据:RGB_clean、RAW_clean
1.2 模型训练要得到的东西:RGB2RAW 的权重、 RAW2RGB 的权重
1.3 对 RAW_clean 人为添加噪声,并经过 RAW2RGB 获得 RGB_noisy
1.4 用 RGB_clean 和 RGB_noisy 训练得到 RGB 域去噪的模型权重
1.5 用真实的 RGB 域噪声图验证上述去噪模型效果好坏。
2、RAW 域去噪
目标:输入 RAW_noisy,输出 RAW_clean
2.1 模型训练一定需要用到的数据:RGB_clean、RAW_clean
2.2 模型训练要得到的东西:RGB2RAW 的权重、 RAW2RGB 的权重
2.3 对 RAW_clean 人为添加噪声,获得 RAW_noisy
2.4 用 RAW_clean 和 RAW_noisy 训练得到 RAW 域去噪的模型权重
2.5 用真实的 RAW 域噪声图验证上述去噪模型效果好坏,大概率经过 RAW2RGB 的处理,在 RGB 域看效果。
PPT要点一览
1、为什么用合成的方式做图像去噪
2、深度学习方法在真实数据上泛化性能较差
[正文摘抄] On synthetic datasets, existing deep learning based denoising models yield impressive results, but they exhibit poor generalization to real camera data as compared to conventional methods
下文是两篇综述文章的总结,补完文章以加深对这篇文章的理解

3、ISP 的 pipeline
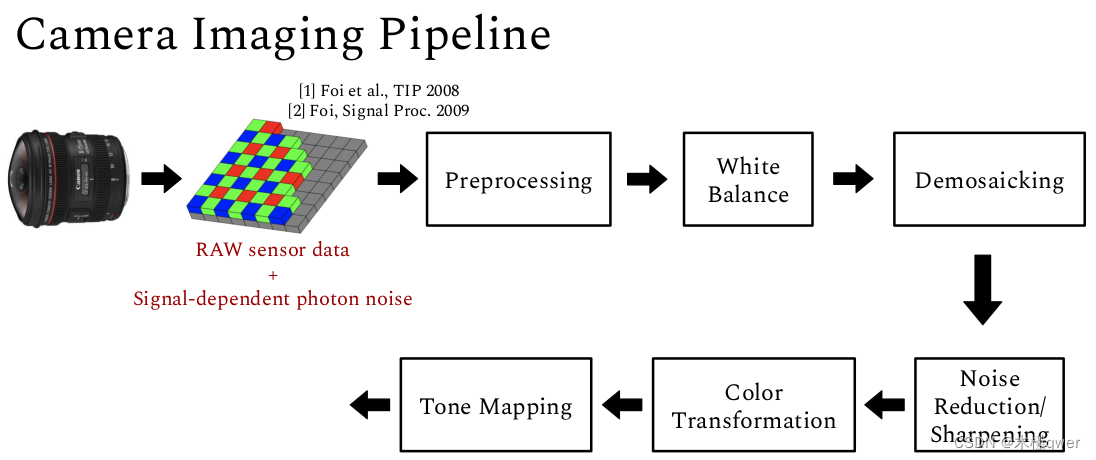
做色调映射后色彩就很丰富了。
RGB域图像噪声的特点:1、空间和色度相关2、信号相关;3、不一定是高斯
















 3318
3318











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









