






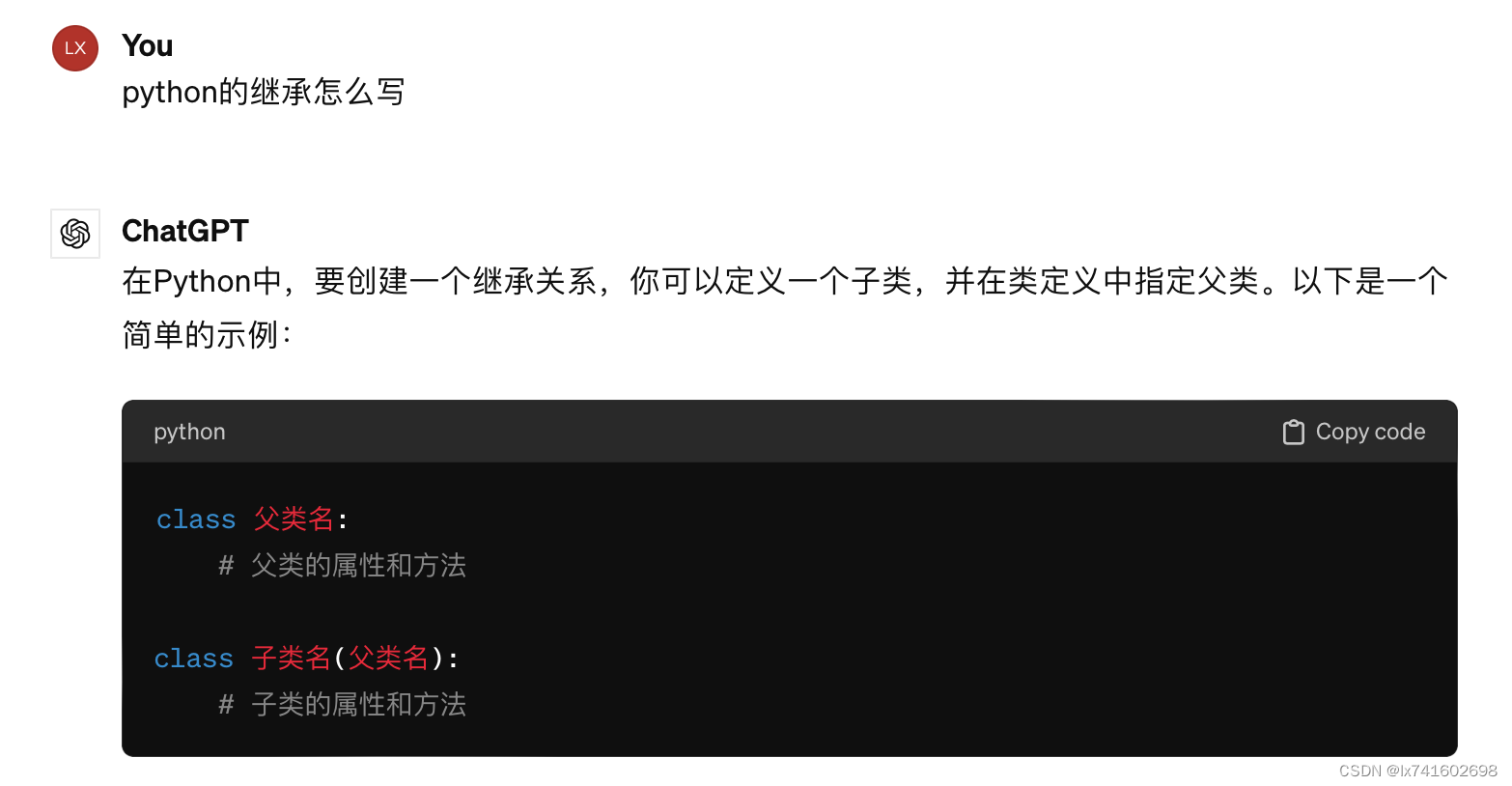
1. python的继承
2. nn.Sequential()是什么

3. nn.module类是什么
在PyTorch中,nn.Module 类是所有神经网络模块的基类。通过继承 nn.Module 类,你可以轻松地定义自己的神经网络模型。
nn.Module 类提供了许多重要的功能,包括:
- 参数管理:
nn.Module类会自动追踪所有定义在其中的参数(例如权重和偏置),并且可以通过parameters()方法来获取所有参数。 - 前向传播函数:通过重写
forward()方法,你可以定义模型的前向传播逻辑。当调用模型实例的forward()方法时,PyTorch会自动调用这个函数来计算模型的输出。 - 子模块管理:
nn.Module类支持嵌套,你可以在模型中包含其他模型作为子模块,并且这些子模块也会自动追踪参数。
以下是一个简单的示例,演示如何创建一个继承自 nn.Module 的简单神经网络类:
import torch
import torch.nn as nn
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc1 = nn.Linear(784, 128) # 输入层到隐藏层的线性变换
self.relu = nn.ReLU() # ReLU激活函数
self.fc2 = nn.Linear(128, 10) # 隐藏层到输出层的线性变换
self.softmax = nn.Softmax(dim=1) # Softmax激活函数,dim=1表示按照第一个维度计算Softmax
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
x = self.softmax(x)
return x
# 创建模型实例
model = SimpleModel()
# 打印模型结构
print(model)
4. init里面要写什么东西
在 Python 中,__init__ 方法是一个特殊的方法,用于初始化对象的属性。在 PyTorch 中,当你创建一个继承自 nn.Module 的自定义神经网络模型时,__init__ 方法通常用于初始化模型的各个层以及其他需要在整个模型中共享的属性。
在 __init__ 方法中,你通常需要完成以下任务:
-
调用父类的
__init__方法:在自定义的__init__方法中,通常需要调用父类nn.Module的__init__方法,以确保正确地初始化模型的基类部分。 -
定义模型的层:在
__init__方法中,你需要定义模型中的各个层作为类的属性。这些层包括线性层 (nn.Linear)、卷积层 (nn.Conv2d)、池化层 (nn.MaxPool2d等)、激活函数 (nn.ReLU、nn.Sigmoid、nn.Tanh等) 等等。 -
其他初始化工作:除了定义模型的层外,你可能还需要进行其他初始化工作,例如定义一些模型的超参数、初始化一些非神经网络层的属性等。
以下是一个示例 __init__ 方法,展示了一个简单的神经网络模型中可能包含的内容:
import torch.nn as nn
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc1 = nn.Linear(784, 128) # 定义输入层到隐藏层的线性变换
self.relu = nn.ReLU() # 定义ReLU激活函数
self.fc2 = nn.Linear(128, 10) # 定义隐藏层到输出层的线性变换
self.softmax = nn.Softmax(dim=1) # 定义Softmax激活函数,dim=1表示按照第一个维度计算Softmax
def forward(self, x):
# 定义模型的前向传播逻辑
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
x = self.softmax(x)
return x
5. 一个手写的迭代卷积核代码
import torch
from torch import nn
def corr2d(X, K): #@save
"""计算二维互相关运算"""
h, w = K.shape
Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i:i + h, j:j + w] * K).sum()
return Y
X = torch.ones((6, 8))
X[:, 2:6] = 0
K = torch.tensor([[1.0, -1.0]])
Y = corr2d(X, K)
# 构造一个二维卷积层,它具有1个输出通道和形状为(1,2)的卷积核
conv2d = nn.Conv2d(1,1, kernel_size=(1, 2), bias=False)
# 这个二维卷积层使用四维输入和输出格式(批量大小、通道、高度、宽度),
# 其中批量大小和通道数都为1
X = X.reshape((1, 1, 6, 8))
Y = Y.reshape((1, 1, 6, 7))
lr = 3e-2 # 学习率
for i in range(30):
Y_hat = conv2d(X)
l = (Y_hat - Y) ** 2
conv2d.zero_grad()
l.sum().backward()
# 迭代卷积核
conv2d.weight.data[:] -= lr * conv2d.weight.grad
if (i + 1) % 2 == 0:
print(Y_hat)
print(f'epoch {i+1}, loss {l.sum():.3f}')
print(Y)其中conv2d.zero_grad()是清空梯度,不清空的话,下一轮的梯度会累加上去。
在 PyTorch 中,梯度默认是会自动累加的。这意味着在调用
backward()方法计算梯度时,梯度会被添加到相应参数的.grad属性上,而不是覆盖原有的梯度值。















 1094
1094











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









